

BUAA_OO_2022 Unit1 总结
1 架构设计思路分析
1.1 总体设计思路
1.2 第一次作业
在第一次作业中,核心任务有两个:初步构建表达式树的架构、实现基于递归下降法的表达式解析;
基于形式化表述,表达式可以拆成若干个项,项之间通过±连接;项可以拆成若干个因子,因子间通过*连接;因子又分为表达式因子、幂函数因子、常数因子三种;因此,我将顶层的表达式归入表达式因子中,定义一个Factor接口。
基于递归下降法,通过Lexer类将字符串拆分成若干个语义单元Token,再通过Parser读取Token流返回相应的表达式元素;这里Parser里的parseFactor方法运用了工厂模式的思想,在创建因子时隐藏了对因子种类的分类逻辑,并且通过一个共同的接口Factor来指向新创建的因子对象。
类图描述
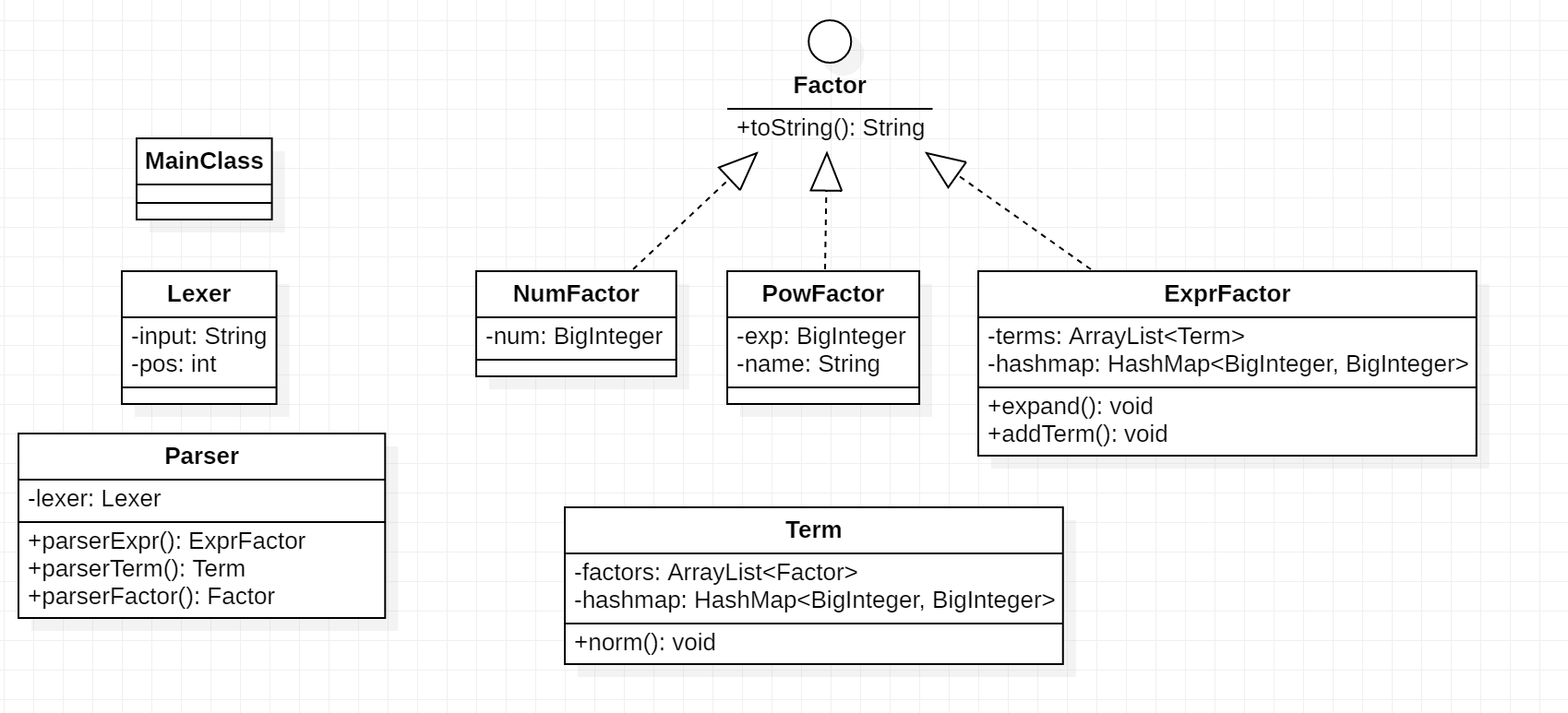
度量分析
OCavg = Average operation complexity(平均操作复杂度)
OCmax = Maximum operation complexity(最大操作复杂度)
WMC = Weighted method complexity(加权方法复杂度)
| Class | OCavg | OCmax | WMC |
|---|---|---|---|
| ExprFactor | 3.7142857142857144 | 10.0 | 26.0 |
| Lexer | 1.5714285714285714 | 4.0 | 11.0 |
| MainClass | 1.0 | 1.0 | 2.0 |
| NumFactor | 1.0 | 1.0 | 3.0 |
| Parser | 3.1666666666666665 | 6.0 | 19.0 |
| PowFactor | 1.6666666666666667 | 3.0 | 5.0 |
| Term | 2.2857142857142856 | 7.0 | 16.0 |
| Total | 82.0 |
由上表可见,递归下降解析导致Lexer和Parser类复杂度较高,而表达式化简导致ExprFactor和Term的复杂度较高。
由于此次作业的表达式化简方法在下次作业进行了重构,这里省略第一次作业的方法复杂度分析。
1.3 第二次作业
概述
第二次作业的要求相对第一次作业有了很多扩充,我将类主要分为流程类、数据类、功能类:
-
流程类就是
MainClass,作为入口;
-
功能类有负责递归下降解析的
