
超市销售数据可视化分析
项目介绍
本项目用于大数据可视化大作业,使用超市销售额数据进行可视化分析
可视化分析
各地区总体的销售额和利润及利润率
各地区总体的销售额和利润堆叠柱形图
#堆叠柱状图显示各地区总体的销售额,利润,成本
def make_area_Bar(self):
to_drop = ['行 ID', '订单 ID', '订单日期', '发货日期', '邮寄方式', '客户 ID', '客户名称', '细分', '城市', '省/自治区', '国家',
'产品 ID', '类别','子类别','产品名称','数量','折扣']
res = self.newRows.drop(to_drop, axis=1)
# 数据统计
area_dict={}
for i in res.itertuples(): # 将DataFrame迭代为元祖。
if i[1] not in area_dict.keys():
area_dict[i[1]]=[i[2],i[3]] #新增{'华东':[129.66,-60.704]} #地区:销售额,利润
else:
list=area_dict[i[1]]
list[0]+=i[2] #销售额
list[1]+=i[3] #利润
area_dict[i[1]]=list
for k,v in area_dict.items():
list=v
list.append(list[0]-list[1]) #计算成本
area_dict[k]=list
print("========六大地区的销售额,利润,成本==============")
print(area_dict)
area = ['华东','西南','中南','西北','东北','华北']
#按照area顺序添加销售额,利润,成本
sale=[]
profit=[]
cost=[]
for k,v in area_dict.items():
sale.append(v[0])
profit.append(v[1])
cost.append(v[2])
c=Bar()
c.add_xaxis(area)
c.add_yaxis("销售额",sale)
c.add_yaxis("利润", profit, stack="stack1")
c.add_yaxis("成本", cost, stack="stack1")
c.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
c.set_global_opts(title_opts=opts.TitleOpts(title="各地区总体的销售额,利润,成本"))
c.render("各地区总体的销售额,利润,成本.html")
return c
运行结果
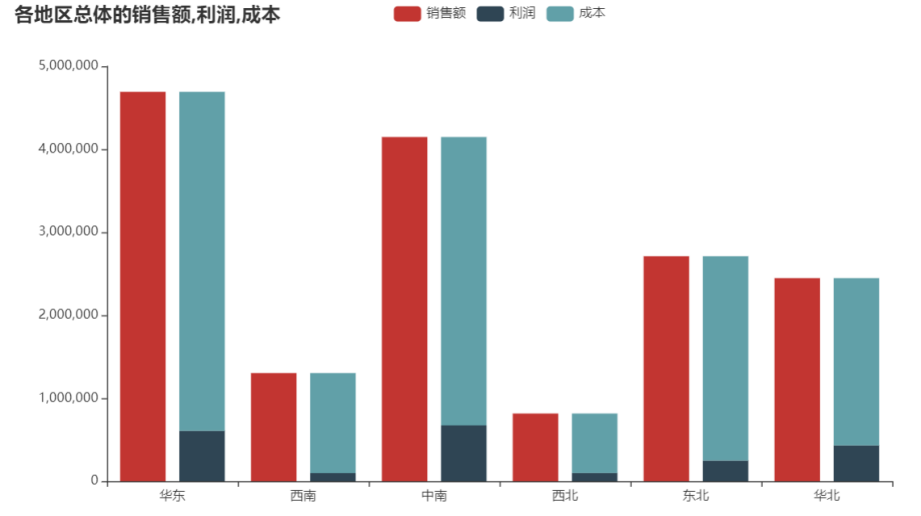
各地区总体的利润率
#堆叠柱状图显示各地区总体的销售额,利润,成本
def make_area_Bar(self):
to_drop = ['行 ID', '订单 ID', '订单日期', '发货日期', '邮寄方式', '客户 ID', '客户名称', '细分', '城市', '省/自治区', '国家',
'产品 ID', '类别','子类别','产品名称','数量','折扣']
res = self.newRows.drop(to_drop, axis=1)
# 数据统计
area_dict={}
for i in res.itertuples(): # 将DataFrame迭代为元祖。
if i[1] not in area_dict.keys():
area_dict[i[1]]=[i[2],i[3]] #新增{'华东':[129.66,-60.704]} #地区:销售额,利润
else:
list=area_dict[i[1]]
list[0]+=i[2] #销售额
list[1]+=i[3] #利润
area_dict[i[1]]=list
for k,v in area_dict.items():
list=v
#各地区总体的利润率
def make_area_pie(self):
to_drop = ['行 ID', '订单 ID', '订单日期', '发货日期', '邮寄方式', '客户 ID', '客户名称', '细分', '城市', '省/自治区', '国家',
'产品 ID', '类别', '子类别', '产品名称', '数量', '折扣']
res = self.newRows.drop(to_drop, axis=1)
# 数据统计
area_dict = {}
for i in res.itertuples(): # 将DataFrame迭代为元祖。
if i[1] not in area_dict.keys():
area_dict[i[1]] = [i[2], i[3]] # 新增{'华东':[129.66,-60.704]} #地区:销售额,利润
else:
list = area_dict[i[1]]
list[0] += i[2] # 销售额
list[1] += i[3] # 利润
area_dict[i[1]] = list
for k, v in area_dict.items():
list = v
list.append(list[0] - list[1]) # 计算成本
area_dict[k] = list
data_dict={}
for k, v in area_dict.items():
list = v
rate=list[1]/list[2]*100 #计算利润率
str="%.2f" % rate #保存两位小数
data_dict[k]=str
print("========六大地区的利润率==============")
print(data_dict)
data_list=[]
for i in data_dict.items():
data_list.append(i)
c=Pie()
c.add("", data_list, center=["40%", "55%"],)
c.set_global_opts(
title_opts=opts.TitleOpts(title="各地区利润率"),
legend_opts=opts.LegendOpts(type_="scroll", pos_left="80%", orient="vertical"),
)
c.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}%({d}%)")) #{a}(系列名称),{b}(数据名称),{c}(数值数组), {d}(无)。如下图:
# 生成html
c.render("各地区利润率.html")
return c
运行结果
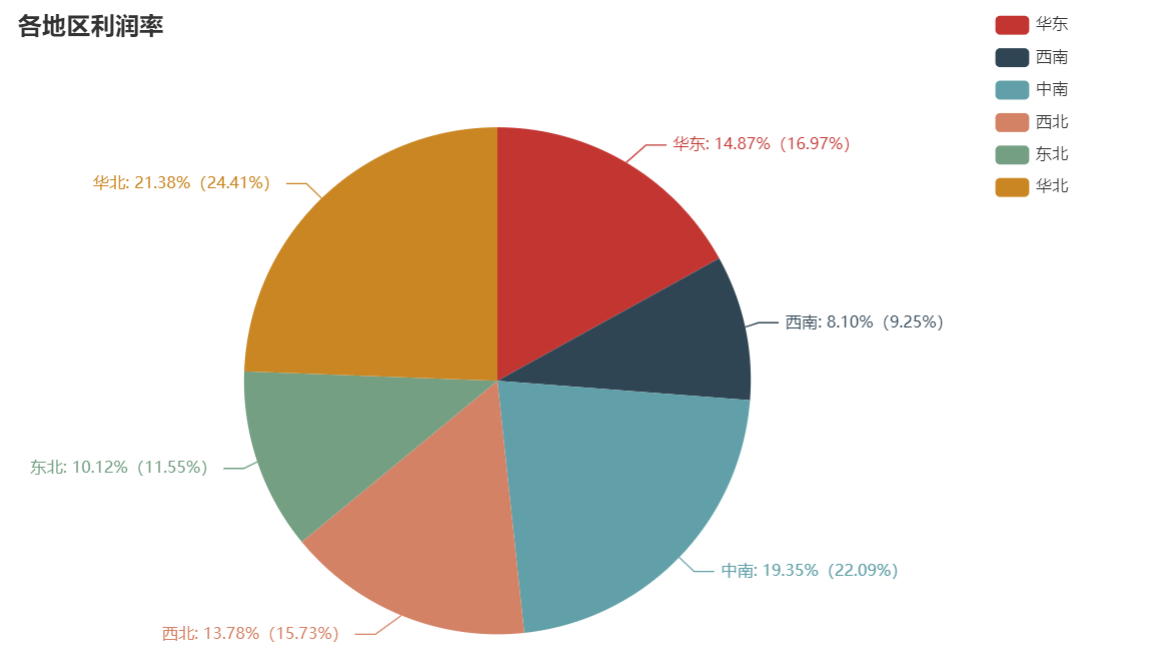
分析
通过各地区总体的销售额,利润,成本堆叠图与饼图可以看出华东地区的销售额最大为4692464.994000002,对应的成本也是最大为4085133.0800000024,而华东地区的利润(607331.9139999994)却比中南地区的利润(672494.4729999999)少。通过各地区的利润率可以看出华北地区的利润率最大约为21.38%,接着为中南地区。
各省市的销售额利润情况,有哪些省市利润存在亏损
各省利润情况
绘制各省利润情况地图
#以省展示利润亏损情况
def make_china_map(self):
to_drop = ['行 ID', '订单 ID', '订单日期', '发货日期', '邮寄方式', '地区','客户 ID', '客户名称', '细分', '城市', '国家',
'产品 ID', '类别', '子类别', '产品名称', '数量', '折扣']
res = self.newRows.drop(to_drop, axis=1)
provice_dict={}
for i in res.itertuples():
if i[1] not in provice_dict.keys():
provice_dict[i[1]]=i[3]
else:
provice_dict[i[1]] += i[3]
print("========以省展示利润情况==============")
print(provice_dict)
provice_list=[]
for k,v in provice_dict.items():
provice_list.append((k,v))
#绘制地图
c=Map()
c.add("中国地图",provice_list,"china")
c.set_global_opts(
title_opts=opts.TitleOpts(title="各省利润情况"),
visualmap_opts=opts.VisualMapOpts(max_=400000,min_=-200000),
)
c.render("各省利润情况.html")
return c
运行结果
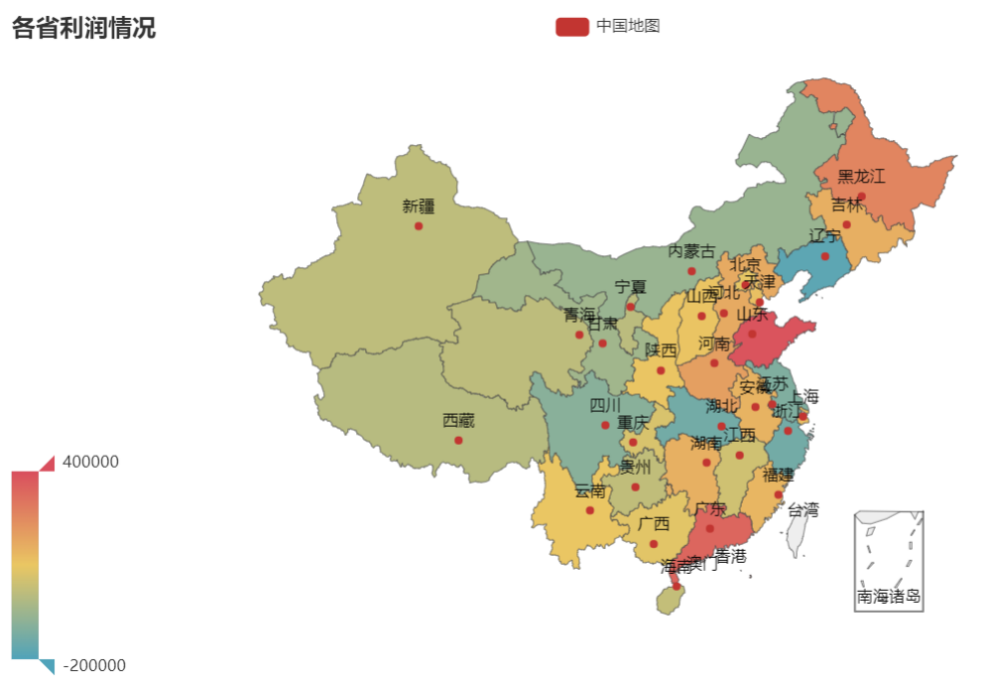
利润亏损的省或自治区
#统计利润亏损的省/自治区
def make_province_bar(self):
to_drop = ['行 ID', '订单 ID', '订单日期', '发货日期', '邮寄方式', '地区', '客户 ID', '客户名称', '细分', '城市', '国家',
'产品 ID', '类别', '子类别', '产品名称', '数量', '折扣']
res = self.newRows.drop(to_drop, axis=1)
provice_dict = {}
for i in res.itertuples():
if i[1] not in provice_dict.keys():
provice_dict[i[1]] = i[3]
else:
provice_dict[i[1]] += i[3]
lowrate_provice_dict={}
for k,v in provice_dict.items():
if v<0:
lowrate_provice_dict[k]=v
print("========展示负利润省/自治区"+str(len(lowrate_provice_dict))+"==============")
d_order = sorted(lowrate_provice_dict.items(), key=lambda x: x[1],reverse=False) # 按字典集合中,每一个元组的第二个元素排列。 # x相当于字典集合中遍历出来的一个元组。
print(d_order)
x = []
y = []
for item in d_order:
x.append(item[0])
y.append(item[1])
c=Bar()
c.add_xaxis(x)
c.add_yaxis("利润",y,color=Faker.rand_color())
c.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
c.set_global_opts(title_opts=opts.TitleOpts(title="负利润省/自治区的利润情况"))
c.render("负利润省的利润情况.html")
return c
运行结果
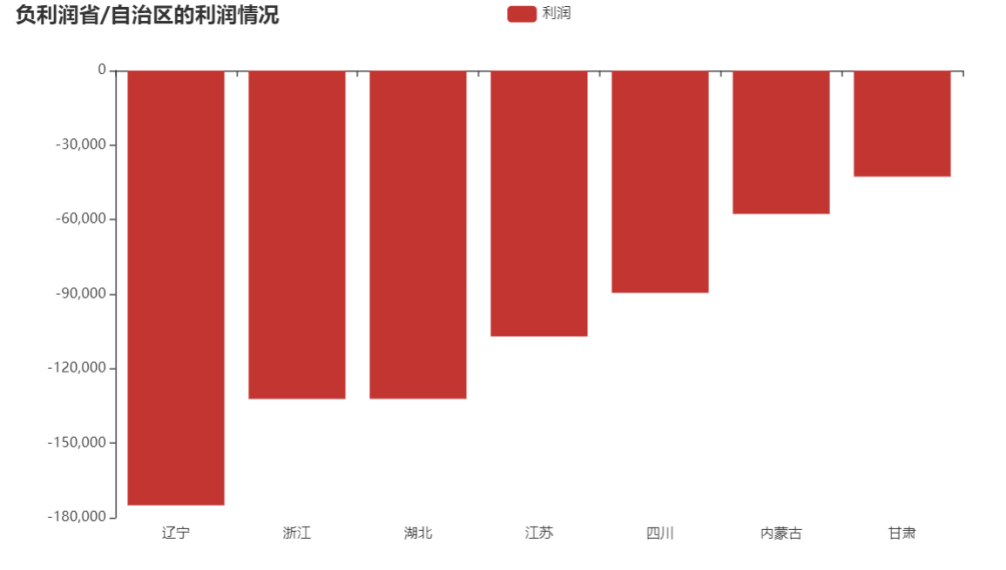
分析
从柱形图中列出负利润的省/自治区有辽宁,浙江,湖北,江苏,四川,内蒙古,甘肃。
通过中国地图展示各省利润情况,颜色越红则利润越大,颜色越蓝则利润越少。则可以发现正利润省/自治区个数多于负利润自治区个数。
看看正利润的省、自治区中山东省正利润最大,接着是广东省。沿边沿海地区的利润不错,多为正利润。而为负利润的地区多为内陆地区,如四川、甘肃、湖北地区。
各市利润情况
绘制各市利润情况地图
#各市利润情况
def make_city_map(self):
to_drop = ['行 ID', '订单 ID', '订单日期', '发货日期', '邮寄方式', '地区', '客户 ID', '客户名称', '细分', '省/自治区', '国家',
'产品 ID', '类别', '子类别', '产品名称', '数量', '折扣']
res = self.newRows.drop(to_drop, axis=1)
city_dict = {}
for i in res.itertuples():
if i[1] not in city_dict.keys():
city_dict[i[1]]=i[3]
else:
city_dict[i[1]] += i[3]
print("========各市的利润情况==============")
print(city_dict)
city_list = []
