


VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION(VGG)
阅读笔记(22.10.05)
摘要:本文研究在大规模图像识别设置中卷积网络深度对其准确性的影响。主要贡献是对使用(3,3)卷积核的体系结构增加深度的网络进行全面评估,结果表明,深度推到16-19可以实现对现有技术配置的显著改进。公开了两个性能最好的卷积模型。
- 介绍:
本文讨论convNet的深度的性能,固定其他参数,卷积核(3,3)非常小可以稳步增加网络的深度。在第2节中,本文描述了ConvNet配置。然后在第3节介绍图像分类训练和评估的细节,在第4节比较ILSVRC分类任务上的配置。第五节总结了本文。
- convNet 配置
为了衡量在公平环境下增加ConvNet深度所带来的改善,ConvNet配置都使用相同的原则设计。
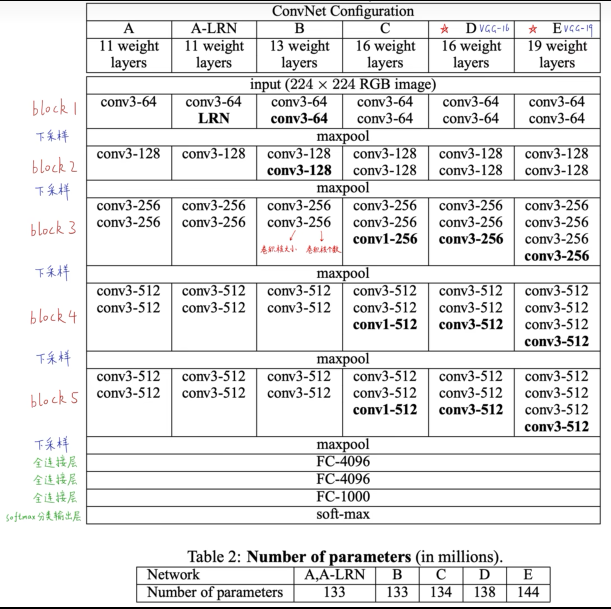
2.1结构
输入大小固定的224*224RGB图像。唯一预处理是每个像素都减去训练集中计算的平均RGB值。捕获上下左右概念的最小卷积核(3,3)。也使用了(1,1)的卷积核(看作是输入通道的线性变换(其次是非线性)),卷积步幅固定为一个像素。卷积层的输入的空间填充是为了保证卷积后的空间分辨率,即(3,3)的卷积层填充1像素。空间池化使用5个最大池化层,池化层的核为(2,2),步幅为2。卷积层的堆叠不同结构有不同的深度,但是后面的三个全连接层(FC layer)都是相同的。(前两层各有4096个通道,第三层执行1000个类的分类,最后一层是soft-max层)。全连接层的配置在所有网络中都是相同。所有隐藏层均具有非线性激活层(ReLU)。并没有使Local Response Normalisation,因为实验发现没有啥作用。
2.2配置
本文的ConvNet配置在表1,卷积层从8到16,卷积层通道数相当小第一层64,每一个最大池化层后增加2倍,直到达到512。表2报告了每个配置的参数数量。
2.3讨论:
2层3×3的感受野= 1层5×5感受野;3层3×3感受野 = 1层7×7感受野;
1×1 卷积层的加入(VGG-C,表1)是在不影响卷积层感受野的情况下,增加非线性决策函数的一种方法。
使用3*3步幅1的最小卷积核,表中为了简洁起见,没有显示ReLU激活函数。1 × 1卷积本质上是在相同维度空间上的线性投影(输入和输出通道的数量是相同的),但由于校正函数引入了额外的非线性
3. 分类框架
3.1训练:
使用带有动量的mini-batch梯度下降,批大小为256,动量设置为0.9。训练通过权值衰减核前两层全连接dropout(0.5)进行正则化。学习率设置0.01,当验证集准确率停止提高时,学习率下降10倍。学习率降低了3次,74个epoch后停止学习。在A中随机初始化权重,后面的几个网络用A的层初始化前四层核最后的全连接层,中间的采用随机初始化。随机初始化使用均值为0,方差为0.01的正态分布中抽样权重。偏差初值0。获得固定大小的RGB图像(224*224),在缩放的图像中随机裁剪(SGD即随机梯度下降法,每次SGD每张图像裁剪一次)。数据集可以随即水平翻转和随机RGB颜色转移。
结论:表示深度有利于分类精度。
本文来自博客园,作者:键盘侠牧师,转载请注明原文链接:https://www.cnblogs.com/wangzhe52xia/p/16755660.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号