Python基础 | 2.变量、内存表现、引用计数
部分内容引用自:https://www.runoob.com/python/python-variable-types.html
陈儒:《Python源码剖析》
--->>>在 Python 中,一切皆为对象。
先前知识:
* 基本数据类型:
* Number(数字)
* String(字符串)
* List(列表)
* Tuple(元组)
* Set(集合)
* Dictionary(字典)
* 两个内置函数
* id()
* 函数返回对象的唯一标识符,标识符是一个整数。
* CPython 中 id() 函数用于获取对象的内存地址。(CPython是Python基于C语言的官方解释器)
* type(object)
* 只有第一个参数则返回对象的类型,暂不考虑三个参数的情况。
* sys.getsizeof()
* 使用这个函数可以查看内存占用情况,使用前需要先导入sys模块,详细使用下面有例子。
一、变量
1.变量的介绍
- 在 第0.3节:Python环境搭建 中,实现了第一个 hello,world 程序。现在对其进行改进:
>>> # 交互式 >>> message = 'hello,world!' >>> print(message) hello,world! >>>- 在这里,设置了一个 变量message,变量存储在内存中的值,这就意味着在创建变量时会在内存中开辟一个空间。
- 在上述例子中,在创建变量message时,开辟了一块内存,存储了 字符串'hello,world!',而 赋值运算符"=" 将该字符串赋值给变量message(实际上是字符串在内存中的地址,后面详议)。
2.变量的使用
-
(1)Python 中的变量赋值不需要类型声明。
- 例如,在上述代码中,并未指定 变量messgae 是 字符串(str) 类型。
-
(2)每个变量在使用前无须定义,但都必须赋值,变量赋值以后该变量才会被创建。
- 例如,在上述代码中,直接将 字符串'hello,world!' 赋值给 变量message。否则将无法创建,如下面例子,显示 变量message_novalue 未定义。
>>> # 交互式 >>> message_novalue Traceback (most recent call last): File "<stdin>", line 1, in <module> NameError: name 'message_novalue' is not defined >>>
- 例如,在上述代码中,直接将 字符串'hello,world!' 赋值给 变量message。否则将无法创建,如下面例子,显示 变量message_novalue 未定义。
-
(3)每个变量在内存中创建,都包括变量的标识,名称和数据这些信息。
- 在创建变量时,毫无疑问要分配空间,因此需要知道要创建多大的空间。
- 不同数据类型的变量(也即对象)需要分配不同的存储空间。
- 变量在内存中创建时,要包含标识、名称、数据等信息。
-
(4)等号(=)用来给变量赋值。
-
(5)等号(=)运算符左边是一个变量名,等号(=)运算符右边是存储在变量中的值。
3.变量的命名
一切都是为了代码的可读性。
- (1)变量的命名规则
- a.变量名只能包含字母、数字和下划线。变量名支持字母或下划线打头,但不能使用数字开头。
- b.变量名不能包含空格,但可以使用下划线分隔其中的单词。
- c.不要将Python中关键字和函数名作为变量名。
- 关键字为以下这些:
>>> import keyword >>> keyword.kwlist ['False', 'None', 'True', 'and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'finally', 'for', 'from', 'global','if', 'import', 'in', 'is', 'lambda', 'nonlocal', 'not', 'or', 'pass', 'raise', 'return', 'try', 'while', 'with', 'yield'] >>> - d.变量名应该既简短又具有描述性。
- e.慎用小写字母 l 和大写字母 O ,防止被错看成数字 1 和 0 .