for k, v in city_dict.items():
city_list.append((k, v))
# 绘制地图
c = Map()
c.add("中国地图", city_list, "china-cities",)
c.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
c.set_global_opts(
title_opts=opts.TitleOpts(title="各市利润情况"),
visualmap_opts=opts.VisualMapOpts(max_=8000, min_=-5000),
)
c.render("各市利润情况.html")
return c
运行结果
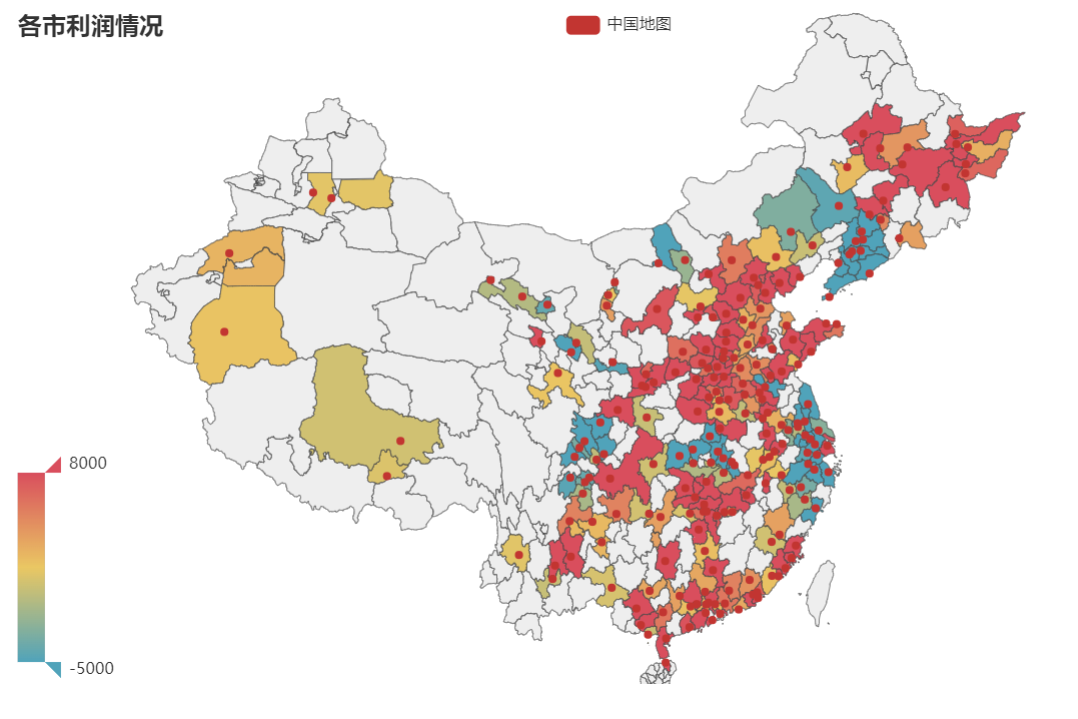
利润亏损的市
#统计利润亏损的市
def make_city_bar(self):
to_drop = ['行 ID', '订单 ID', '订单日期', '发货日期', '邮寄方式', '地区', '客户 ID', '客户名称', '细分', '省/自治区', '国家',
'产品 ID', '类别', '子类别', '产品名称', '数量', '折扣']
res = self.newRows.drop(to_drop, axis=1)
city_dict = {}
for i in res.itertuples():
if i[1] not in city_dict.keys():
city_dict[i[1]] = i[3]
else:
city_dict[i[1]] += i[3]
lowrate_city_dict={}
for k,v in city_dict.items():
if v<0:
lowrate_city_dict[k]=v
print("========展示负利润城市,共"+str(len(lowrate_city_dict))+"==============")
d_order = sorted(lowrate_city_dict.items(), key=lambda x: x[1], reverse=False) # 按字典集合中,每一个元组的第二个元素排列。 # x相当于字典集合中遍历出来的一个元组。
print(d_order)
x=[]
y=[]
for item in d_order:
x.append(item[0])
y.append(item[1])
c=Bar()
c.add_xaxis(x)
c.add_yaxis("利润",y,color=Faker.rand_color())
c.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
c.set_global_opts(title_opts=opts.TitleOpts(title="负利润城市的利润情况"))
c.render("负利润城市的利润情况.html")
return c
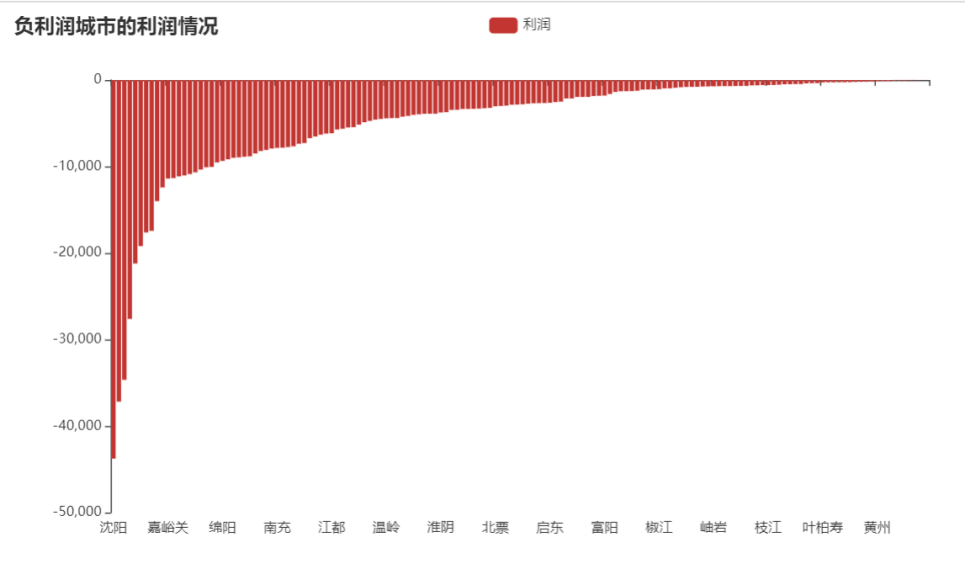
分析
利润亏损情况
负利润省/自治区有7个,依次为辽宁、浙江、湖北、江苏、四川、内蒙古、甘肃
负利润城市共150个,前5个为沈阳、武汉、杭州、成都、襄樊。
从各市的利润地图可看出,在内蒙古、四川、甘肃省的有销售的城市比较少,所以这几个省的利润是负利润受城市数影响。但浙江、江苏、辽宁省份销售的城市多,但这三个省是负利润,则说明这三个省的销售利润是真正的负利润,需要重视。
从各市的利润地图中可以发现销售的城市多分布在沿海以及中部地区。
各省市的销售额情况
# 各省/自治区销售额情况 矩形树图
def make_province_treemap(self):
to_drop = ['行 ID', '订单 ID', '订单日期', '发货日期', '邮寄方式', '地区', '客户 ID', '客户名称', '细分', '国家',
'产品 ID', '类别', '子类别', '产品名称', '利润','数量', '折扣']
res = self.newRows.drop(to_drop, axis=1)
#数据统计
provice_dict={}
for i in res.itertuples():
if i[2] not in provice_dict.keys():
dict = {}
dict[i[1]] = i[3]
list=[]
list.append(dict)
provice_dict[i[2]]=list
else:
list=provice_dict[i[2]]
dict = {}
dict[i[1]] = i[3]
list.append(dict)
print(provice_dict)
new_provice_dict={}
for k0,v0 in provice_dict.items():
temp = {}
for item in v0:
for k,v in item.items():
key=k
value=v
if key not in temp.keys():
temp[key]=value
else:
temp[key]+=value
list=[]
list.append(temp)
new_provice_dict[k0]=list
print("=======new_provice_dict========")
print(new_provice_dict)
new_provice_list=[]
for k, v in new_provice_dict.items():
new_city_dict=v[0]
new_city_list=[]
for k1,v1 in new_city_dict.items():
new_city_list.append((k1,v1))
new_provice_list.append((k, new_city_list))
#统计省的总销售额
p_dict={}
for k,v in new_provice_dict.items():
dict=v[0]
count=0
for v1 in dict.values():
count+=v1
p_dict[k]=count
print("=========p_dict=========")
print(p_dict)
p_list=[]
for k,v in p_dict.items():
p_list.append((k,v))
c=TreeMap()
children_zhejiang=[] #浙江
for j in new_provice_list[0][1]:
children_zhejiang.append({"value": j[1], "name": j[0]})
children_sichuan=[] #四川
for j in new_provice_list[1][1]:
children_sichuan.append({"value": j[1], "name": j[0]})
children_jiangsu=[] #江苏
for j in new_provice_list[2][1]:
children_jiangsu.append({"value": j[1], "name": j[0]})
children_guangdong=[] #广东
for j in new_provice_list[3][1]:
children_guangdong.append({"value": j[1], "name": j[0]})
children_jiangxi=[] #江西
for j in new_provice_list[4][1]:
children_jiangxi.append({"value": j[1], "name": j[0]})
children_shanxi=[] #陕西
for j in new_provice_list[5][1]:
children_shanxi.append({"value": j[1], "name": j[0]})
children_heilongjiang=[] #黑龙江
for j in new_provice_list[6][1]:
children_heilongjiang.append({"value": j[1], "name": j[0]})
children_shandong=[] #山东
for j in new_provice_list[7][1]:
children_shandong.append({"value": j[1], "name": j[0]})
children_shanghai=[] #上海
for j in new_provice_list[8][1]:
children_shanghai.append({"value": j[1], "name": j[0]})
children_hebei=[] #河北
for j in new_provice_list[9][1]:
children_hebei.append({"value": j[1], "name": j[0]})
children_fujian=[] #福建
for j in new_provice_list[10][1]:
children_fujian.append({"value": j[1], "name": j[0]})
children_anhui=[] #安徽
for j in new_provice_list[11][1]:
children_anhui.append({"value": j[1], "name": j[0]})
children_gansu=[] #甘肃
for j in new_provice_list[12][1]:
children_gansu.append({"value": j[1], "name": j[0]})
children_jilin=[] #吉林
for j in new_provice_list[13][1]:
children_jilin.append({"value": j[1], "name": j[0]})
children_liaoning=[] #辽宁
for j in new_provice_list[14][1]:
children_liaoning.append({"value": j[1], "name": j[0]})
children_hubei=[] #湖北
for j in new_provice_list[15][1]:
children_hubei.append({"value": j[1], "name": j[0]})
children_henan=[] #河南
for j in new_provice_list[16][1]:
children_henan.append({"value": j[1], "name": j[0]})
children_hunan=[] #湖南
for j in new_provice_list[17][1]:
children_hunan.append({"value": j[1], "name": j[0]})
children_beijing=[] #北京
for j in new_provice_list[18][1]:
children_beijing.append({"value": j[1], "name": j[0]})
children_chongqi=[] #重庆
for j in new_provice_list[19][1]:
children_chongqi.append({"value": j[1], "name": j[0]})
children_qinghai=[] #青海
for j in new_provice_list[20][1]:
children_qinghai.append({"value": j[1], "name": j[0]})
children_guangxi = [] # 广西
for j in new_provice_list[21][1]:
children_guangxi.append({"value": j[1], "name": j[0]})
children_tianjin=[] #天津
for j in new_provice_list[22][1]:
children_tianjin.append({"value": j[1], "name": j[0]})
children_yunnan=[] #云南
for j in new_provice_list[23][1]:
children_yunnan.append({"value": j[1], "name": j[0]})
children_guizhou=[] #贵州
for j in new_provice_list[24][1]:
children_guizhou.append({"value": j[1], "name": j[0]})
children_shanxi=[] #山西
for j in new_provice_list[25][1]:
children_shanxi.append({"value": j[1], "name": j[0]})
children_neimenggu=[] #内蒙古
for j in new_provice_list[26][1]:
children_neimenggu.append({"value": j[1], "name": j[0]})
children_ningxia=[] #宁夏
for j in new_provice_list[27][1]:
children_ningxia.append({"value": j[1], "name": j[0]})
children_hainan=[] #海南
for j in new_provice_list[28][1]:
children_hainan.append({"value": j[1], "name": j[0]})
children_xinjiang=[] #新疆
for j in new_provice_list[29][1]:
children_xinjiang.append({"value": j[1], "name": j[0]})
children_xizang=[] #西藏
for j in new_provice_list[30][1]:
children_xizang.append({"value": j[1], "name": j[0]})
data=[
{
"value": p_list[0][1],
"name": p_list[0][0], #浙江
"children": children_zhejiang,
},
{
"value": p_list[1][1],
"name": p_list[1][0], # 四川
"children": children_sichuan,
},
{
"value": p_list[2][1],
"name": p_list[2][0], # 江苏
"children": children_jiangsu,
},
{
"value": p_list[3][1],
"name": p_list[3][0], # 广东
"children": children_guangdong,
},
{
"value": p_list[4][1],
"name": p_list[4][0], # 江西
"children": children_jiangxi,
},
{
"value": p_list[5][1],
"name": p_list[5][0], # 陕西
"children": children_shanxi,
},
{
"value": p_list[6][1],
"name": p_list[6][0], # 黑龙江
"children": children_heilongjiang,
}, {
"value": p_list[7][1],
"name": p_list[7][0], # 山东
"children": children_shandong,
}, {
"value": p_list[8][1],
"name": p_list[8][0], # 上海
"children": children_shanghai,
},
{
"value": p_list[9][1],
"name": p_list[9][0], # 河北
"children": children_hebei,
}, {
"value": p_list[10][1],
"name": p_list[10][0], # 福建
"children": children_fujian,
}, {
"value": p_list[11][1],
"name": p_list[11][0], # 安徽
"children": children_anhui,
}, {
"value": p_list[12][1],
"name": p_list[12][0], # 甘肃
"children": children_gansu,
},
{
"value": p_list[13][1],
"name": p_list[13][0], # 吉林
"children": children_jilin,
},
{
"value": p_list[14][1],
"name": p_list[14][0], # 辽宁
"children": children_liaoning,
},
{
"value": p_list[15][1],
"name": p_list[15][0], # 湖北
"children": children_hubei,
},
{
"value": p_list[16][1],
"name": p_list[16][0], # 河南
"children": children_henan,
},
{
"value": p_list[17][1],
"name": p_list[17][0], # 湖南
"children": children_hunan,
},
{
"value": p_list[18][1],
"name": p_list[18][0], # 北京
"children": children_beijing,
},
{
"value": p_list[19][1],
"name": p_list[19][0], # 重庆
"children": children_chongqi,
},
{
"value": p_list[20][1],
"name": p_list[20][0], # 青海
"children": children_qinghai,
},
{
"value": p_list[21][1],
"name": p_list[21][0], # 广西
"children": children_guangxi,
},
{
"value": p_list[22][1],
"name": p_list[22][0], # 天津
"children": children_tianjin,
},
{
"value": p_list[23][1],
"name": p_list[23][0], # 云南
"children": children_yunnan,
},
{
"value": p_list[24][1],
"name": p_list[24][0], # 贵州
"children": children_guizhou,
},
{
"value": p_list[25][1],
"name": p_list[25][0], # 山西
"children": children_shanxi,
},
{
"value": p_list[26][1],
"name": p_list[26][0], # 内蒙古
"children": children_neimenggu,
},
{
"value": p_list[27][1],
"name": p_list[27][0], # 宁夏
"children": children_ningxia,
},
{
"value": p_list[28][1],
"name": p_list[28][0], # 海南
"children": children_hainan,
},
{
"value": p_list[29][1],
"name": p_list[29][0], # 新疆
"children": children_xinjiang,
},
{
"value": p_list[30][1],
"name": p_list[30][0], # 西藏
"children": children_xizang,
},
]
c.add("各省市销售额",data)
c.set_global_opts(title_opts=opts.TitleOpts(title="各省市销售额"))
c.render("各省市销售额-矩形树图.html")
return c
运行结果
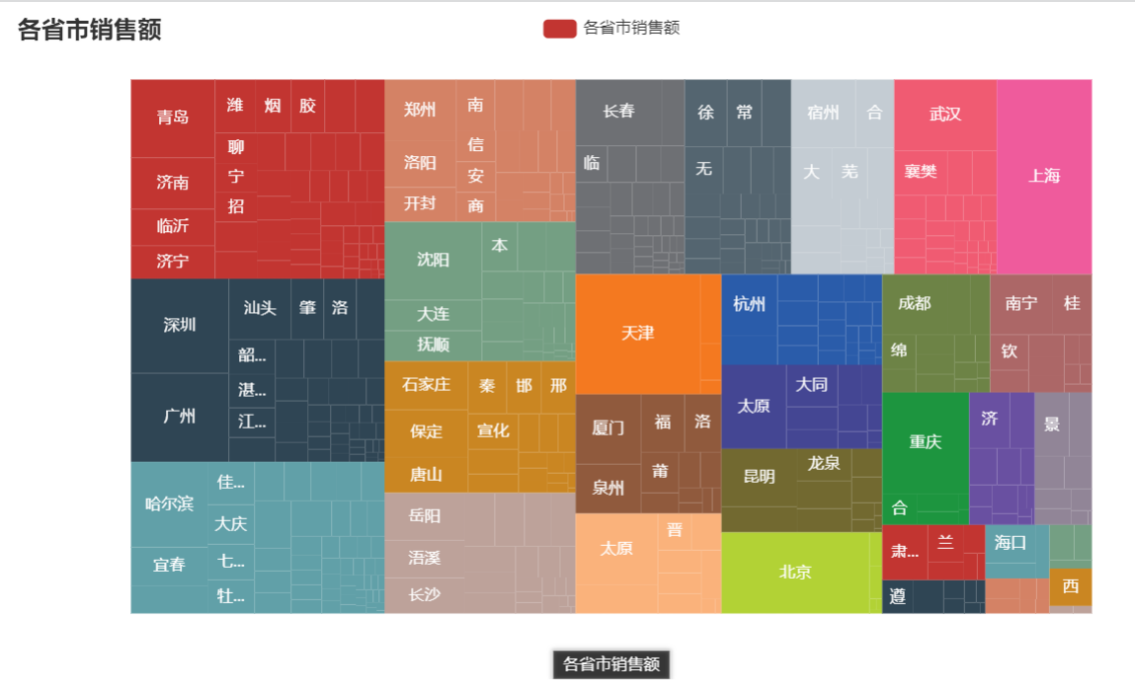
分析
从矩形树图可以看出销售额排名前3的省为:山东省,广东省,黑龙江省。销售额排名前3的城市为深圳,广州,青岛。矩形树图可以更方便地查看省以及市的销售额。
哪些商品的利润值比较大,哪些商品是亏损的
# 子类别-利润值柱形图
def make_type_bar(self):
to_drop = ['行 ID', '订单 ID', '订单日期', '发货日期', '邮寄方式', '地区', '客户 ID', '客户名称', '细分', '城市','省/自治区','国家',
'产品 ID', '类别', '销售额', '产品名称', '数量', '折扣']
res = self.newRows.drop(to_drop, axis=1)
# 数据统计
type_dict = {}
for i in res.itertuples():
if i[1] not in type_dict.keys():
type_dict[i[1]]=i[2]
else:
type_dict[i[1]] += i[2]
print("============按子类别划分的得到利润值===========")
d_order = sorted(type_dict.items(), key=lambda x: x[1],reverse=False) # 按字典集合中,每一个元组的第二个元素排列。 # x相当于字典集合中遍历出来的一个元组。
print(d_order)
x = []
y = []
for item in d_order:
x.append(item[0])
y.append(item[1])
c=Bar()
c.add_xaxis(x)
c.add_yaxis("利润值",y,color=Faker.rand_color())
c.reversal_axis()
c.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
c.set_global_opts(title_opts=opts.TitleOpts(title="子类别-利润值"))
c.render("子类别-利润值.html")
return c
运行结果
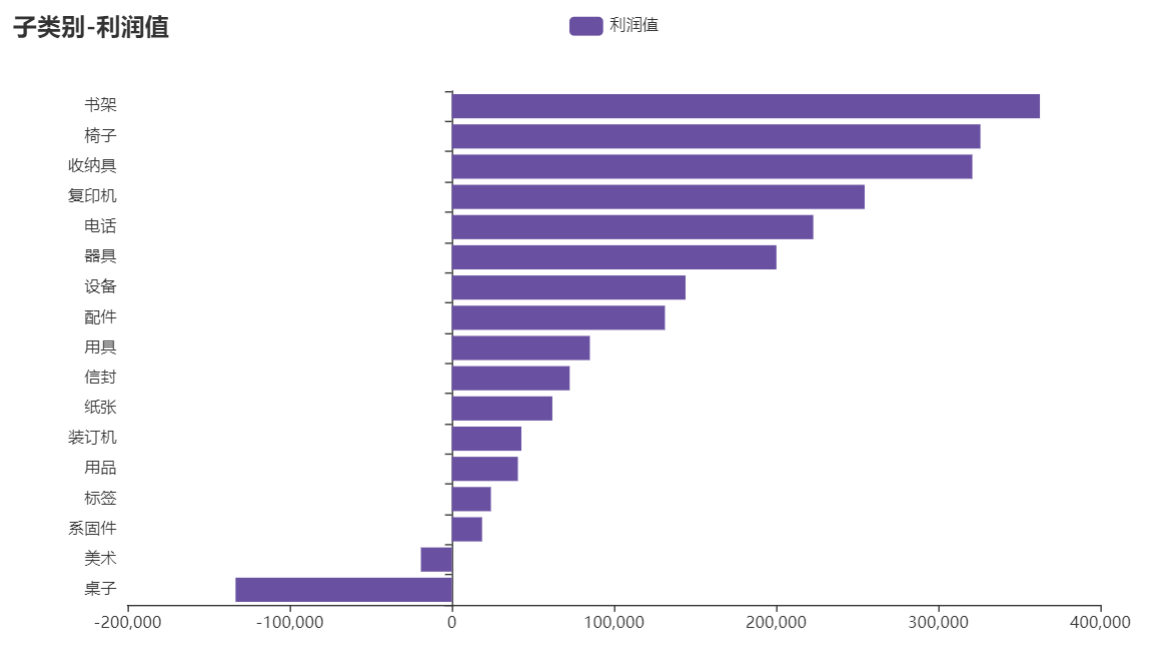
分析
通过柱形图可以看出利润值排名前4的是书架、椅子、收纳具、复印机。亏损的商品是美术、桌子。
根据历史数据预测,当销售额达到一定的数值时会有多大的利润
线性回归预测
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False
filename='超市销售分析.xls'
data = pd.read_excel(io=filename, sheet_name=0, header=0)
# 去空
data.dropna(axis=0, how='any', inplace=True) # axis=0表示index行 "any"表示这一行或列中只要有元素缺失,就删除这一行或列
predict_value=129.696
predict_value = np.array(predict_value).reshape(1, -1) #转为二维数组
'''提取特征和标签数据'''
# 特征features
examX=data['销售额']
# 标签labes
examY=data['利润']
'''建立训练数据和测试数据'''
from sklearn.model_selection import train_test_split
#建立训练数据和测试数据
# 变量依次为:数量数据特征、测试数据特征、训练数据标签、测试数据标签
x_train, x_test, y_train, y_test=train_test_split(examX,examY,train_size=0.25)
#输出各数据大小
# # 特征
# print('原始数据特征:',examX.shape ,
# '\n训练数据特征:',x_train.shape,
# '\n测试数据特征: ',x_test.shape )
# # 标签
# print('\n原始数据标签:',examY.shape ,
# '\n训练数据标签:',y_train.shape,
# '\n测试数据标签: ',y_test.shape )
'''线性回归'''
'''
Reshape your data either using array.reshape(-1, 1) if your data has a single feature
or array.reshape(1, -1) if it contains a single sample.
