并发容器
并发容器
- ConcurrentHashMap:线程安全的HashMap
- CopyOnWriteArrayList:线程安全的List
- BlockingQueue:这是一个接口,表示阻塞队列,非常适合用于作为数据共享的通道
- ConcurrentLinkedQueue:高效的非阻塞并发队列使用链表实现。可以看做一个线程安全的LinkedList
- ConcurrentSkipListMap:是一个Map,使用跳表的数据结构进行快速查找
ArrayList和HashMap
虽然这两个类不是线程安全的,但是可以用
Collections.synchronizedList(new ArrayList<E>())和
Collections.synchronizedMap(new HashMap<K,V>0)使之变成线程安全的
ConcurrentHashMap和CopyOnWriteArrayList
- 取代同步的HashMap和同步的ArrayList
- 绝大多数并发情况下,ConcurrentHashMap和CopyOnWriteArrayList的性能都更好
Map

ConcurrentHashMap
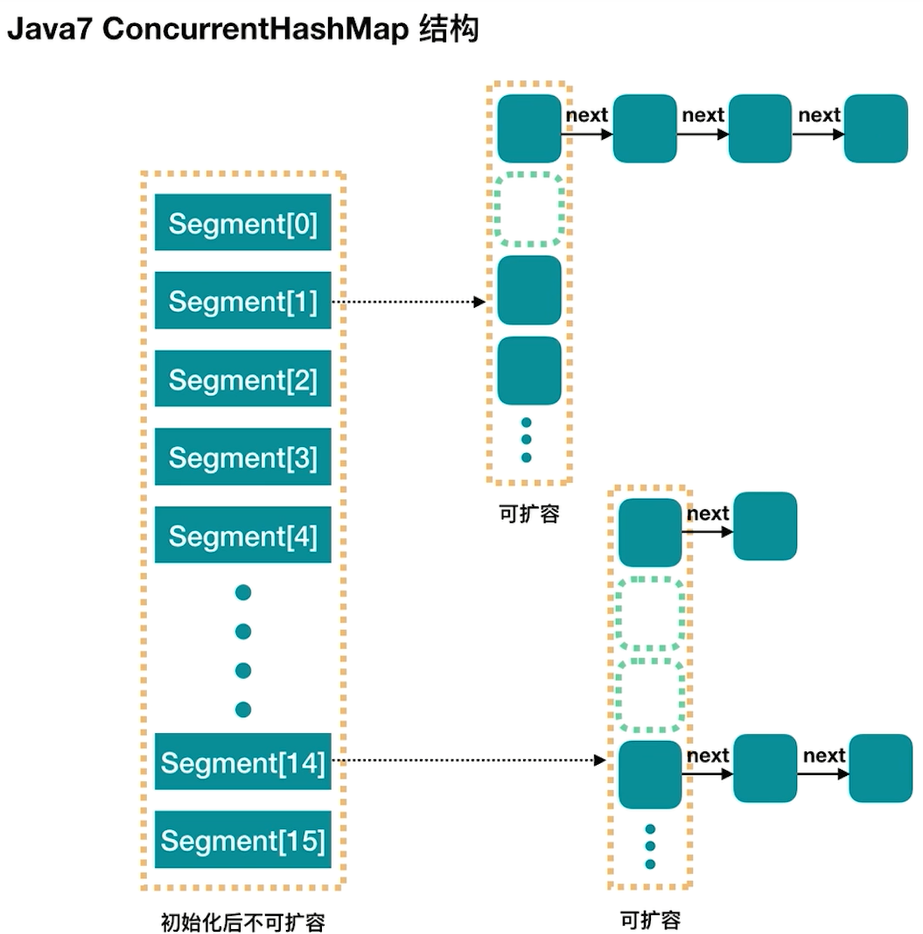
- Java7中的ConcurrentHashMap最外层是多个segment,每个segment的底层数据结构与HashMap类似,仍然是数组和链表组成的拉链法
- 每个segment独立上ReentrantLock锁,每个segment之间互不影响,提高了并发效率
- ConcurrentHashMap默认有16个Segments,所以最多可以同时支持16个线程并发写(操作分别分布在不同的Segment上)。这个默认值可以在初始化的时候设置为其他值,但是一旦初始化以后,是不可以扩容的
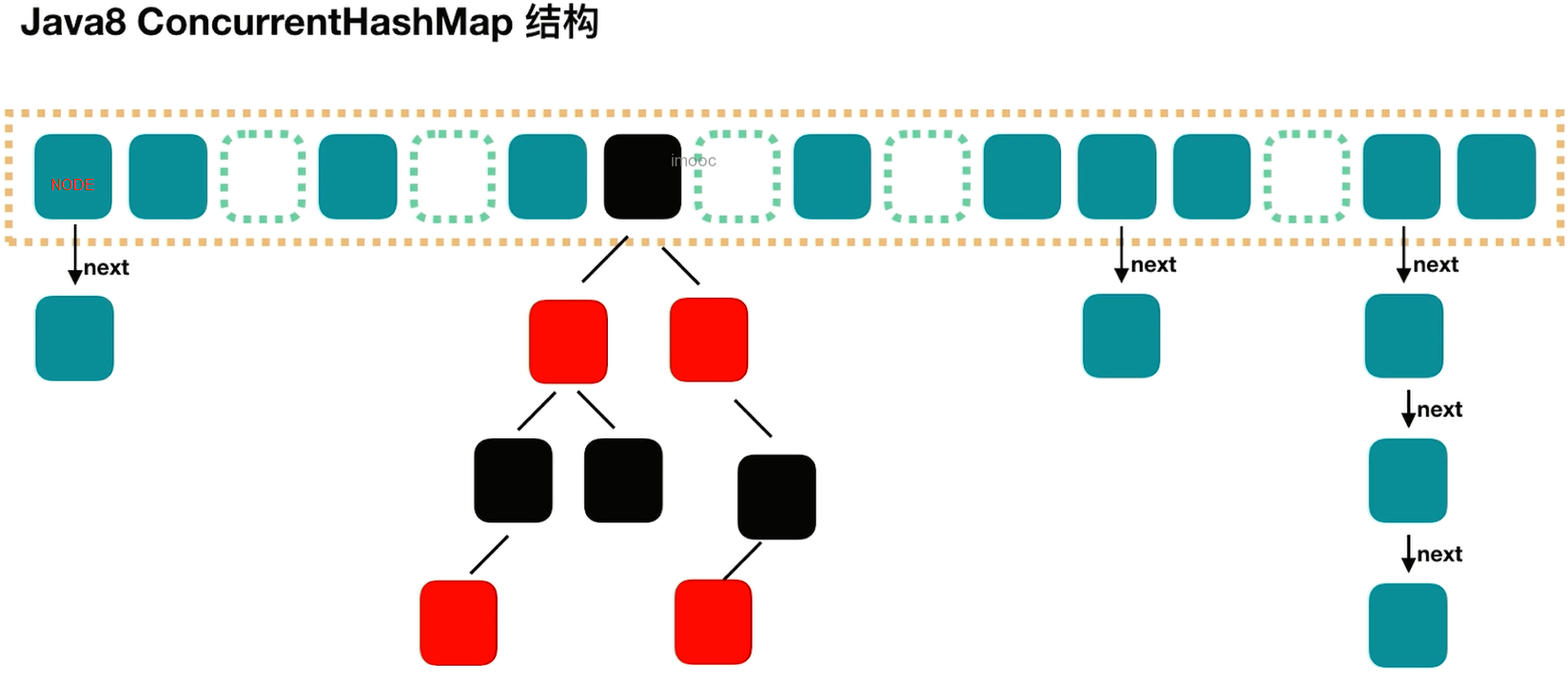