- (2)Python之父Guido推荐的规范
- lower_with_under
- 示例:
- name 比 n 好;student_name 比 s_n 好;name_length 比 length_of_student_name 好。
4.变量的数据类型转换
-
(1) Python数据类型转换的例子
>>> number_string = '996' >>> number_int = int(number_string) >>> print(number_string) 996 >>> type(number_string) <class 'str'> >>> print(number_int) 996 >>> type(number_int) <class 'int'> >>> print(number_int - 100) 896 >>>- 在上述例子中,变量number_string被赋值为 字符串'996';
- 使用 int() 将变量number_string 可以转变为 Int类型,并且赋值给 变量number_int;
- 可以看到,type(number_int)输出的结果是 int类型。并且可以直接与 数字100 进行减法运算,并且得到数值 896。
-
(2) 可以执行数据类型之间转换的几个内置函数
序号 函数 描述 1 int(x) 将x转换为一个整数 2 float(x) 将x转换到一个浮点数 3 complex(real [,imag]) 创建一个复数 4 str(x) 将对象 x 转换为字符串 5 repr(x) 将对象 x 转换为表达式字符串 6 eval(str) 用来计算在字符串中的有效Python表达式,并返回一个对象 7 tuple(s) 将序列 s 转换为一个元组 8 list(s) 将序列 s 转换为一个列表 9 set(s) 转换为可变集合 10 dict(d) 创建一个字典。d 必须是一个序列 (key,value)元组。 11 frozenset(s) 转换为不可变集合 12 chr(x) 将一个整数转换为一个字符 13 unichr(x) 将一个整数转换为Unicode字符 14 ord(x) 将一个字符转换为它的整数值 15 hex(x) 将一个整数转换为一个十六进制字符串 16 oct(x) 将一个整数转换为一个八进制字符串
二、变量及其赋值在内存中的表现
1.关于 变量 与 值 在内存中的对应示意图
- a.首先通过程序直观的看变量的值的内存地址【脚本式编程,具体详见下面的疑问3】
import sys a = 111 b = a c = 9999 d = 9999 print("the memory adress of a is:",id(a),";the memory size of a:",sys.getsizeof(a)) print("the memory adress of b is:",id(b),";the memory size of b:",sys.getsizeof(b)) print("the memory adress of c is:",id(c),";the memory size of c:",sys.getsizeof(c)) print("the memory adress of d is:",id(d),";the memory size of d:",sys.getsizeof(d)) e = 'Success is not final, failure is not fatal, it is the courage to continue that counts.' f = e print("the memory adress of e is:",id(e),";the memory size of e:",sys.getsizeof(e)) print("the memory adress of f is:",id(f),";the memory size of f:",sys.getsizeof(f)) # 输出结果为: the memory adress of a is: 9219712 ;the memory size of a: 28 the memory adress of b is: 9219712 ;the memory size of b: 28 the memory adress of c is: 140482770615120 ;the memory size of c: 28 the memory adress of d is: 140482770615120 ;the memory size of d: 28 the memory adress of e is: 140482771660288 ;the memory size of e: 135 the memory adress of f is: 140482771660288 ;the memory size of f: 135 - b.通过图片理解上述代码的内存情况
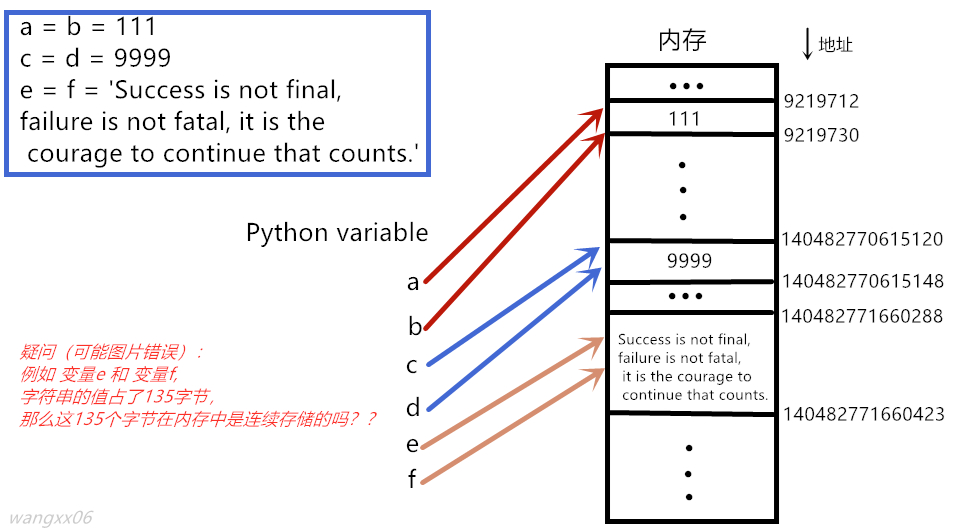
- 在该程序中,变量a与变量b、变量c与变量d、变量e和变量f 的值相同,变量指向同一个内存地址。(变量只存了值的地址信息,而不存具体的值)
- 存在疑问,在下面第三个疑问将提出。(关于大整数的问题,交互式与脚本式竟然不同???)
2.关于变量及其赋值在内存中的几个疑问
- a.第一个疑问:变量名和值是怎么在内存中存储的呢?