期望的是2D的数组,而x_train和y_train均为Series
如果只有一个特征,需要reshape(-1, 1);
如果包含一个样本,需要reshape(1, -1)。
'''
# 将训练数据特征x_train转换为2D array XX行*1列
X_train=x_train.values.reshape(-1,1)
# 导入线性回归
from sklearn.linear_model import LinearRegression
# 创建模型:线性回归
model=LinearRegression()
# 训练模型
model.fit(X_train,y_train)
'''
回归函数:y=a+bx
截距intercept: a
回归系数coef : b
'''
a=model.intercept_
b=model.coef_
predict_outcome = model.predict(predict_value)
print("销售额为:"+str(predict_value)+",利润预测值为:"+str(predict_outcome))
print('最佳拟合线的截距:a=',a,'最佳拟合线的回归系数:b=',b)
# 将测试数据特征x_test 转换为2D array XX行*1列
X_test=x_test.values.reshape(-1,1)
# 返回决定系数R²
print("R²="+str(model.score(X_test,y_test)))
'''绘制训练&测试散点图及最佳拟合线'''
# 1.绘制训练数据散点图
plt.scatter(X_train,y_train,color='b',label='train data')
# 2.绘制最佳拟合线
# 训练数据的预测值
y_train_pred=model.predict(X_train)
# 绘制最佳拟合线
plt.plot(X_train,y_train_pred,color='y',linewidth=2,label='best line')
# 3.绘制测试数据的散点图
plt.scatter(X_test,y_test,color='r',label='test data')
# 4.添加图例和标签
plt.legend(loc=2)
plt.xlabel("销售额")
plt.ylabel("利润")
# 5.显示图像
plt.savefig("销售额-利润线性回归预测",dpi=300)
plt.show()
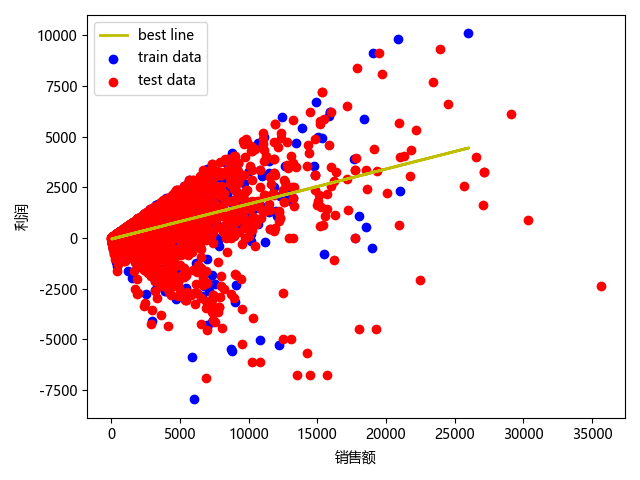
运行结果
设置的销售额为129.696,得到的利润预测值为-34.56
决策树预测
filename='超市销售分析.xls'
data = pd.read_excel(io=filename, sheet_name=0, header=0)
# 去空
data.dropna(axis=0, how='any', inplace=True) # axis=0表示index行 "any"表示这一行或列中只要有元素缺失,就删除这一行或列
to_drop=['行 ID', '订单 ID','订单日期','发货日期', '邮寄方式', '客户 ID', '客户名称', '细分', '城市', '省/自治区', '国家',
'产品 ID','类别', '子类别','产品名称','地区','折扣','数量']
data=data.drop(to_drop, axis=1)
'''提取特征和标签数据'''
# 特征features
examX=data['销售额']
# 标签labes
examY=data['利润']
'''建立训练数据和测试数据'''
from sklearn.model_selection import train_test_split
#建立训练数据和测试数据
# 变量依次为:数量数据特征、测试数据特征、训练数据标签、测试数据标签
x_train, x_test, y_train, y_test=train_test_split(examX,examY,train_size=0.25)
# 将训练数据特征x_train转换为2D array XX行*1列
X_train=x_train.values.reshape(-1,1)
# 将测试数据特征x_test 转换为2D array XX行*1列
X_test=x_test.values.reshape(-1,1)
# 将训练数据特征y_train转换为2D array XX行*1列
Y_train=y_train.values.reshape(-1,1)
# 将测试数据特征y_test 转换为2D array XX行*1列
Y_test=y_test.values.reshape(-1,1)
#划分成训练集,验证集,验证集,不过这里我们数据量不够大,没必要
#此段代码中,test_size = 0.25,表示把数据集划分为两份,训练集和测试集之比为4:1(二八原则)
#关于train_test_split(),随机划分训练集和测试集的函数,可参考博客:https://blog.csdn.net/qq_38410428/article/details/94054920
#train_x, test_x, train_y, test_y = train_test_split(X_train, Y_train, test_size = 0.25)
#训练决策树
clf = tree.DecisionTreeClassifier(criterion='gini')
model = clf.fit(X_train,y_train.astype('int'))
# #如果划分了,训练集、验证集和测试集,加上此步骤,看训练好的决策树在测试集上的准确率
# res = model.predict(X_test)
# print(res) #模型结果输出
# print(Y_test) #实际值
# print((sum(res==Y_test)/len(res))) #准确率
print("==========================")
score = model.score(X_test,y_test.astype('int'))
print("R²="+str(score))
print("==========================")
predict_value=129.696
A = ([[predict_value]]) #销售额
predict_result = clf.predict(A)
print('销售额为:'+str(predict_value)+' 利润值预测结果:'+str(predict_result))
运行结果
输入的销售额为129.696时得到的利润预测值为63

分析
线性回归 R^2=0.21,决策树 R^2 =0.118。通过R^2的值可以发现线性回归与决策树预测的效果并不理想,推测因为销售额与利润的分布不是很规律,从散点图中可以发现销售额与利润的分布呈扇形,目前我还没有想到好的模型可以使得预测效果理想一些。
超市销售数据集属性间的相关性分析
#销售额、数量、折扣、利润、时间、商品类别的相关性
def make_Heatmap(self):
to_drop = ['行 ID', '订单 ID', '发货日期', '邮寄方式', '客户 ID', '客户名称', '细分', '城市', '省/自治区', '国家',
'产品 ID', '子类别', '产品名称', '地区']
res = self.newRows.drop(to_drop, axis=1)
# 转换 datetime 类型
res['订单日期'] = pd.to_datetime(res['订单日期'])
## 增加年份列和月份列
res['年份'] = res['订单日期'].dt.year
res['月份'] = res['订单日期'].dt.month
#转换类别
dummy_data = pd.get_dummies(res['类别'], prefix="类别",dummy_na=False,drop_first=False) # dummy_na是否考虑缺失值,drop_first是否做某一项为全0的哑变量转换,默认False
temp2 = res.join(dummy_data)
# 导入数据可视化所需要的库
import matplotlib.pyplot as plt # Matplotlib – Python画图工具库
import seaborn as sns # Seaborn – 统计学数据可视化工具库
# 对所有的标签和特征两两显示其相关性的热力图(heatmap)
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False
sns.heatmap(temp2.corr(), annot=True) #True,就在热力图的每个单元上显示数值
plt.savefig("热力图.png", dpi=300)
plt.show()
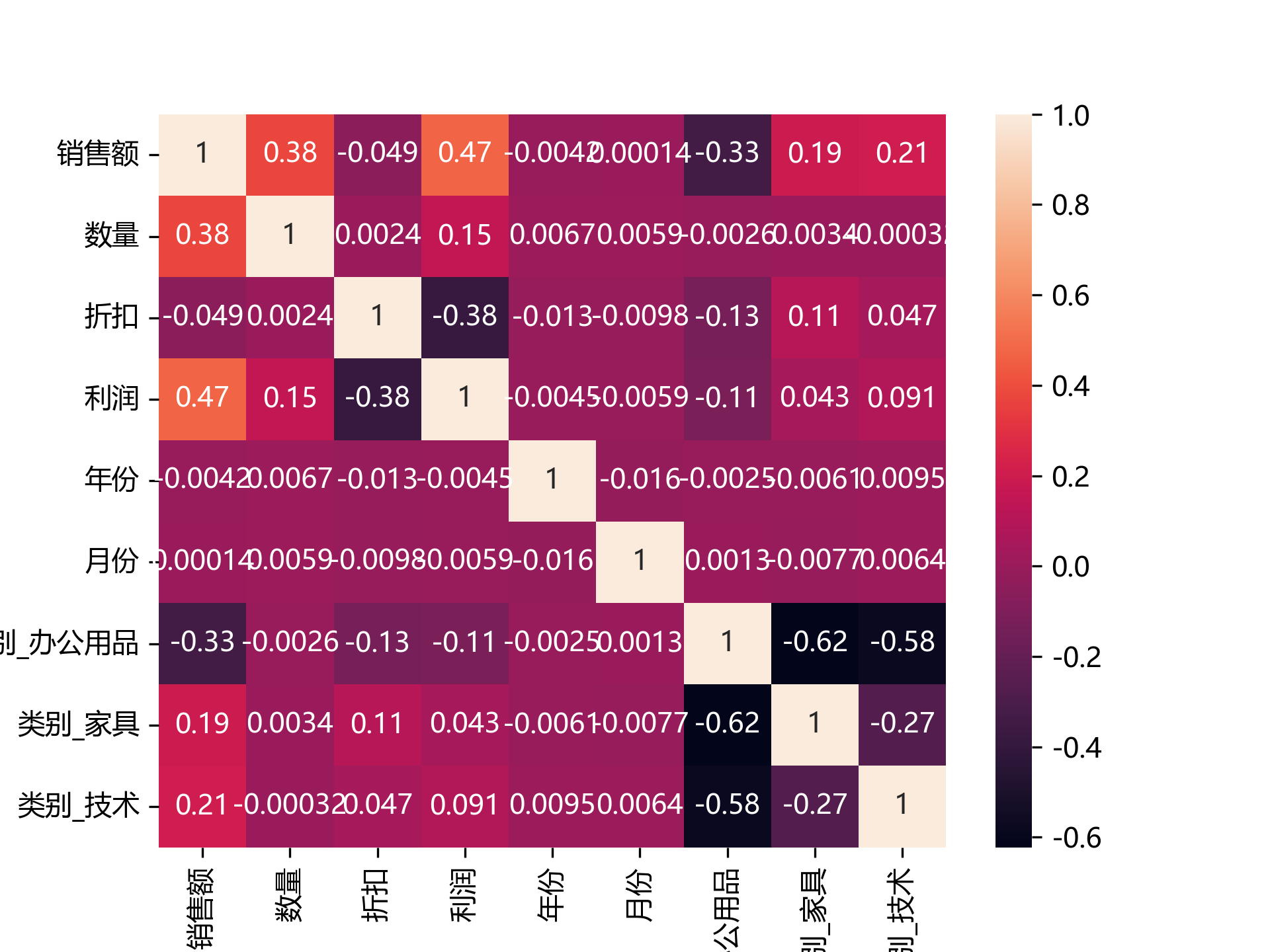
运行结果
分析
热力图中数值越接近1则代表正线性相关性越强,接近-1则代表负线性相关性越强,0则代表不相关。可以发现销售额与利润的的正相关性最强0.47,类别_家具与类别_办公品的负相关性最强-0.62。
商品类别分析,各类别商品中卖的最好的是什么
统计三大商品类别的销售额以及占比
#类别-环形图
def make_type_roll(self):
to_drop = ['行 ID', '订单 ID', '订单日期', '发货日期', '邮寄方式', '地区', '客户 ID', '客户名称', '细分', '城市', '省/自治区', '国家',
'产品 ID', '子类别', '利润', '产品名称', '数量', '折扣']
res = self.newRows.drop(to_drop, axis=1)
# 数据统计
type_dict = {}
for i in res.itertuples():
if i[1] not in type_dict.keys():
type_dict[i[1]]=i[2]
else:
type_dict[i[1]]+=i[2]
print("======按类别统计销售额==============")
print(type_dict)
x=[]
for k,v in type_dict.items():
x.append((k,v))
c=Pie()
c.add("",x,radius=["40%", "75%"],)
c.set_global_opts(
title_opts=opts.TitleOpts(title="按类别统计销售额"),
legend_opts=opts.LegendOpts(type_="scroll", pos_left="80%", orient="vertical"),
)
c.set_series_opts(
label_opts=opts.LabelOpts(formatter="{b}: {c}({d}%)")) # {a}(系列名称),{b}(数据名称),{c}(数值数组), {d}(无)。如下图:
# 生成html
c.render("按类别统计销售额.html")
return c
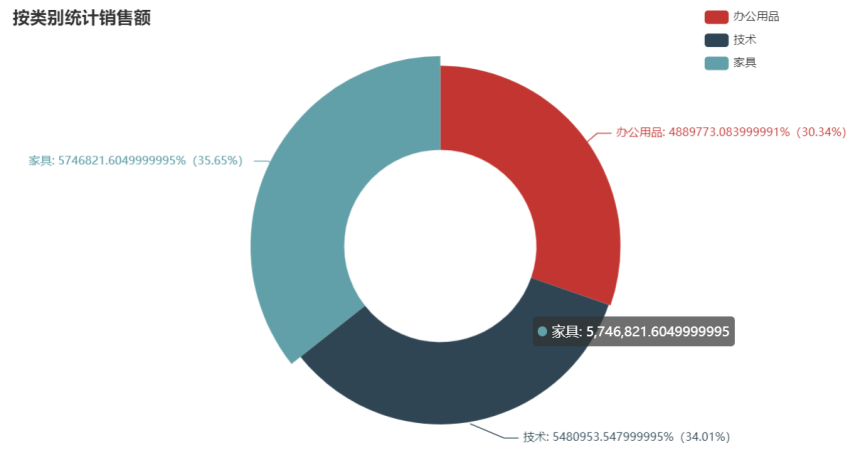
运行结果
分析
通过饼图可以看出三类商品的销售额占比都差不多,家具类占比35.65%,技术类占比34.01%,办公用品占比30.34%
三大商品类别中热销榜top10的商品
#每个类别中的子类别排名前10
def make_typetop10_bar(self):
to_drop = ['行 ID', '订单 ID', '订单日期', '发货日期', '邮寄方式', '地区', '客户 ID', '客户名称', '细分', '城市', '省/自治区', '国家',
'产品 ID', '利润', '销售额', '折扣']
res = self.newRows.drop(to_drop, axis=1)
# 数据统计
furniture_dict = {} #家具
OfficeSupplies_dict={} #办公用品
technology_dict={} #技术
for i in res.itertuples():
str=i[3]
temp=str.split(",")[0] #商品名称去掉颜色
if i[1] == '家具':
if temp not in furniture_dict.keys():
furniture_dict[temp]=i[4]
