

BUAA_OO_2022 Unit4 与课程总结
本单元作业架构设计
总体任务概述
初始化
在基本理解了UML类图、时序图和状态图的元素及其关系后,我发现UML图的元素具有鲜明的层次结构关系,下层元素所需要用到的id总是指向上层的元素。
| 类图 | 时序图 | 状态图 | |
|---|---|---|---|
| 第一层 | UmlClass、UmlInterface、UmlAssociationEnd | UmlInteraction | UmlStateMachine |
| 第二层 | UmlOperation、UmlAttribute、UmlGeneralization、UmlInterfaceRealization、UmlAssociation | UmlLifeline、UmlEndpoint | UmlRegion |
| 第三层 | UmlParameter | UmlMessage | UmlPseudostate、UmlState、UmlFinalState |
| 第四层 | UmlTransition | ||
| 第五层 | UmlEvent |
在初始化时,我也是通过五次遍历建立我所需要的模型图。
新增的类
这里我运用了需求导向的思想,根据查询指令的类型,设计出相应的方法。
例如,在计算类的属性的耦合度时,我需要得到其继承自各级父类所定义的属性。为此我需要定义一个获取其继承自各级父类的属性的方法,这个方法需要添加到这个类中。因此,我没有直接使用原有的UmlClass,而是定义了自己的MyClass,并在其中添加我需要的属性(如直接父类、属性)和方法(如获取其继承自各级父类的属性、计算类的属性的耦合度)。
而如果一个UML元素中不需要自定义属性和方法,那我们就没必要新建对应的My类,直接用官方包提供的类即可。
最终我hw15的类图如下(由于三次作业没有重构,这里省略了前两次作业的类图)
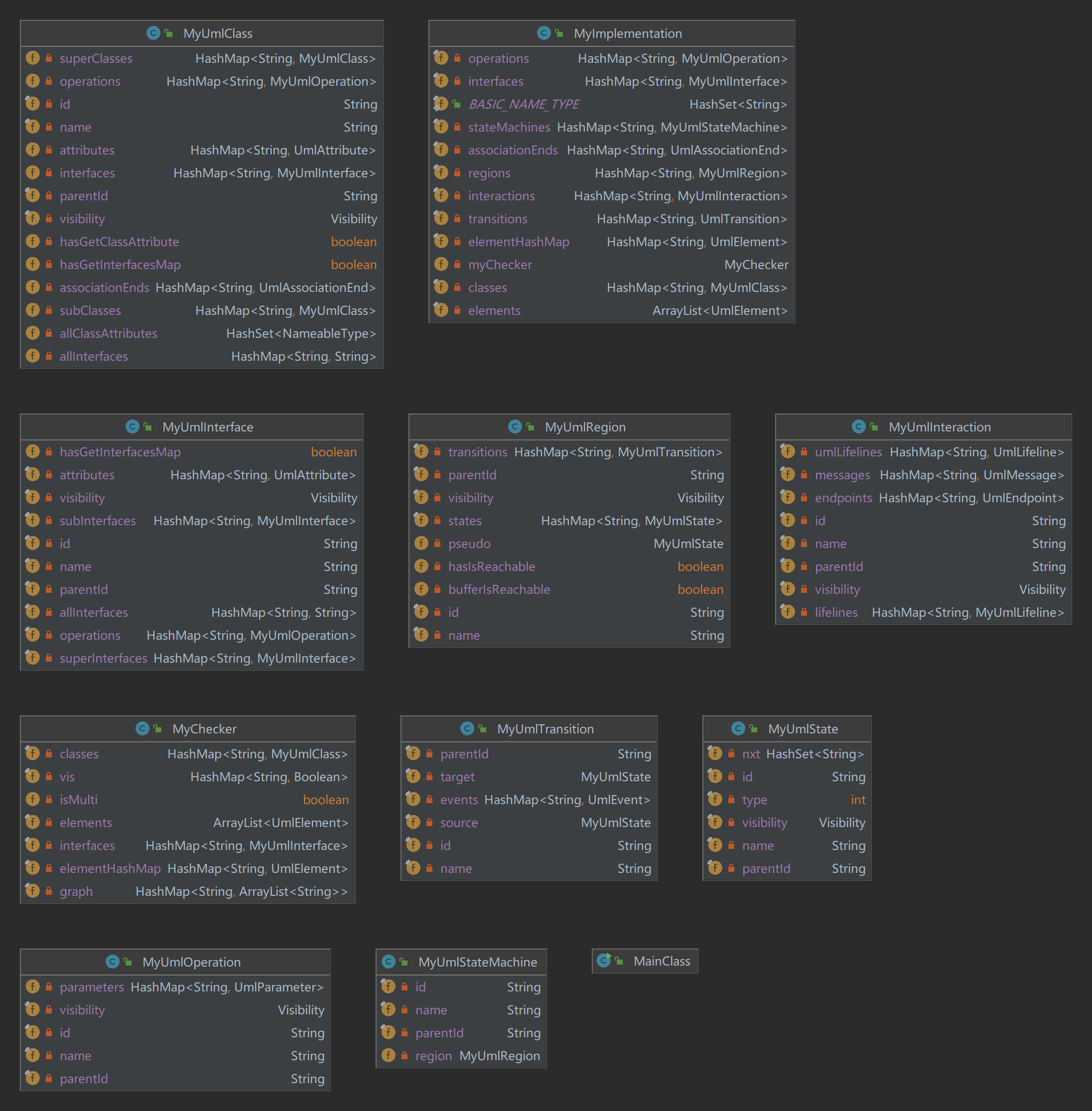
架构中的算法
hw13中,计算类实现的全部接口时,需要采用记忆化搜索(又名缓存)。具体的操作是,当某个类第一次调用某个查询类方法后,把这个方法的运行结果存在这个类中,并做一个标记;这样一来,当下一次再在这个类中调用这个查询类方法时,就可以直接返回结果,而不用做重复计算。具体代码如下:
public HashMap<String, String> getInterfacesMap() {
if (hasGetInterfacesMap) {
return allInterfaces;
}
for (MyUmlInterface umlInterface : interfaces.values()) {
allInterfaces.putAll(umlInterface.getInterfacesMap());
}
for (MyUmlClass umlClass : superClasses.values()) {
allInterfaces.putAll(umlClass.getInterfacesMap());
}
hasGetInterfacesMap = true;
return allInterfaces;
}
如果不用记忆化搜索,在遇到分层图时,时间复杂度会达到指数级,显然会超时。
hw14中,在计算关键路径时,需要用到bfs。
private boolean checkConnect(MyUmlState ban) {
HashMap<String, Boolean> vis = new HashMap<>();
for (MyUmlState state : states.values()) {
vis.put(state.getId(), false);
}
LinkedList<String> queue = new LinkedList<>();
queue.add(pseudo.getId());
// 初始状态不可能是ban
while (!queue.isEmpty()) {