- 解答:变量名 在内存中并不存储,它只是内存地址的一个“别名”,给Python解释器看的;
- 解答:值 在内存中进行存储,在创建变量时,在内存中申请相应的空间。
- b.第二个疑问:不同数据类型的 值 在内存中申请空间时,申请空间大小情况是怎样的?(也可以理解为不同数据类型在 内存 中的存储情况)
- 解答:不同的数据类型申请内存的大小不相同,不同的对象需要不同的空间。并且,相同的数据类型,大小不一样时,申请的内存空间大小也是不相同的。
- 示例:以 int 和 string 举例(sys.getsizeof()可以查看对象的内存占用情况):
- vim 创建 neicun.py 文件,并进行以下编辑:
import sys number_zero = 0 number_small = 1 number_medium = 10000 number_big = 9999999999**999 string_one = 'a' string_short = 'hello' string_long = 'Success is not final, failure is not fatal, it is the courage to continue that counts.' print('number_zero:',sys.getsizeof(number_zero)) print('number_small:',sys.getsizeof(number_small)) print('number_medium:',sys.getsizeof(number_medium)) print('number_big:',sys.getsizeof(number_big)) print('string_one:',sys.getsizeof(string_one)) print('string_short:',sys.getsizeof(string_short)) print('string_long:',sys.getsizeof(string_long)) - 运行之后,得到以下结果
number_zero: 24 # 数字0申请24字节的内存空间 number_small: 28 # 数字1申请28字节的内存空间 number_medium: 28 # 数字10000申请28字节的内存空间 number_big: 4452 # 数字9999999999**999申请4452字节的内存空间 string_one: 50 # 单个字符 'a' 申请50字节的内存空间 string_short: 54 # 字符串 'hello' 申请54字节的内存空间 string_long: 135 # 字符串 'Success is ... that counts.' 申请135字节的内存空间 - 挖坑:由上面的例子可以看出,不同的数据类型,申请内存的情况完全不一样;以及相同的数据类型,大小或者长短不一样时,申请的内存大小都是不同的(数字1和数字10000申请的内存大小又是相同的)。那么他们是按照什么规则申请内存的呢??????????具体的情况将详细介绍在“数据类型单独介绍”时,详细探讨。
- vim 创建 neicun.py 文件,并进行以下编辑:
- c.第三个疑问: 在交互式编程和脚本式编程时,对于[-5,256]之外的数字,为什么两个值相等的变量的地址信息不相同???
- 脚本式编程:
a = 999 b = a print(id(a),id(b)) c = 888 d = 888 print(id(c),id(d)) # 输出结果为: 140561190291568 140561190291568 140561190291408 140561190291408 - 交互式编程:
>>> a = 999 >>> b = a >>> print(id(a),id(b)) 140333724178544 140333724178544 >>> c = 888 >>> d = 888 >>> print(id(c),id(d)) 140333723073104 140333723073232 >>> - 在上述两种编程方式中,变量间互相赋值时,对于大数字的地址相同;但是,在交互式编程中,当两个变量分别赋予相同的值(大数字)时,两个变量的地址不相同。
- 为什么会出现这种情况呢??? 【挖坑】将在介绍《基本数据类型——数字》时,深入探讨,在这先挖个坑啦,希望可以补上。。。
- 脚本式编程:
- d.第四个疑问:简单介绍,内存中保存的值什么时候会被清理呢?
- 请看下面的引用计数,粗略介绍Python的内存管理。
- e.第五个疑问:Python的可变数据类型和不可变数据类型,以及深copy与浅copy,将在介绍完基本数据类型之后再总结。
三、引用计数
0.Python中一切皆对象
- 在Python的世界中,一切都是对象,一个整数是一个对象,一个字符串是一个对象,甚至,类型也是一种对象,整数类型是一种对象,字符串类型也是一种对象。换句话说,面向对象理论中的“类”和“对象”这两个概念在Python中都是通过Python内的对象来创建的。
- 在Python中,已经预先定义了一些类型对象,例如int类型、string类型、dict类型等等,这些我们称之为内建类型对象。这些类型对象实现了面向对象中“类”的概念,这些内建类型对象通过“实例化”,可以创建内建类型对象的实例对象,比如int对象、string对象、dict对象等等。类似的,这些实例对象可以认为是面向对象理论中“对象”这个概念在Python中的体现。
- 同时,Python还允许程序员通过 class A(object) 这样的表达式自己定义类型对象。基于这些类型对象,同样可以进行“实例化”操作,创建的对象称之为“实例对象”。
1.Python对象机制的基石————PyObject
- 在Python中,所有的东西都是对象,而所有的对象都有相同的内容,这些内容在PyObject中定义,PyObject是整个Python对象机制的核心。