else:
furniture_dict[temp] += i[4]
if i[1] == '办公用品':
if temp not in OfficeSupplies_dict.keys():
OfficeSupplies_dict[temp]=i[4]
else:
OfficeSupplies_dict[temp] += i[4]
if i[1]=='技术':
if temp not in technology_dict.keys():
technology_dict[temp] = i[4]
else:
technology_dict[temp] += i[4]
d_furniture = sorted(furniture_dict.items(), key=lambda x: x[1],
reverse=False) # 按字典集合中,每一个元组的第二个元素排列。 # x相当于字典集合中遍历出来的一个元组。
print("==========家具类购买数量前10===========")
print(d_furniture)
self.x1=[]
self.y1=[]
for item in d_furniture[:10]:
self.x1.append(item[0])
self.y1.append(item[1])
d_OfficeSupplies= sorted(OfficeSupplies_dict.items(), key=lambda x: x[1],
reverse=False) # 按字典集合中,每一个元组的第二个元素排列。 # x相当于字典集合中遍历出来的一个元组。
print("==========办公用品类购买数量前10===========")
print(d_OfficeSupplies)
self.x2 = []
self.y2 = []
for item in d_OfficeSupplies[:10]:
self.x2.append(item[0])
self.y2.append(item[1])
d_technology = sorted(technology_dict.items(), key=lambda x: x[1],
reverse=False) # 按字典集合中,每一个元组的第二个元素排列。 # x相当于字典集合中遍历出来的一个元组。
print("==========技术类购买数量前10===========")
print(d_technology)
self.x3 = []
self.y3 = []
for item in d_technology[:10]:
self.x3.append(item[0])
self.y3.append(item[1])
a = Bar() # 家具
a.add_xaxis(self.x1)
a.add_yaxis("销售额", self.y1, color=Faker.rand_color())
a.reversal_axis()
a.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
a.set_global_opts(
title_opts=opts.TitleOpts(title="家具类别销量热榜top10"),
legend_opts=opts.LegendOpts(type_="scroll", pos_left="80%", orient="vertical"),
)
a.render("家具类别销量热榜top10.html")
return a
def make_bar1(self):
a=Bar() #家具
a.add_xaxis(self.x1)
a.add_yaxis("销售数量",self.y1,color=Faker.rand_color())
a.reversal_axis()
a.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
a.set_global_opts(
title_opts=opts.TitleOpts(title="家具类别销量热榜top10"),
legend_opts=opts.LegendOpts(type_="scroll", pos_left="80%", orient="vertical"),
)
a.render("家具类别销量热榜top10.html")
return a
def make_bar2(self):
b=Bar() #办公用品
b.add_xaxis(self.x2)
b.add_yaxis("销售额",self.y2,color=Faker.rand_color())
b.reversal_axis()
b.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
b.set_global_opts(
title_opts=opts.TitleOpts(title="办公用品类别销量热榜top10"),
legend_opts=opts.LegendOpts(type_="scroll", pos_left="80%", orient="vertical"),
)
b.render("办公用品类别销量热榜top10.html")
return b
def make_bar3(self):
c=Bar() #技术
c.add_xaxis(self.x3)
c.add_yaxis("销售额",self.y3,color=Faker.rand_color())
c.reversal_axis()
c.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
c.set_global_opts(
title_opts=opts.TitleOpts(title="技术类别用品销量热榜top10"),
legend_opts=opts.LegendOpts(type_="scroll", pos_left="80%", orient="vertical"),
)
c.render("技术类别用品销量热榜top10.html")
return c
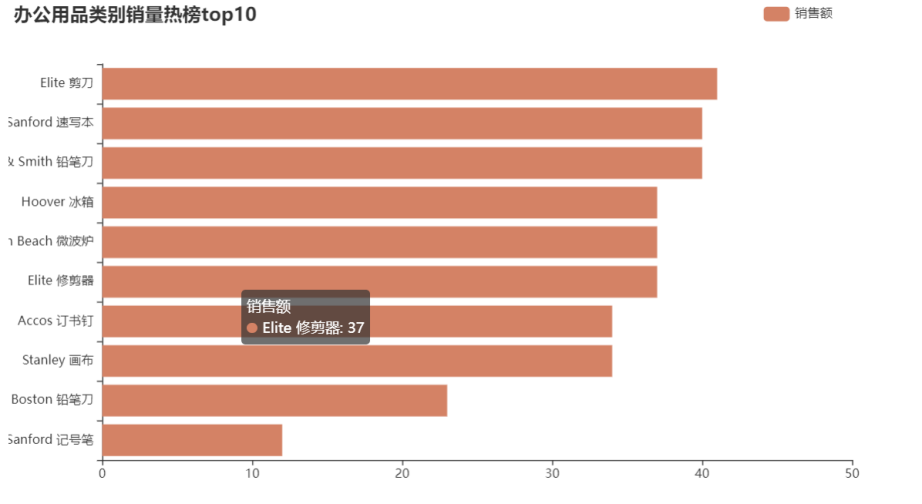
运行结果
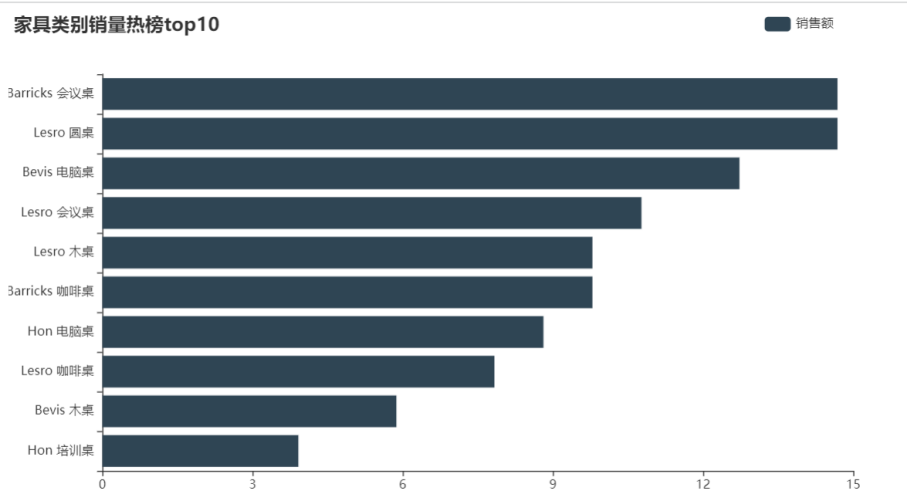
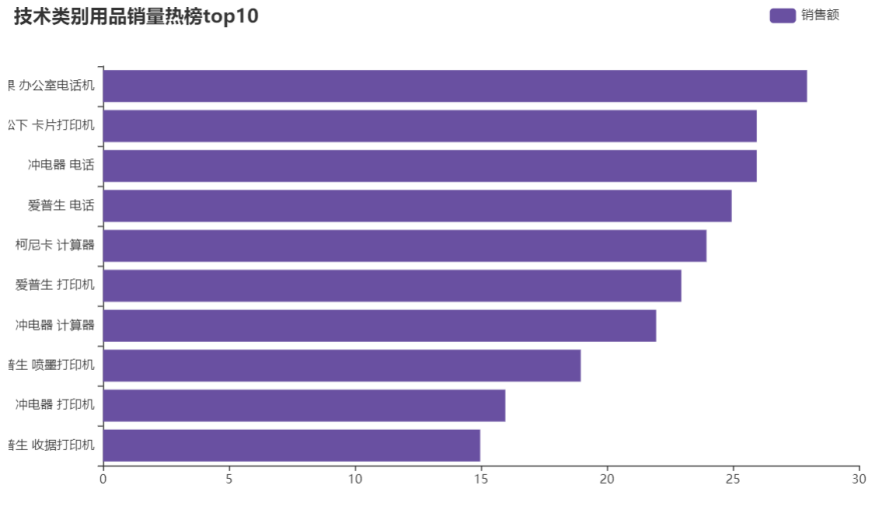
分析
通过柱形图列出的三大类购买数量排名前10的商品。办公用品类卖的最多的时剪刀,家具类排名前10的都是桌子,但结合之前的商品类别-利润情况中,桌子是负利润的,但桌子的销量也不错,则应该考虑桌子成本因素。技术类别中,销量top10中打印机占50%,则进货时也可考虑多进打印机。
分析销售额,利润,随时间的变化,是否有周期性
年度销售额与利润情况
#年度销售额,销售额增长率
def make_saleyear_BarAndLine(self):
to_drop = ['行 ID', '订单 ID', '发货日期', '邮寄方式', '客户 ID', '客户名称', '细分', '城市', '省/自治区', '国家',
'产品 ID', '类别','子类别', '产品名称', '地区','数量','折扣','利润']
res = self.newRows.drop(to_drop, axis=1)
# 转换 datetime 类型
res['订单日期'] = pd.to_datetime(res['订单日期'])
## 增加年份列和月份列
res['年份'] = res['订单日期'].dt.year
res['月份'] = res['订单日期'].dt.month
year=res['年份'].unique()
year=sorted(year,reverse=False)
# 创建销售额透视表
sales = pd.pivot_table(res, index='月份', columns='年份', aggfunc=[np.sum]) #aggfunc参数可以设置我们对数据聚合时进行的函数操作。
sales.columns = year
sales.index = ['1月', '2月', '3月', '4月', '5月', '6月', '7月', '8月', '9月', '10月', '11月', '12月']
print(type(sales.sum()))
sum=sales.sum().tolist()
#年度销售额,增长率
rise_12 = (sum[1] - sum[0]) / sum[0]
rise_13 = (sum[2] - sum[1]) / sum[1]
rise_14 = (sum[3] - sum[2]) / sum[2]
rise_rate = [0, rise_12, rise_13, rise_14]
sales_sum = pd.DataFrame({'Sales_sum': sales.sum()})
sales_sum['rise_rate'] = rise_rate
sales_sum.index = pd.Series(['2011年', '2012年', '2013年', '2014年'])
x=sales_sum.index.tolist()
y1=sales_sum.Sales_sum.tolist()
y2=sales_sum.rise_rate.tolist()
print(x,y1,y2)
bar = (
Bar()
.extend_axis(
yaxis=opts.AxisOpts(
name="销售额",
type_="value",
)
)
.add_xaxis(xaxis_data=x)
.add_yaxis("销售额",y1,label_opts=opts.LabelOpts(is_show=False),color=Faker.rand_color())
.set_global_opts(
title_opts=opts.TitleOpts(title="年度销售额及增长率"),
tooltip_opts=opts.TooltipOpts(
is_show=True, trigger="axis", axis_pointer_type="cross"
),
xaxis_opts=opts.AxisOpts(
type_="category",
axispointer_opts=opts.AxisPointerOpts(is_show=True, type_="shadow"),
),
yaxis_opts=opts.AxisOpts(
name="销售额",
type_="value",
axistick_opts=opts.AxisTickOpts(is_show=True),
splitline_opts=opts.SplitLineOpts(is_show=True),
),
)
)
line = (
Line()
.add_xaxis(xaxis_data=x)
.add_yaxis(
series_name="增长率",
yaxis_index=1,
y_axis=y2,
label_opts=opts.LabelOpts(is_show=True),
color=Faker.rand_color()
)
)
bar.overlap(line).render("年度销售额及增长率.html")
return bar
# 年度利润及增长率
def make_profityear_BarAndLine(self):
to_drop = ['行 ID', '订单 ID', '发货日期', '邮寄方式', '客户 ID', '客户名称', '细分', '城市', '省/自治区', '国家',
'产品 ID', '类别', '子类别', '产品名称', '地区', '数量', '折扣', '销售额']
res = self.newRows.drop(to_drop, axis=1)
# 转换 datetime 类型
res['订单日期'] = pd.to_datetime(res['订单日期'])
## 增加年份列和月份列
res['年份'] = res['订单日期'].dt.year
res['月份'] = res['订单日期'].dt.month
year = res['年份'].unique()
year = sorted(year, reverse=False)
# 创建销售额透视表
sales = pd.pivot_table(res, index='月份', columns='年份', aggfunc=[np.sum]) # aggfunc参数可以设置我们对数据聚合时进行的函数操作。
