

hive--学习
一:什么是hive (面试题)
1.hive是数据仓库建模的工具之一
2.我们可以向hive传入一条交互式的sql,在海量数据中查询分析得到结果的平台
hive 的特点
1.可扩展性
hive可以自由的扩展集群的规模,一般情况下不需要重启服务
2.延展性
hive支持自定义函数,用户可以根据自己的需求实现自己的函数
3.容错性
即使节点出现错误,sql仍然可以完成执行。
hive的优缺点:
优点:
1.操作接口采用类sql语法,提供快速开发的能力(简单容易上手)
2.避免了去写mapreduce,减少开发人员的学习成本
3.hive的延迟性较高,因此hive常用于数据分析,适用于是实时性要求不高的场合
4.hive对处理大数据有优势,hive的执行延迟比较高。
5.hive支持用户自定义函数。可以根据自己的需求实现自己的函数。
6.集群可自由扩展,具有良好的容错性,节点出现问题sql仍可以完成执行
缺点:
1.hive的hql表达能力很有限
(1)迭代式算法无法表达(反复调用,mr之间独立,只有一个map 一个reduce,反复开关)
(2) 数据挖掘方面不擅长
2.hive的效率比较低
(1)hive 自动生成的mapreduce作业,通常情况下不够智能化
( hive将sql命令转化为mapreducer作业时,往往会预设一些规则或者模板,按照规则分配一定数量的map任务和reduce任务,但是实际情况,hive自动生成机制很难做到根据这些实时变化的情况去自适应地调整 Map 和 Reduce 任务的数量,可能导致资源利用不充分)
hive和mysql什么区别?
hiveql SQL
数据存储位置 HDFS 本地FS
数据格式 用户定义 系统决定
执行 mapreduce Executor
执行延迟 高 低
可扩展性 高 低
数据规模 大 小
hive 的应用场景:日志分析
hive架构
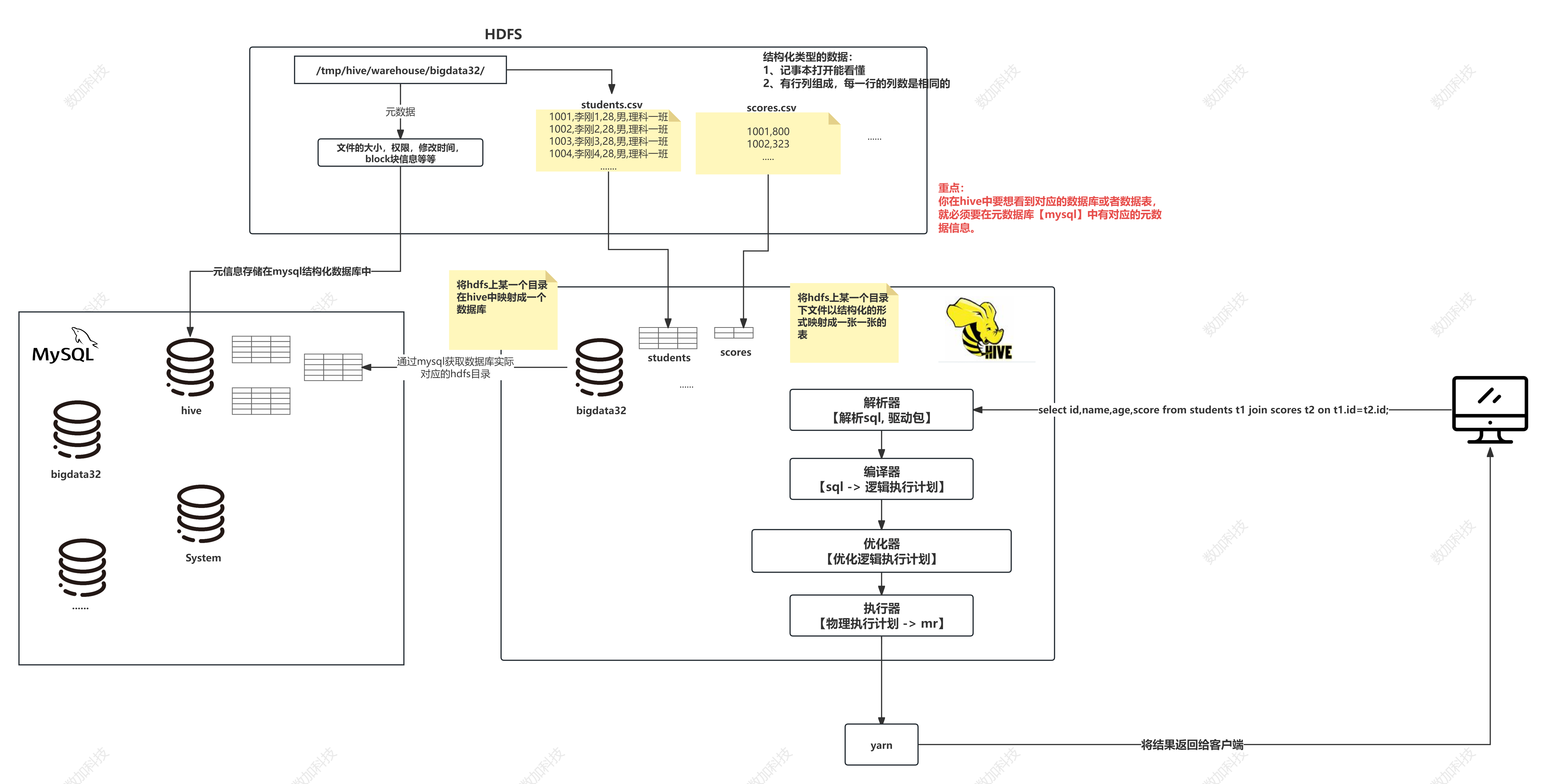
存储于HDFS上的元数据(包括文件的大小,权限,修改时间,block块的信息等等)需要是结构化数据才可以存储在mysql结构化数据库中
结构化数据:
1.记事本打开能看懂
2.有行列组成,每一行的列数是相同的
hive 通过MySQL获取数据库实际对应的hdfs目录,将hdfs上某一个目录在hive映射成一个数据库,并且将hdfs上某一个目录下文件以结构化的形式映射成一张张表。