[object.h] type_def struct_object { PyObject_HEAD } PyObject; - 这个结构是Python对象机制的核心基石,从代码中可以看出,Python对象的秘密都隐藏在PyObject_HEAD这个宏中。
[object.h] #ifdef Py_TRACE_REFS /* Define pointers to support a doubly-linked list of all live heap objects. */ #define _PyObject_HEAD_EXTRA \ struct _object *_ob_next; \ struct _object *_ob_prev; #define _PyObject_EXTRA_INIT 0, 0, #else #define _PyObject_HEAD_EXTRA #define _PyObject_EXTRA_INIT #endif /* PyObject_HEAD defines the initial segment of every PyObject. */ #define PyObject_HEAD \ _PyObject_HEAD_EXTRA \ Py_ssize_t ob_refcnt; \ struct _typeobject *ob_type; - 在实际发布的Python中,PyObject的定义非常简单:
[object.h] typedef struct _object { int ob_refcnt; struct _typeobject *ob_type; } PyObject; - 在PyObject的定义中,整型变量ob_refcnt与Python的内存管理机制有关,它实现了基于引用计数的垃圾收集机制。对于某一个对象 A,当有一个新的PyObject引用该对象时,A的引用计数应该增加;而当这个PyObject *被删除时,A的引用计数应该减少,当A的引用计数减少到0时,A就可以从堆上删除,以释放出内存供别的对象使用。
2.引用计数
引言:在C或者C++中,程序员被赋予了极大的自由,可以任意地申请内存,但是权力的另一面是责任,程序员必须负责将申请的内存释放,并释放无效指针。这也是万恶之源,大量内存泄漏和悬空指针的bug由此而生。现代的开发语言中一般都选择由语言本身负责内存的管理和维护,即采用了垃圾收集机制,比如Java和C#等等,不仅提升了开发效率,也减少了bug的产生。Python也内建了垃圾收集机制,而引用计数正是垃圾收集机制的一部分。
- 1.Python通过对一个对象的引用计数的管理来维护对象在内存中的存在与否。我们知道在Python中每一个东西都是一个对象,都有一个ob_refcnt变量。这个变量维护着该对象的引用计数,从而也最终决定着该对象的创建与消亡。
- 2.在Python中,主要是通过 Py_INCREF(op) 和 Py_DECREF(op) 两个宏来增加和减少一个对象的引用计数。当一个对象的引用计数减少到0之后,Py_DECREF将调用该对象的析构函数来释放该对象所占的内存和系统资源。注意这里的“析构函数”借用了C++的词汇,实际上这个析构函数是通过在对象对应的类型对象中定义的一个函数指针来指定的,就是那个tp_dealloc。
- 3.在一个对象的引用计数减为0时,与该对象的析构函数就会被调用,但是要特别注意的是,调用析构函数并不意味着最终一定会free释放内存,如果真是这样的话,那频繁的申请、释放内存空间会使Python的执行效率大打折扣。一般来说,Python中大量采用了内存对象池的技术,使用这种技术可以避免频繁地申请和释放内存空间。因此在析构时,通常都是将对象占用的空间归还到内存池中。
3.通过例子解释引用计数
# 先前知识
# sys.getrefcount()函数可以用来查看对象的引用次数。
# sys.getrefcount()在使用时,也被记为一次引用,但是引用之后立刻自动销毁。
-
a.整数范围在[-5,256]的引用次数
import sys a = 1 b = a print(sys.getrefcount(a)) # 输出结果为 133- 在《基本数据类型——数字》时会详细介绍,这里简单讲,Python解释器会在启动时创建出小整数池,范围是[-5,256],该范围内的小整数对象是全局解释器范围内被重复使用,永远不会被垃圾回收机制回收。[-5,256]范围内的数字也同时被Python内部引用着。因此输出的引用次数结果比较大。
-
b.整数数字较大时的引用次数
>>> a = 999 >>> b = a >>> import sys >>> print(sys.getrefcount(a)) 3 >>>- 在这里,数据 999 被引用了3次,分别是 变量a、变量b、以及sys.getrefcount(a),因此输出引用次数是3。
-
c.对上述b中的代码进行改进
>>> import sys >>> a = 999 >>> b = a >>> print(sys.getrefcount(a)) 3 >>> b = 888 >>> print(sys.getrefcount(a)) 2 >>>- 第一:可以看出来sys.getrefcount()函数使用之后,自动结束对999的引用。
- 当b被赋予其他值时,b不再引用999,转而引用888,因此,此时的999引用次数从3减少为2。
-
d.创建一个类,并实例化,查看引用情况。
import sys class Dog(object): pass wangcai = Dog() print(sys.getrefcount(wangcai)) # 输出结果 2- 在上述例子中,wangcai 引用了一次 Dog()类实例化后在内存中的地址,并且 sys.getrefcount(wangcai) 又是对它的一次引用,因此,输出结果是2.
本篇博文如有错误,欢迎您的指出。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号