sales.columns = year
sales.index = ['1月', '2月', '3月', '4月', '5月', '6月', '7月', '8月', '9月', '10月', '11月', '12月']
print(type(sales.sum()))
sum = sales.sum().tolist()
# 年度销售额,增长率
rise_12 = (sum[1] - sum[0]) / sum[0]
rise_13 = (sum[2] - sum[1]) / sum[1]
rise_14 = (sum[3] - sum[2]) / sum[2]
rise_rate = [0, rise_12, rise_13, rise_14]
sales_sum = pd.DataFrame({'Sales_sum': sales.sum()})
sales_sum['rise_rate'] = rise_rate
sales_sum.index = pd.Series(['2011年', '2012年', '2013年', '2014年'])
x = sales_sum.index.tolist()
y1 = sales_sum.Sales_sum.tolist()
y2 = sales_sum.rise_rate.tolist()
print(x, y1, y2)
bar = (
Bar()
.extend_axis(
yaxis=opts.AxisOpts(
name="增长率",
type_="value",
)
)
.add_xaxis(xaxis_data=x)
.add_yaxis("利润", y1, label_opts=opts.LabelOpts(is_show=False), color=Faker.rand_color())
.set_global_opts(
title_opts=opts.TitleOpts(title="年度利润及增长率"),
tooltip_opts=opts.TooltipOpts(
is_show=True, trigger="axis", axis_pointer_type="cross"
),
xaxis_opts=opts.AxisOpts(
type_="category",
axispointer_opts=opts.AxisPointerOpts(is_show=True, type_="shadow"),
),
yaxis_opts=opts.AxisOpts(
name="利润",
type_="value",
axistick_opts=opts.AxisTickOpts(is_show=True),
splitline_opts=opts.SplitLineOpts(is_show=True),
),
)
)
line = (
Line()
.add_xaxis(xaxis_data=x)
.add_yaxis(
series_name="增长率",
yaxis_index=1,
y_axis=y2,
label_opts=opts.LabelOpts(is_show=True),
color=Faker.rand_color()
)
)
bar.overlap(line).render("年度利润及增长率.html")
return bar
运行结果
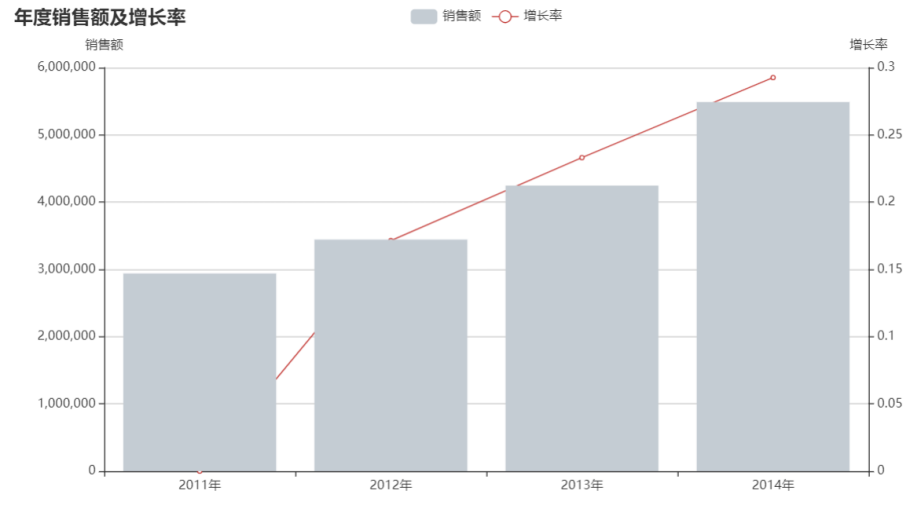
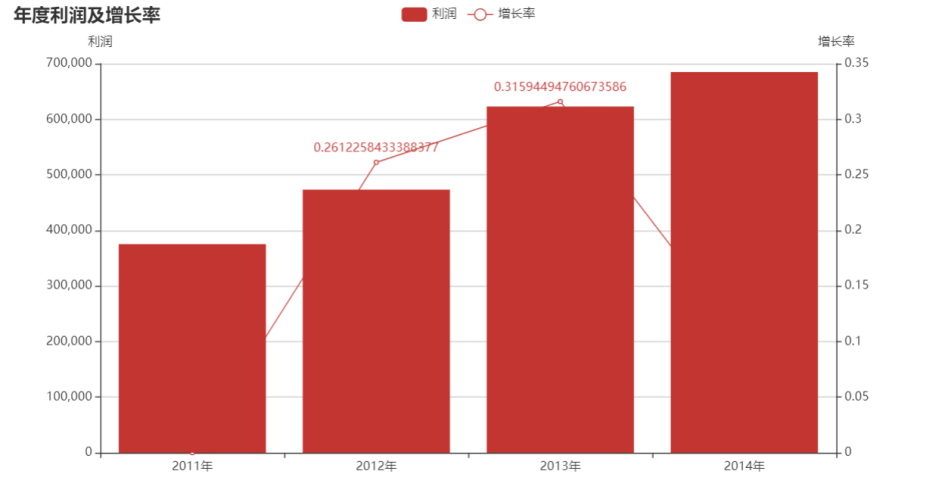
分析
年度销售情况
年度销售额以及年度利润都是增长的,但年度利润增长率在2014年是大减的。达到3年内的最低值。
月度销售额与利润情况
#月度销售额
def make_salemonth_BarAndLine(self):
to_drop = ['行 ID', '订单 ID', '发货日期', '邮寄方式', '客户 ID', '客户名称', '细分', '城市', '省/自治区', '国家',
'产品 ID', '类别', '子类别', '产品名称', '地区', '数量', '折扣', '利润']
res = self.newRows.drop(to_drop, axis=1)
# 转换 datetime 类型
res['订单日期'] = pd.to_datetime(res['订单日期'])
## 增加年份列和月份列
res['年份'] = res['订单日期'].dt.year
res['月份'] = res['订单日期'].dt.month
# year = res['年份'].unique()
# year = sorted(year, reverse=False)
# 创建销售额透视表
sales = pd.pivot_table(res, index='月份', columns='年份', aggfunc=[np.sum]) # aggfunc参数可以设置我们对数据聚合时进行的函数操作。
sales.columns = ['2011年','2012年','2013年','2014年']
sales.index = ['1月', '2月', '3月', '4月', '5月', '6月', '7月', '8月', '9月', '10月', '11月', '12月']
print(sales)
x = sales.index.tolist()
y_2011=sales['2011年']
y_2012 = sales['2012年']
y_2013 = sales['2013年']
y_2014 = sales['2014年']
c=Line()
c.add_xaxis(x)
c.add_yaxis("2011年",y_2011, )
c.add_yaxis("2012年", y_2012,)
c.add_yaxis("2013年", y_2013, )
c.add_yaxis("2014年", y_2014,)
c.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
c.set_global_opts(
title_opts=opts.TitleOpts(title="月度销售额"),
tooltip_opts=opts.TooltipOpts(trigger="axis", axis_pointer_type="cross"),
yaxis_opts=opts.AxisOpts(
name='销售额',
name_textstyle_opts=opts.TextStyleOpts(
font_family='Times New Roman',
font_size=14,
color='black',
font_weight='bolder',
),
type_="value",
axistick_opts=opts.AxisTickOpts(is_show=True),
splitline_opts=opts.SplitLineOpts(is_show=True),
),
xaxis_opts=opts.AxisOpts(name='月份',name_location='middle',
name_textstyle_opts=opts.TextStyleOpts(
font_family='Times New Roman',
font_size=14,
color='black',
font_weight='bolder',
),type_="category", boundary_gap=False),)
c.render("月度销售额.html")
return c
# 月度利润
def make_profitmonth_BarAndLine(self):
to_drop = ['行 ID', '订单 ID', '发货日期', '邮寄方式', '客户 ID', '客户名称', '细分', '城市', '省/自治区', '国家',
'产品 ID', '类别', '子类别', '产品名称', '地区', '数量', '折扣', '销售额']
res = self.newRows.drop(to_drop, axis=1)
# 转换 datetime 类型
res['订单日期'] = pd.to_datetime(res['订单日期'])
## 增加年份列和月份列
res['年份'] = res['订单日期'].dt.year
res['月份'] = res['订单日期'].dt.month
# year = res['年份'].unique()
# year = sorted(year, reverse=False)
# 创建销售额透视表
sales = pd.pivot_table(res, index='月份', columns='年份', aggfunc=[np.sum]) # aggfunc参数可以设置我们对数据聚合时进行的函数操作。
sales.columns = ['2011年', '2012年', '2013年', '2014年']
sales.index = ['1月', '2月', '3月', '4月', '5月', '6月', '7月', '8月', '9月', '10月', '11月', '12月']
print(sales)
x = sales.index.tolist()
y_2011 = sales['2011年']
y_2012 = sales['2012年']
y_2013 = sales['2013年']
y_2014 = sales['2014年']
c = Line()
c.add_xaxis(x)
c.add_yaxis("2011年", y_2011, )
c.add_yaxis("2012年", y_2012, )
c.add_yaxis("2013年", y_2013, )
c.add_yaxis("2014年", y_2014, )
c.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
c.set_global_opts(
title_opts=opts.TitleOpts(title="月度利润"),
tooltip_opts=opts.TooltipOpts(trigger="axis", axis_pointer_type="cross"),
yaxis_opts=opts.AxisOpts(
name='利润',
name_textstyle_opts=opts.TextStyleOpts(
font_family='Times New Roman',
font_size=14,
color='black',
font_weight='bolder',
),
type_="value",
axistick_opts=opts.AxisTickOpts(is_show=True),
splitline_opts=opts.SplitLineOpts(is_show=True),
),
xaxis_opts=opts.AxisOpts(name='月份', name_location='middle',
name_textstyle_opts=opts.TextStyleOpts(
font_family='Times New Roman',
font_size=14,
color='black',
font_weight='bolder',
), type_="category", boundary_gap=False), )
c.render("月度利润.html")
return c
运行结果
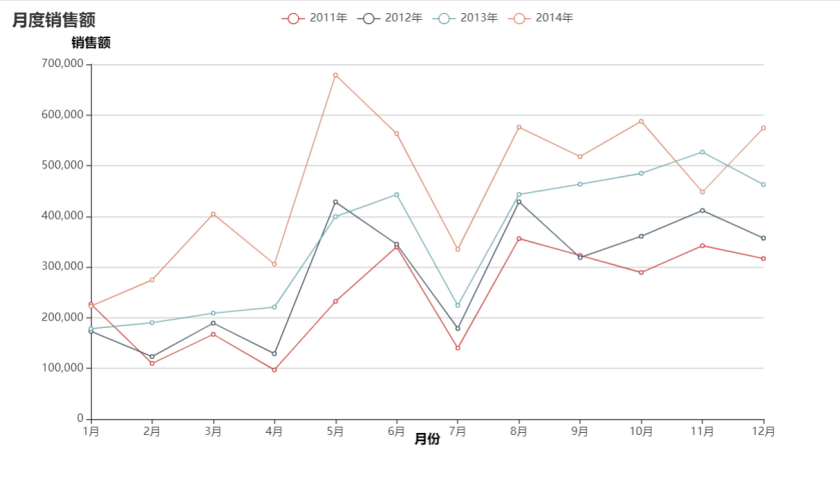
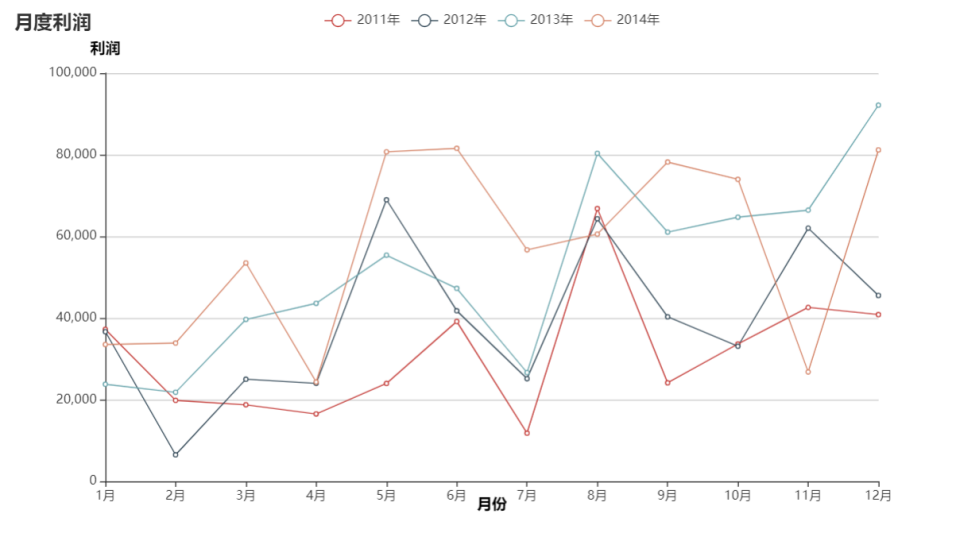
分析
月度销售额情况
月度销售额与月度利润有一定规律,在5,6月份时销售额大涨,在7月份时大跌。而后8月份有回升,推测应该跟某中商品的销售有关。根据前面的商品三大类别家具类、办公用品类、技术类的销售额占比图以及各类热销榜图可以推测办公用品类:剪刀,技术类:打印机,家具类:会议桌。这些排行第一的商品都可属于办公用品,在年中时公司需要进行采购,则这些销售额受这些商品的影响呈季节性的变化。
客户分析,哪种客户消费额最多,客户都喜欢买什么商品
客户类别,销售额,利润情况
##客户类别销售,利润情况
def customer_sale(self):
to_drop = ['行 ID', '订单 ID', '发货日期', '邮寄方式', '客户 ID', '客户名称', '城市', '省/自治区', '国家',
'产品 ID', '类别', '子类别', '产品名称', '地区', '数量', '折扣']
res = self.newRows.drop(to_drop, axis=1)