重点:在hive中想看到对应的数据库或者是数据表,必须在元数据库中要有对应的元数据信息。
面试题:sql语句是如何转化成MR任务的?
客户端将sql请求发送到hive上,
1.通过解析器将SQL字符串转换成抽象语法树AST(从3.x版本之后,转换成一些的stage),
2.再通过编译器将AST编译(从3.x版本之后,转换成一些的stage)生成逻辑执行计划。
3.优化器:对逻辑执行计划进行优化
4.执行器:把逻辑执行计划转换成可以运行的物理计划对于hive就是MR
通过yarn将结果返回给客户端
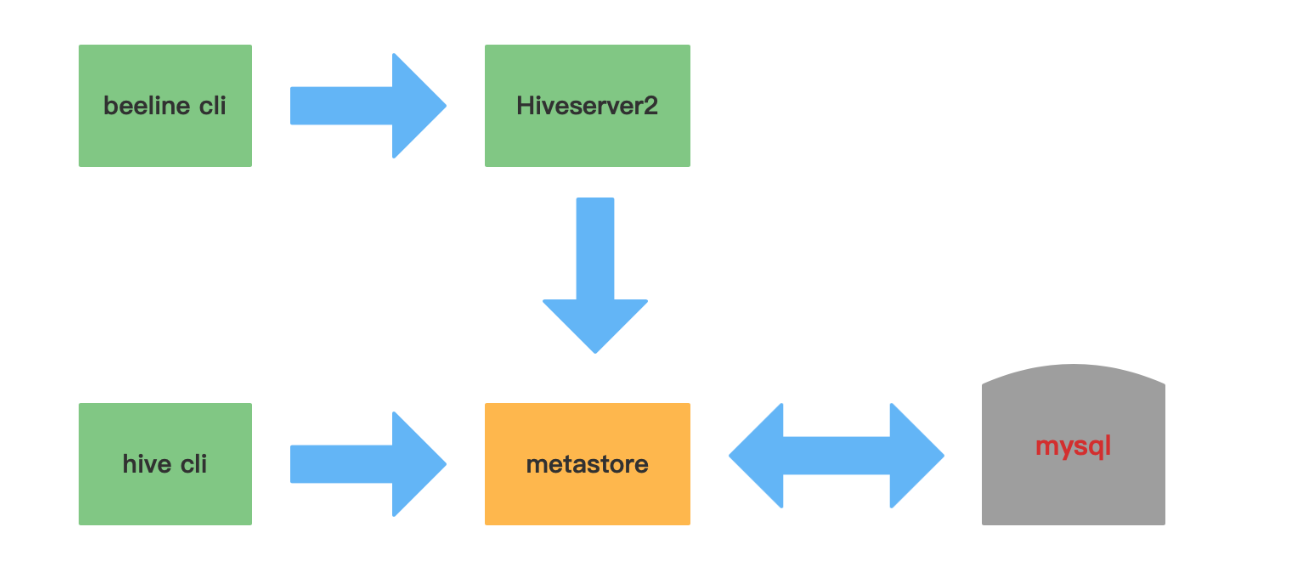
Hive的三种交互方式
1.第一种交互方式:shell交互Hive,用命令hive启动一个hive的shell命令行,在命令行中输入sql或者命令来和Hive交互。
服务端启动metastore服务(后台启动):
nohup hive --service metastore >> /usr/local/soft/hive-3.1.2/startlogs/metastore-service.log &
进入命令:hive
退出命令行:quit;
2.第二种交互方式:hive启动一个服务器,对外界提供服务,其他机器可以通过客户端,通过协议连接服务器,来完成访问操作
nohup hiveserver2 >> /usr/local/soft/hive-3.1.2/startlogs/hiveserver2.log &
需要稍等一下,启动服务需要时间:
进入命令:1)先执行: beeline ,再执行: !connect jdbc:hive2://master:10000
2)或者直接执行: beeline -u jdbc:hive2://master:10000 -n root
退出命令行:!exit
3.第三种交互方式:使用 –e 参数来直接执行hql的语句(bin/hive -e "show databases;")
使用 –f 参数通过指定文本文件来执行hql的语句
特点:执行完sql后,回到linux命令行。
hive -f hive.sql
hive cli和beeline cli的区别
基础数据类型(不区分大小写)
BIGINT long
DECIMAL(precision,scale) 10进制精确数字类型。
STRING 字符串类型
TIMESTAMP 与时区无关的时间戳类型