- 每个Node结点都是独立的,并发度很高。
- 使用链表方式解决hash冲突。
- 当链表的长度超过阈值8时,为了提高查询速度,将链表转换成红黑树。
线程不安全
public class OptionsNotSafe implements Runnable {
private static ConcurrentHashMap<String, Integer> scores = new ConcurrentHashMap<String, Integer>();
public static void main(String[] args) throws InterruptedException {
scores.put("小明", 0);
Thread t1 = new Thread(new OptionsNotSafe());
Thread t2 = new Thread(new OptionsNotSafe());
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println(scores);
}
@Override
public void run() {
for (int i = 0; i < 1000; i++) {
while (true) {
Integer score = scores.get("小明");
Integer newScore = score + 1;
// scores.put("小明",newScore); 线程不安全
boolean b = scores.replace("小明", score, newScore);
if (b) {
break;
}
}
}
}
}
CopyOnWriteArrayList
- 代替Vector和SynchronizedList,就和ConcurrentHashMap代替SynchronizedMap的原因一样
- Vector和SynchronizedList的锁的粒度太大,并发效率相对比较低,并且迭代时无法编辑
- Copy-On-Write并发容器还包括CopyOnWriteArraySet,用来替代同步Set
适用场景
- 读操作可以尽可能地快,而写即使慢一些也没有太大关系
- 读多写少:黑名单,每日更新;监听器:迭代操作远多余修改操作
读写规则
- 回顾读写锁:读读共享、其他都互斥(写写互斥、读写互斥、写读互斥)
- 读写锁规则的升级:读取是完全不用加锁的,并且更厉害的是写入也不会阻塞读取操作。只有写入和写入之间需要进行同步等待
缺点
- 数据一致性问题:CopyOnWrite容器只能保证数据的最终一致性,不能保证数据的实时一致性。所以如果你希望写入的数据,马上能读到,请不要使用CopyOnWrite容器。
- 内存占用问题:因为CopyOnWrite的写是复制机制,所以在进行写操作的时候,内存里会同时驻扎两个对象的内存。
并发队列(Queue)
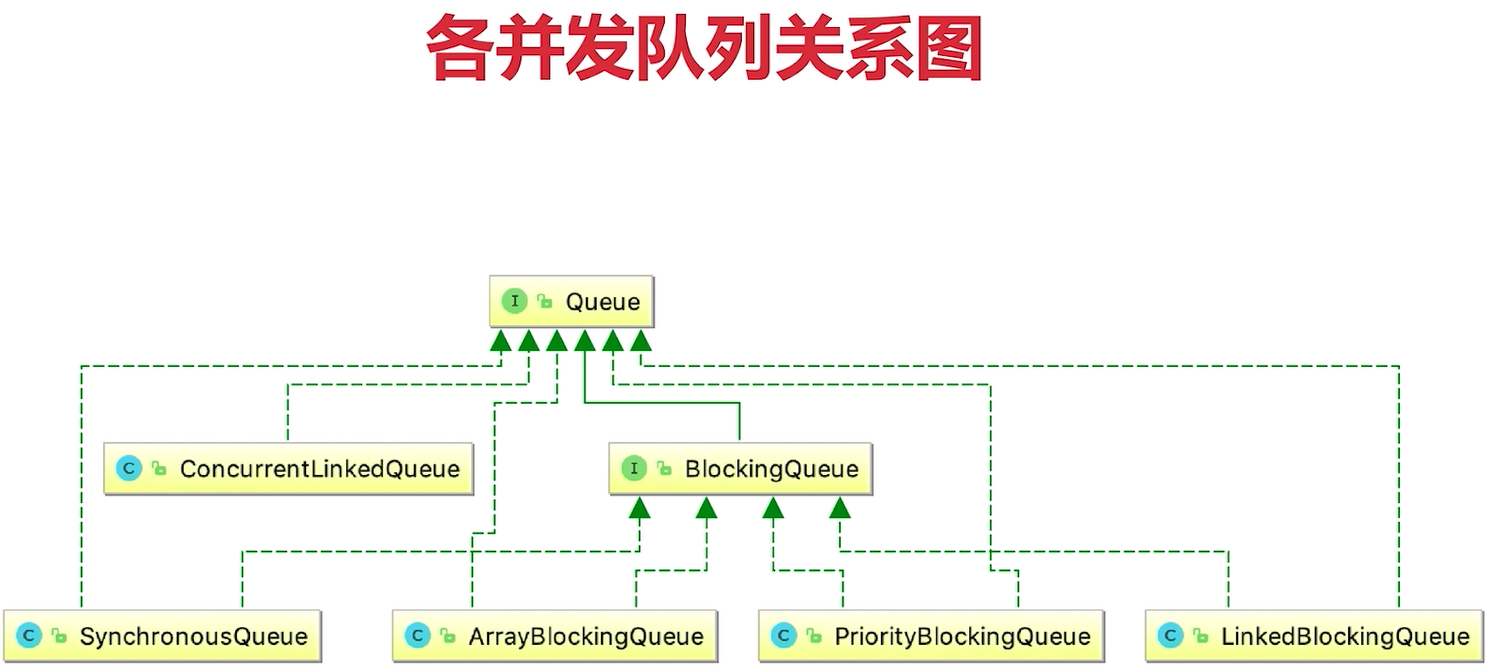
阻塞队列(BlockingQueue)
- 阻塞队列是具有阻塞功能的队列,所以它首先是一个队列其次是具有阻塞功能。
- 通常,阻塞队列的一端是给生产者放数据用,另一端给消费者拿数据用。阻塞队列是线程安全的,所以生产者和消费者都可以是多线程的

- take()方法:获取并移除队列的头结点,一旦如果执行take的时候,队列里无数据,则阻塞,直到队列里有数据
- put()方法:插入元素。但是如果队列已满,那么就无法继续插入,则阻塞,直到队列里有了空闲空间
take和put不会抛出异常,只会阻塞住
add,remove,element会抛出异常
offer,poll,peek
- 是否有界(容量有多大):这是一个非常重要的属性无界队列意味着里面可以容纳非常多(Integer.MAXVALUE,约为2的31次,是非常大的一个数,可以近似认为是无限容量)