String now = queue.getFirst();
queue.removeFirst();
if (vis.get(now)) {
continue;
}
vis.put(now, true);
if (states.get(now).getType() == 2) {
return true;
}
HashSet<String> nxt = states.get(now).getNxt();
for (String id : nxt) {
if (!vis.get(id) && (ban == null || !ban.getId().equals(id))) {
// 只能将还没访问过且不是禁止状态的id放进队列
queue.add(id);
}
}
}
return false;
}
hw15中,在计算循环继承和重复继承时,需要用到dfs。
private void dfs(String idx) {
ArrayList<String> nxt = graph.get(idx);
for (String idy : nxt) {
if (!vis.get(idy)) {
vis.put(idy, true);
dfs(idy);
} else {
isMulti = true;
}
}
}
架构中的其他细节
对于重名,我并没有预处理,而是定义了一个新的方法来实现通过name找到相应的类
private MyUmlClass getClassByName(String className)
throws ClassNotFoundException, ClassDuplicatedException {
MyUmlClass targetClass = null;
for (MyUmlClass umlClass : classes.values()) {
if (className.equals(umlClass.getName())) {
if (targetClass == null) {
targetClass = umlClass;
} else {
throw new ClassDuplicatedException(className);
}
}
}
if (targetClass == null) {
throw new ClassNotFoundException(className);
}
return targetClass;
}
四个单元中架构设计思维及OO方法理解的演进
第一单元
一单元作业中,我第一次实践了架构设计与迭代开发,体会到了一个好的架构对于工程代码的重要性。好的架构应当完全反应问题的原貌,这个架构不能仅仅满足于解决当前的问题需求,还应当考虑到后续的增量开发与迭代需求。
同时,在一单元中,我初步理解和掌握层次化设计,依照多项式的结构建立抽象层次,进而对多层次对象进行归一化管理。我也初步掌握了面向对象继承与多态的特性,通过方法的重写,使得同一个方法在不同层级的类中有不同的表现,从而达到由上层的抽象来实现无差别的引用和访问的归一化管理。
此外,我也初步理解了封装的思想。可以将一段需要重复使用的代码封装成一个方法,也可以将一组在语义上关联紧密的数据与管理这些数据的方法一起共同封装成一个类,对外部隐藏实现细节,仅提供必要的接口用于数据交互,从而实现“高内聚、低耦合”的状态。
最后,一单元中我也学习并实现了工厂模式,对面向对象的设计模式有了初步的了解。
第二单元
二单元作业中,我初步理解了并发程序中的线程协同与线程安全,学习了基于线程、共享、交互的面向并发和协同抽象的层次设计结构,着重考虑并发行为的安全和效率。
关于安全,线程安全的目标是避免线程之间执行顺序的不确定性,即无论多个线程以什么次序访问,都不影响该对象的行为结果。而线程的直接交互容易产生线程安全问题,因此为了避免线程的直接交互,我通过共享数据访问控制来隔离线程的依赖关系,并通过对共享对象加锁产生临界区来保证对共享对象操作的原子性。