customer_sale_dict = {} # 销售额
customer_profit_dict = {} # 利润
for i in res.itertuples():
if i[2] not in customer_sale_dict.keys() and i[2] not in customer_profit_dict.keys():
customer_sale_dict[i[2]]=i[3]
customer_profit_dict[i[2]] = i[4]
else:
customer_sale_dict[i[2]] += i[3]
customer_profit_dict[i[2]] += i[4]
print("=================按消费者划分得到的销售额与利润================")
print(customer_sale_dict)
print(customer_profit_dict)
y1=[] #销售额
for value in customer_sale_dict.values():
y1.append(value)
y2 = [] #利润
for value in customer_profit_dict.values():
y2.append(value)
c=Bar()
c.add_xaxis(['公司','消费者','小型企业'])
c.add_yaxis("销售额",y1,color=Faker.rand_color())
c.add_yaxis("利润", y2, color=Faker.rand_color())
c.set_series_opts(label_opts=opts.LabelOpts(is_show=True))
c.set_global_opts(
title_opts=opts.TitleOpts(title="客户-销售额,利润"),
legend_opts=opts.LegendOpts(type_="scroll", pos_left="80%", orient="vertical"),
)
c.render("客户-销售额,利润.html")
return c
运行结果
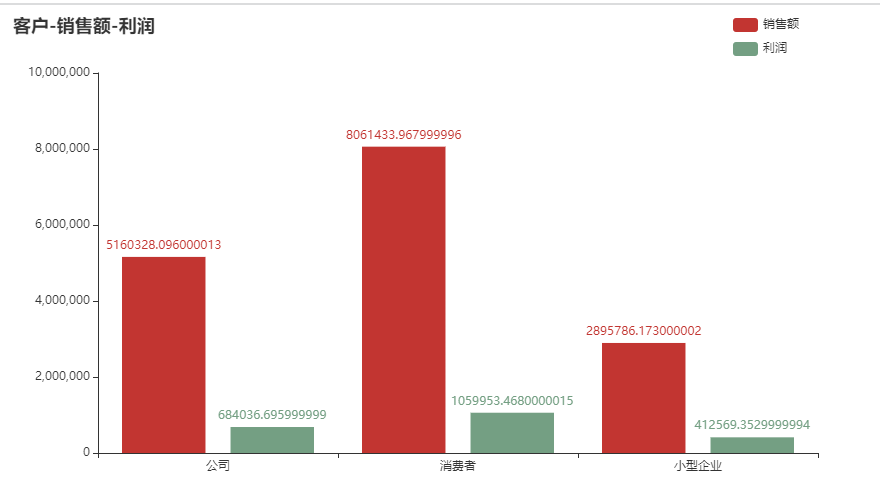
分析
通过销售额,利润可以看出消费者类型用户是我们的主要客户,接着是公司,然后是小型企业。
客户类别,商品子类别,销售额,利润情况,分析客户喜欢什么样的商品
# 客户-商品子类别,销售额
def customer_type(self):
to_drop = ['行 ID', '订单 ID', '发货日期', '邮寄方式', '客户 ID', '客户名称', '城市', '省/自治区', '国家',
'产品 ID', '类别', '产品名称', '地区', '数量', '折扣','利润']
res = self.newRows.drop(to_drop, axis=1)
type_sale_dict = {} # 销售额
for i in res.itertuples():
dict = {}
if i[3] not in type_sale_dict.keys():
dict[i[2]]=i[4]
type_sale_dict[i[3]]=dict
else:
dict=type_sale_dict[i[3]]
if i[2] not in dict.keys():
dict[i[2]]=i[4]
else:
if i[2] == '公司':
dict['公司']+=i[4]
if i[2] == '消费者':
dict['消费者']+=i[4]
if i[2] == '小型企业':
dict['小型企业']+=i[4]
print("========商品子类别-客户,销售额==========")
print(type_sale_dict)
x1=[] #商品类别
y1 = [] #公司销售额
y2=[] #消费者销售额
y3=[] #小型公司销售额
for key,value in type_sale_dict.items():
x1.append(key)
for k,v in value.items():
if k == '公司':
y1.append(v)
if k == '消费者':
y2.append(v)
if k == '小型企业':
y3.append(v)
c=Bar()
c.add_xaxis(x1)
c.add_yaxis("公司销售额",y1)
c.add_yaxis("消费者销售额", y2)
c.add_yaxis("小型企业销售额", y3)
c.reversal_axis()
c.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
c.set_global_opts(
title_opts=opts.TitleOpts(title="商品子类别-客户,销售额"),
legend_opts=opts.LegendOpts(type_="scroll", pos_left="80%", orient="vertical"),
)
c.render("商品子类别-客户,销售额.html")
return c
# 客户-商品子类别,利润
def customer_profit_type(self):
to_drop = ['行 ID', '订单 ID', '发货日期', '邮寄方式', '客户 ID', '客户名称', '城市', '省/自治区', '国家',
'产品 ID', '类别', '产品名称', '地区', '数量', '折扣','销售额']
res = self.newRows.drop(to_drop, axis=1)
type_sale_dict = {} # 利润
for i in res.itertuples():
dict = {}
if i[3] not in type_sale_dict.keys():
dict[i[2]]=i[4]
type_sale_dict[i[3]]=dict
else:
dict=type_sale_dict[i[3]]
if i[2] not in dict.keys():
dict[i[2]]=i[4]
else:
if i[2] == '公司':
dict['公司']+=i[4]
if i[2] == '消费者':
dict['消费者']+=i[4]
if i[2] == '小型企业':
dict['小型企业']+=i[4]
print("========商品子类别-客户,利润==========")
print(type_sale_dict)
x1=[] #商品类别
y1 = [] #公司利润
y2=[] #消费者销售额
y3=[] #小型公司销售额
for key,value in type_sale_dict.items():
x1.append(key)
for k,v in value.items():
if k == '公司':
y1.append(v)
if k == '消费者':
y2.append(v)
if k == '小型企业':
y3.append(v)
c=Bar()
c.add_xaxis(x1)
c.add_yaxis("公司利润",y1)
c.add_yaxis("消费者利润", y2)
c.add_yaxis("小型企业利润", y3)
c.reversal_axis()
c.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
c.set_global_opts(
title_opts=opts.TitleOpts(title="商品子类别-客户,利润"),
legend_opts=opts.LegendOpts(type_="scroll", pos_left="80%", orient="vertical"),
)
c.render("商品子类别,客户,利润.html")
return c
运行结果
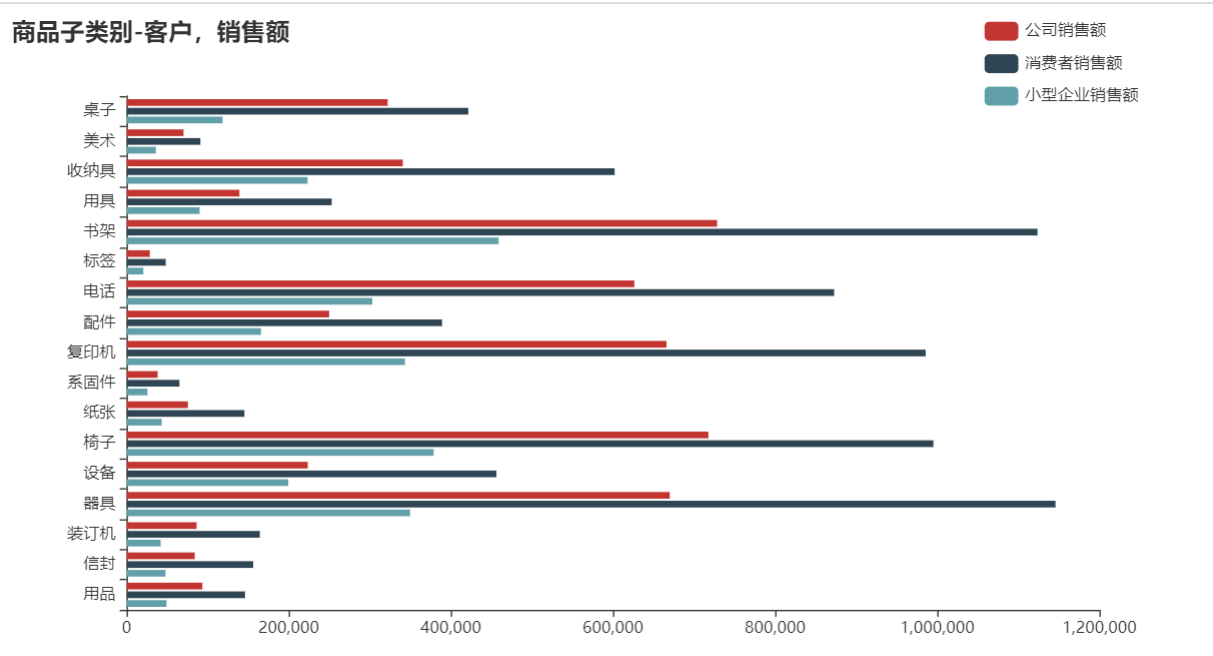
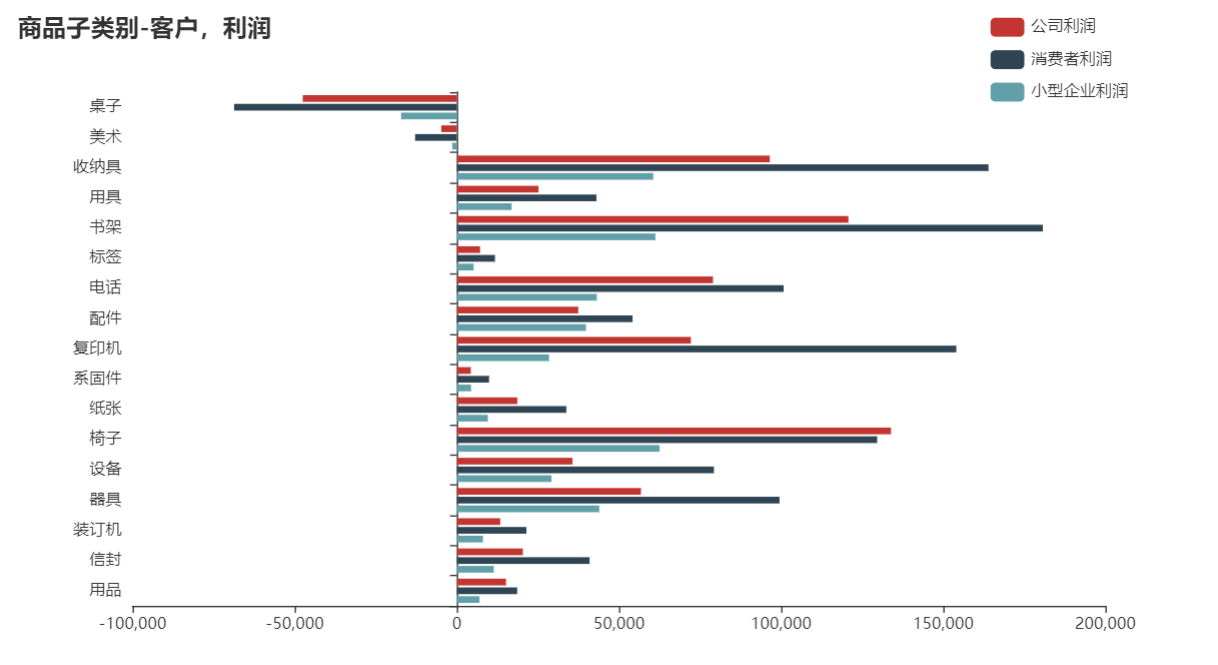
分析
通过商品类别,客户,销售额的关系可以发现,大部分的商品中三种客户的销售额都按照消费者,公司,小型企业进行排序。销售额与利润排名在前的书架,复印机等都是消费者购买很多,在售卖时考虑到给消费者客户多推荐书架、收纳具,复印机等商品。
构建RFM模型,分析2011年-2014年超市的客户类型占比,以及消费金额,消费金额占比
客户RFM模型的三个重要指标:
- R(Recency):最近一次消费时间间隔,指用户最近一次消费时间距离现在的时间间隔;
- F(Frequency):消费频率,指用户一段时间内消费了多少次;
- M(Monetary):消费金额,指用户一段时间内的消费金额。
RFM 模型多用于精细化运营服务。单看 R、F、M 三个指标,其本身已经具备了一定的参考性:
根据RFM模型将客户分为8种类型
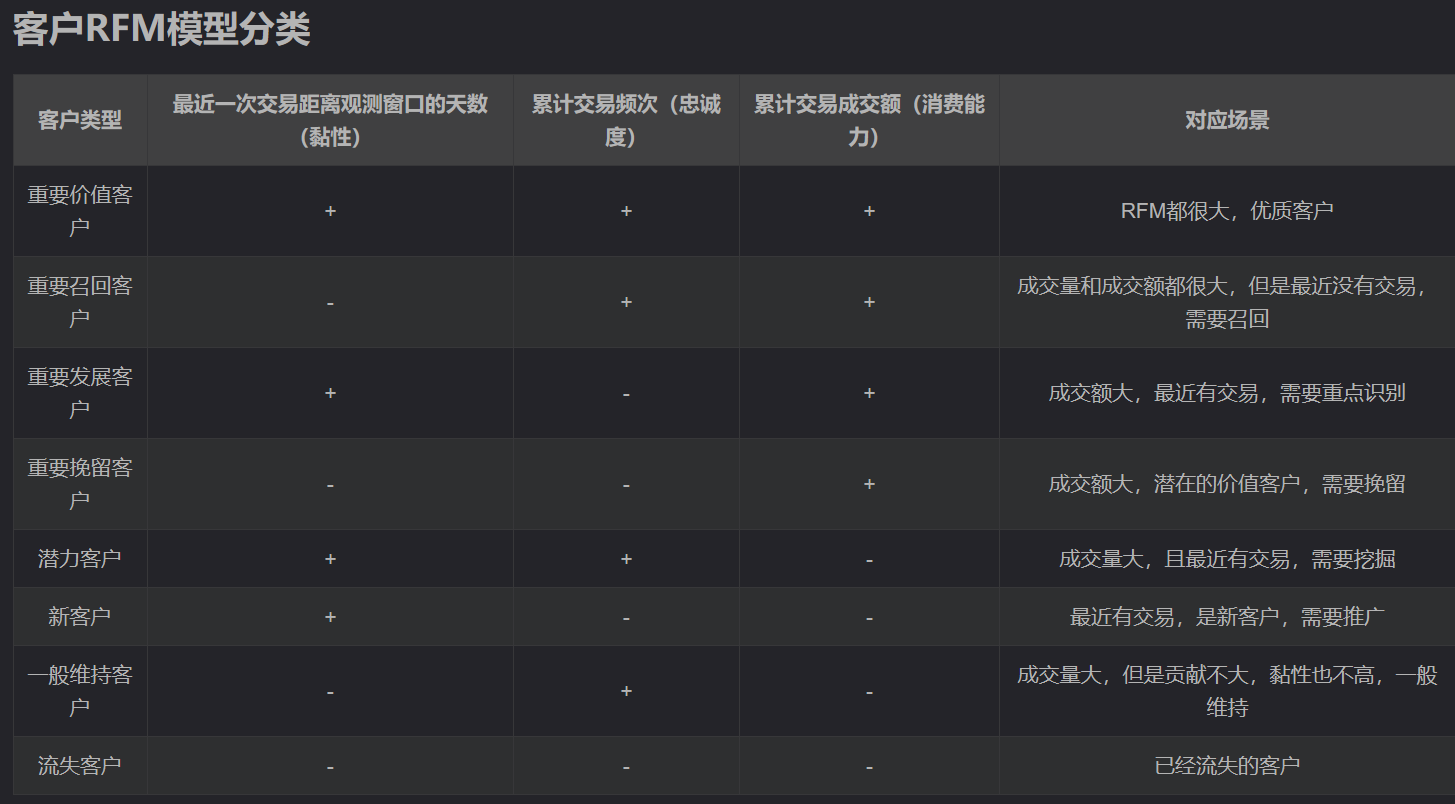
步骤: 对数据集的每条记录计算R,F,M的值,并对其进行总分统计分级,按照R,F,M的顺序赋予不同权重进行分级,这里采用R的优先级最高,即我们比较关心客户的最近一次消费时间间隔。
构建RFM模型
class RFMCustomer:
def __init__(self):
#filename='F:\桌面\数据可视化\计卓班 数据可视化技术 大作业\计卓班 数据可视化技术 大作业\电商行业-超市销售数据分析7.0版本\超市销售分析.xls'
filename='超市销售分析.xls'
data = pd.read_excel(io=filename, sheet_name=0, header=0)
# 去空
data.dropna(axis=0, how='any', inplace=True) # axis=0表示index行 "any"表示这一行或列中只要有元素缺失,就删除这一行或列
#定义用户类别
def transform_label(x):
if x == 111:
label = '重要价值客户'
elif x == 110:
label = '潜力客户'
elif x == 101:
label = '重要发展客户'
elif x == 100:
label = '新客户'
elif x == 11:
label = '重要唤回客户'
elif x == 10:
label = '一般客户'
elif x == 1:
label = '重要挽留客户'
elif x == 0:
label = '流失客户'
return label
df=data
df = df[['订单 ID','订单日期','客户 ID','销售额']]
r = df.groupby('客户 ID')['订单日期'].max().reset_index()
r['R'] = (pd.to_datetime('2015-1-1') - r['订单日期']).dt.days #因为数据集的数据都是2011年-2014年的,所以我们设置2015-1-1即刚好能研究2014年之前的数据
r = r[['客户 ID','R']] #R值:最近一次消费(Recency)
#每一条记录代表一种商品,有些订单有多种商品,原始数据会把订单展开成多行,将其算成一次购买记录,即频次算1次
dup_f = df.groupby(['客户 ID','订单 ID'])['订单日期'].count().reset_index()
f = dup_f.groupby('客户 ID')['订单日期'].count().reset_index()
f.columns = ['客户 ID','F'] #F值:消费频率(Frequency)
sum_m = df.groupby('客户 ID')['销售额'].sum().reset_index()
com_m = pd.merge(sum_m,f,left_on = '客户 ID',right_on = '客户 ID',how = 'inner')
#计算用户平均支付金额
com_m['M'] = com_m['销售额'] / com_m['F'] #M值:消费金额(Monetary)
rfm = pd.merge(r,com_m,left_on = '客户 ID',right_on = '客户 ID',how = 'inner')
rfm = rfm[['客户 ID','R','F','M']]
#就要对这些次数进行分级,相应的频次对应相应的等级,划分出用户价值。RFM模型分级一般分3到5级,我这里采用5分法。