- 阻塞队列和线程池的关系:阻塞队列是线程池的重要组成部分
ArrayBlockingQueue
- 指定容量
- 公平:指定是否需要保证公平,如果想保证公平的话那么等待了最长时间的线程会被优先处理,不过这会同时带来一定的性能损耗
LinkedBlockingQueue
- 无界
- 容量Integer.MAX_VALUE
- 内部结构:Node、两把锁。
PriorityBlockingQueue
- 支持优先级
- 自然顺序(而不是先进先出)
- 无界队列
- PriorityQueue的线程安全版本
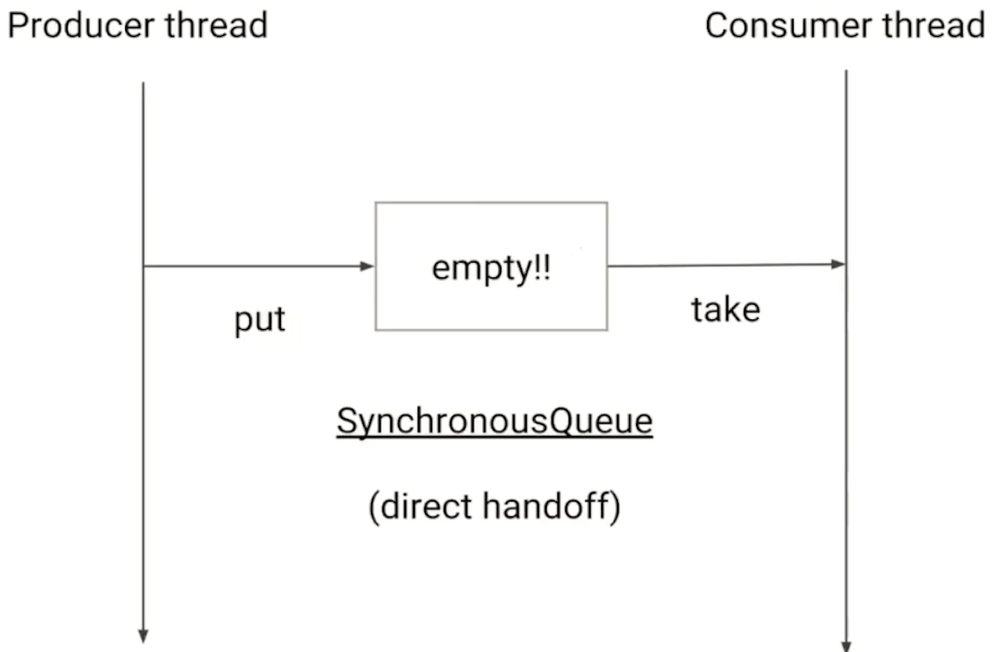
SynchronousQueue
- 它的容量为0
- 需要注意的是,SynchronousQueue的容量不是1而是0,因为SynchronousQueue不需要去持有元素,它所做的就是直接传递(direct handoff )
- 效率很高
- SynchronousQueue没有peek等函数,因为peek的含义是取出头结点,但是SynchronousQueue的容量是0,所以连头结点都没有,也就没有peek方法。同理,没有iterate相关方法
- 是一个极好的用来直接传递的并发数据结构
- SynchronousQueue是线程池Executors.newCachedThreadPool()使用的阻塞队列
DelayQueue
- 延迟队列,根据延迟时间排序
- 元素需要实现Delayed接口,规定排序规则
非阻塞并发队列
并发包中的非阻塞队列只有ConcurrentLinkedQueue这一种顾名思义ConcurrentLinkedQueue是使用链表作为其数据结构的,使用CAS非阻塞算法来实现线程安全(不具备阻塞功能),适合用在对性能要求较高的并发场景。用的相对比较少一些

 浙公网安备 33010602011771号
浙公网安备 33010602011771号