关于效率,我通过修改加锁的方式与细粒度来降低临界区的规模,通过设计全局更优的调度算法来提高调度效率。
此外,二单元中我还学习并实现了生产者-消费者模型、单例模式、黑板模式、流水线模式等,对于面向对象的设计模式有了更深的理解。
最后,在二单元中,我也对SOLID原则有了一定的体会。为了保证类的单一职责,可以将调度策略单独抽象成一个类;为了保证方法的单一职责,可以将电梯运行过程逐层拆解,保证每个方法在逻辑上高内聚低耦合。
第三单元
三单元中,我学习了契约式编程的思想,学习了JML并初步理解了基于规格的程序设计。在阅读复杂的规格时,需要理清规格内逻辑的层次关系,归纳出其最本质的要求,同时关注规格的边界条件。在实现规格时,需要注重规格实现的效率,控制时空复杂度,并保证没有副作用。
此外,三单元规格中的大量异常抛出也让我对鲁棒性有了一定的了解。
第四单元
四单元中,我学习了UML中的类图、时序图和状态图,并初步学习了模型的有效性检验。在理解了UML元素关系的基础上,我建立了自己的层次结构对UML元素进行管理。
此外,四单元中我也运用了需求导向的架构设计思维,仅把需要用到的数据信息按方便查询的方式存储,过滤掉大量的无用信息。
四个单元中测试理解与实践的演进
首先,测试无法证明一个程序完全没有bug,因此不能过度依赖测试,还是要着重提高自身架构设计和代码实现的能力。
第一单元
一单元中,由于sympy库可以很方便地检验结果的正确性,因此重点在于生成合适的数据。在数据生成时,需要坚持随机数据与手工数据相结合的原则,发挥各自的长处,取长补短。为了提高随机数据的覆盖率,我采设置了参数宏用于控制生成数据的规模和特性。而手工数据则用于填补随机数据难以覆盖到的空缺。
除了数据生成,测试的另一个关键就是自动化。这部分我主要是向张凯歌同学学习,通过编写脚本以实现自动化的数据生成和正确性检验。
第二单元
二单元中,由于同一输入没有固定的标准输出,需要专门写一个checker用于正确性检验。此外,在一单元的经验教训之上,我花了更多的时间进行白盒测试。通过完整阅读代码,可以规避大量笔误型的bug;对于阅读中感觉容易出错的部分,可以专门设计数据进行测试。
在二单元的测试中,我也引入了正确性之外的指标,例如cpu时间等,用于防止轮询。
第三单元
三单元中,除采用前面两个单元数据生成对拍的测试方法,我也根据契约式编程的特性,采用了JUnit进行单元测试。
第四单元
与前三个单元基本相同。其中hw15由于数据限制较多,我主要采用的是手工数据覆盖+回归测试验证。
课程收获
-
初步学习了JAVA语言
-
学习了面向对象的架构设计思维和设计模式
-
学习了多种测试手段
-
回顾了部分初等的算法
-
强化了工程代码实现能力
-
优化了代码风格
-
锻炼了沟通与表达能力
此外,还有很多相对独立的知识性收获:一单元中我学习了形式文法中的递归下降解析,二单元中我学习了JVM的基本机理,三单元中我学习了JAVA垃圾回收机制
立足于自己的体会给课程提几个具体的改进建议
-
增加互测数据的查重,防止无脑的共享数据行为,提高互测的有效性;
-
借鉴计组实验课的形式,增加测评机的搭建指导教程,增加测评机的提交窗口,增加数据强度的评测标准,每单元增加一次对测评机提交内容的申优答辩,以鼓励同学们独立完成测试。
-
实验课结束后可以公布一个参考答案,便于总结提升;
-
研讨课虽然增加了小组讨论环节,但在实际执行时,往往前两个发言的同学就基本就把能说的覆盖完了(尤其是遇到架构设计这类每个人都大同小异的话题时)。因此建议在话题选择上尽量选一些开放性更高的话题
-
第三单元作业对JML阅读的要求不高,第四单元作业比起UML更多考察的还是代码实现和阅读理解的能力,因此建议增加这两个单元的实验,并可以考虑将实验换成上机考试的形式。
结语
至此,OO课程告一段落。感谢老师和助教们一直以来的辛苦付出,感谢往届学长学姐不吝赐教的博客分享,感谢在学习过程中给予支持和帮助的小伙伴。最后,也祝愿OO课程越来越好!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号