复杂的数据类型
数组(ARRAY)、映射(MAP)、结构体(STRUCT)
点击查看代码
-- 创建包含数组、映射和结构体的表
CREATE TABLE complex_data_type_table (
id INT,
name STRING,
hobbies ARRAY<STRING>,
scores MAP<STRING, INT>,
personal_info STRUCT<age: INT, gender: STRING, address: STRING>
);
-- 插入数据示例
INSERT INTO complex_data_type_table VALUES
(1, 'Alice',
ARRAY('reading', 'painting'),
MAP('math', 90, 'english', 85),
NAMED_STRUCT('age', 25, 'gender', 'female', 'address', '123 Main St')
),
(2, 'Bob',
ARRAY('sports', 'music'),
MAP('math', 80, 'physics', 75),
NAMED_STRUCT('age', 30, 'gender', 'male', 'address', '456 Elm St')
);
-- 查询数组中的元素
SELECT id, name, hobbies[0] AS first_hobby
FROM complex_data_type_table;
-- 查询映射中的特定键值
SELECT id, name, scores['math'] AS math_score
FROM complex_data_type_table;
-- 查询结构体中的字段
SELECT id, name, personal_info.age AS age, personal_info.gender AS gender
FROM complex_data_type_table;
Hive的存储格式:
TextFile:是Hive默认文件存储格式,因为大多数情况下源数据文件都是以text文件格式保存
ORCFile:是有着很高的压缩比,不仅可以很大程度的节省HDFS存储资源,而且对数据的查询和处理性能有着非常大的提升
Parquet
RCFile

 浙公网安备 33010602011771号
浙公网安备 33010602011771号