#quantile是分位数函数
#给RFM的每个值进行打分评级
rfm['R-SCORE'] = pd.cut(rfm['R'],bins = rfm['R'].quantile(q=np.linspace(0,1,num=6),interpolation='nearest'),
labels = [5,4,3,2,1],right = False).astype(float)
rfm['F-SCORE'] = pd.cut(rfm['F'],bins = rfm['F'].quantile(q=np.linspace(0,1,num=6),interpolation='nearest'),
labels = [1,2,3,4,5],right = False).astype(float)
rfm['M-SCORE'] = pd.cut(rfm['M'],bins = rfm['M'].quantile(q=np.linspace(0,1,num=6),interpolation='nearest'),
labels = [1,2,3,4,5],right = False).astype(float)
#R值打分是从5到1,而其他值是从1到5呢
#因为R值是距今的天数,所以值越大,离现在越久,所以分数越低,价值越低,因此标签是倒过来的;而其他的指标,值越大,越有价值,比如消费额度越高越好,所以是顺序进行打分。
rfm['R>mean'] = (rfm['R-SCORE'] > rfm['R-SCORE'].mean()) * 1 #当前行的R-SCORE是否大于R-SCORE,是的话置1
rfm['F>mean'] = (rfm['F-SCORE'] > rfm['F-SCORE'].mean()) * 1
rfm['M>mean'] = (rfm['M-SCORE'] > rfm['M-SCORE'].mean()) * 1
#对RFM总分进行统计分级
#因为在不同业务中,每个指标的重要性是不一样的,有的阶段,频率很重要,有的阶段,销售额很重要。
#这里倾向于R,最近一次消费时间间隔
rfm['Score'] = (rfm['R>mean'] * 100) + (rfm['F>mean'] * 10) + (rfm['M>mean'] * 1)
#根据rfm总分对每个用户进行贴标签,然后分层运营
rfm['客户类型'] = rfm['Score'].apply(transform_label)
#统计不同类型客户的消费金额以及金额占比
count = rfm['客户类型'].value_counts().reset_index()
count.columns = ['客户类型','人数']
count['人数占比'] = count['人数'] / count['人数'].sum()
rfm['购买总金额'] = rfm['F'] * rfm['M']
mon = rfm.groupby('客户类型')['购买总金额'].sum().reset_index()
mon.columns = ['客户类型','消费金额']
mon['金额占比'] = mon['消费金额'] / mon['消费金额'].sum()
self.result = pd.merge(count,mon,left_on = '客户类型',right_on = '客户类型')
print( self.result)
print("====================================")
客户分层结构,8种类型客户人数占比
def make_pie(self):
# 这里为了美观和交互性,使用pyecharts做南丁格尔玫瑰图,需要将numpy.int转化成python原生态int
customer_category_sum = []
for i in self.result['人数'].values:
customer_category_sum.append(int(i))
customer_list = [list(z) for z in zip(self.result['客户类型'], customer_category_sum)]
# 绘制饼图
pie = (
Pie(init_opts=opts.InitOpts(theme=ThemeType.MACARONS,bg_color='white'))
.add('',customer_list,
radius=['30%','75%'],
rosetype='radius',
label_opts=opts.LabelOpts(is_show=True))
.set_global_opts(title_opts=opts.TitleOpts(title='顾客分层结构',pos_left='center'),
toolbox_opts=opts.ToolboxOpts(is_show=True),
legend_opts=opts.LegendOpts(orient='vertical',pos_right='0%',pos_top='30%'))
.set_series_opts(label_opts=opts.LabelOpts(formatter='{b}:{d}%')))
pie.render("顾客分层结构.html")
return pie
运行结果
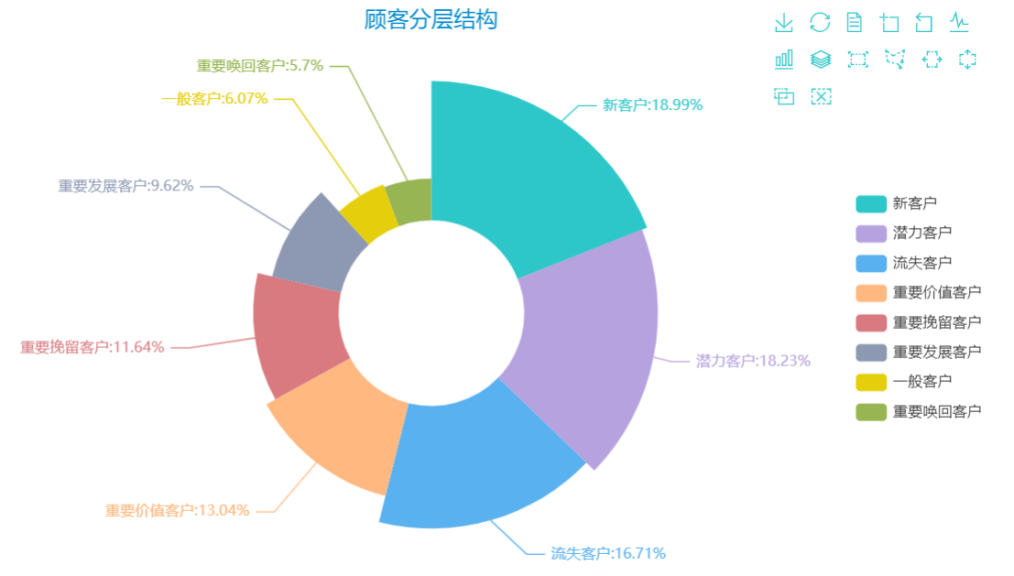
分析
- 可以看到潜力客户与新客户占据了最大的一部分,潜力客户特点:成交量大,且最近有交易,需要挖掘,新客户特点:最近有交易,是新客户,需要推广。这里统计了2011年-2014年内的用户进行RFM模型构建,且2011年至2014年的销售额都是增长的,说明我们的超市有前景市场在。
- 接着占比第三大的是流失客户,占比为16.71%,需要值得我们重视
- 重要价值客户占比为13.04%,排第四,重要价值客户:RFM都很大,优质客户。贡献了主要的销售额,可以针对他们进行针对性的定制性、个性化服务
各类型客户的消费金额以及占比
def make_bar(self):
##金额占比累加
self.result.sort_values(by=['消费金额'],ascending=False,inplace=True)
sales_rate=[]; a=0
for i in self.result.金额占比:
a +=i
sales_rate.append(a)
self.result['金额占比累加'] = sales_rate
print(self.result)
# 建立左侧纵坐标画板
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False
#绘制带子图
fig, ax1 = plt.subplots(figsize=(16, 10)) #ax:子图对象 在Figure对象中可以包含一个或者多个Axes对象。每个Axes(ax)对象都是一个拥有自己坐标系统的绘图区域
# 画柱状图图
s = plt.bar(self.result.客户类型, self.result.消费金额, alpha=0.5, label='消费金额',width=0.7)
# 显示左侧纵坐标
ax1.set_ylabel('消费金额', fontsize=10)
plt.yticks(range(0, 6000000, 500000), #50万为单位增长
['0', '50W', '100W', '150W', '200W', '250W', '300W', '350W', '400W', '450W', '500W', '550W'])
plt.tick_params(labelsize=10)
# 显示文字
for x1, y1 in zip(self.result.客户类型, self.result.消费金额):
plt.text(x1, y1, str(int(y1 / 10000)) + 'W', ha='center', fontsize=10)
ax2 = ax1.twinx() #twinx()一个图两个不同的y轴
# # 画折线图
line = ax2.plot(self.result.客户类型, self.result.金额占比累加, linewidth=3, marker='o', c='y', ms=10)
# # 折线图显示标识
for a, b in zip(self.result.客户类型, self.result.金额占比累加):
ax2.text(a, b, "%.0f" % (100 * b) + '%', ha='center', fontsize=10)
ax2.set_ylabel('金额占比累加', fontsize=12, rotation=270)
plt.ylim(0, 1.05)
plt.tick_params(labelsize=10)
ax2.set_title("各类型顾客消费额及其累加占比", fontsize=12)
plt.savefig("各类型顾客消费额及其累加占比.png", dpi=300)
plt.show()
运行结果
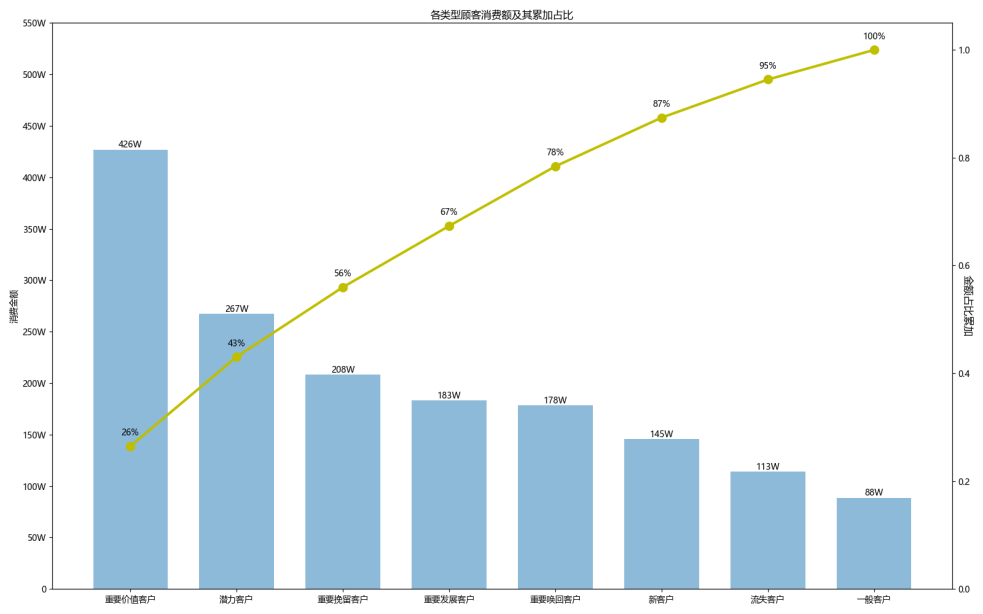
分析
各类型客户的消费金额占比为:
重要价值客户:26%,
潜力客户:17%
重要挽留客户:13%
重要发展客户:11%
重要召回客户:11%
新客户:9%
流失客户:8%
一般客户:5%
- 重要价值客户贡献金额最高,26%的比例,可见该超市是有一群稳定的老顾客,经常来超市消费,是销售额的主要来源,潜力客户和重要价值客户,占了销售额的43%,而其他6类用户的贡献金额较少,每个类群的客户贡献金额都不超过销售额的15%
- 人数占比最多的新客户,贡献金额只有9%左右,新用户的消费金额不怎么高,则我们需要关注于吸引新用户的兴趣,提供免费试用活动,增加客户忠诚度
- 应该着重将运营的重心放在重要价值客户,如何留住核心收入来源的重要价值用户,如提供VIP服务。通过推荐不同产品来扩大潜力顾客的购买金额,是现阶段的任务。
结论
1.从省的利润看出沿边沿海地区的利润不错,多为正利润。而为负利润的地区多为内陆地区,如四川、甘肃、湖北地区。从各市的利润可看出,在内蒙古、四川、甘肃省的有销售的城市比较少,所以这几个省的利润是负利润受销售城市的影响。但浙江、江苏、辽宁省份销售的城市多,但这三个省是负利润,则说明这三个省的销售利润是真正的负利润,需要重视。
2. 销售额与利润的的正相关性最强,类别_家具与类别_办公品的负相关性最强。
3. 月度销售额与月度利润有一定规律,在5,6月份时销售额大涨,在7月份时大跌。而后8月份有回升,推测应该在年中时公司需要进行采购办公用品,则这些销售额受办公用品的影响呈季节性的变化。
4.办公用品类卖的最多的时剪刀,家具类热销榜排名前10的都是桌子,但结合之前的商品类别-利润情况中,桌子是负利润的,则应该考虑桌子成本因素。技术类别中,销量top10中打印机占50%,则进货时也可考虑多进打印机。
5. 通过销售额,利润可以看出消费者类型用户是我们的主要客户,接着是公司,然后是小型企业。销售额与利润排名在前的书架,复印机等都是消费者购买很多,在售卖时考虑到给消费者客户多推荐书架、收纳具,复印机等商品。
6. 统计了2011年-2014年内的用户进行RFM模型构建,可以看到潜力客户与新客户占据了最大的一部分,占比为37.22%,且2011年至2014年的销售额都是增长的,说明我们的超市有前景市场在。重要价值客户贡献金额最高,26%的比例,是销售额的主要来源,应该着重将运营的重心放在重要价值客户,如何留住核心收入来源的重要价值用户如提供VIP服务以及通过推荐不同产品来扩大潜力顾客的购买金额,是现阶段的任务。人数占比最多的新客户,贡献金额只有9%左右,新用户的消费金额不怎么高,则我们需要关注于吸引新用户的兴趣,提供免费试用活动,增加客户忠诚度。
参考
本项目用于大数据可视化大作业,参考的代码以及分析主要如下,如有涉及侵权请联系我,会删除该文章。
【1】超市数据分析
【2】作业一 | Tableau可视化分析 | 超市数据分析
【3】客户细分——RFM模型
【4】Tableau | 超市销售数据可视化分析 - 知乎 (zhihu.com)
【5】电商客户价值细分 - RFM 模型(中)
【6】我是怎么利用Python+RFM模型高效了解用户!
【7】用决策树实现分类(预测)实战(python)
【8】Python | 简单线性回归(数据学习时长与分数)
代码
代码存放在github上,Github链接
或搜 wangyuna7723/SupermarketAnalysis

 浙公网安备 33010602011771号
浙公网安备 33010602011771号