Lexer,Parser和负责表达式运算的Operation,在Operation里实现了对表达式的乘法和加法,对表达式合并同类项和对项合并同底数因子;
-
数据类沿袭第一次作业的架构,新增了
TriFactor继承Factor,同时新增了Sum和Function处理求和函数和自定义函数。
细节
三角函数类
在处理三角函数因子时,我将sin和cos统一定义为TriFactor类,并用属性name来区分,这样的好处是可以实现对sin和cos的统一修改,同时更接近问题的本质(即在表达式化简中,sin和cos仅仅只是名字不同而已,并不涉及运算性质的差异)。
与不少同学在TriFactor类中定义ExprFactor来表征三角函数中嵌套的内容不同,我用了Factor来表征。这是基于两点考虑,首先是形式化表述里本身用的就是因子,其次是这样天然就实现了判断toString时是否需要加括号,而不用像很多同学一样做复杂的分类讨论(还容易出错)。
求和函数和自定义函数类
这两个类非常相似,都是涉及到将因子代入到相应的求和表达式/自定义函数定义表达式中。具体实现有两种路径:
一种是先对因子进行解析、化简、toString后replace掉原表达式中的x、y、z、i,最后再对这个新的字符串进行解析。
另一种是先对求和表达式/自定义函数定义进行解析,建立表达式树。在代值时,先对代入的因子进行解析,然后递归之前建立的表达式树,用代入因子替换表达式树种的幂函数因子。这里需要注意的是,替换时需要将代入因子clone,以消除数据共享。
操作类
经过分析后,我发现合并同类项、项内同底数因子合并、表达式加法、表达式乘法其实都是对一些装有Factor和Term的容器进行操作,因此我将这些方法抽出来合成一个方法类,便于在不同的数据类中调用;
合并同类项
合并同类项的本质是比较表达式中的项除系数外的部分是否相等,若相等则可以合并,这里的合并是指将两个相等的项的系数相加,因此关键是如何判断相等。
由于项是由因子组成的,因此对项相等的判断可以归结为对项内每个因子是否相等的判断。而因子中只要表达式因子和三角函数因子会嵌套其他项和因子,其他因子可以作为叶子节点直接比较其内部的基本属性是否相同判断相等。而三角函数因子的判断其实最终也会归结为对表达式因子相等的判断,因此问题转化为对表达式因子相等的判断。
由于表达式时由项组成的,因此对表达式相等的判断可以归结为对表达式内每个项是否相等的判断。
至此,递归比较相等的框架已构建完成,可以通过重写equal和hashCode实现。为了避免项和因子的顺序影响对相等的判断,我们用无序容器HashSet来管理和存放表达式中的项和项中的因子;
类图描述![]()
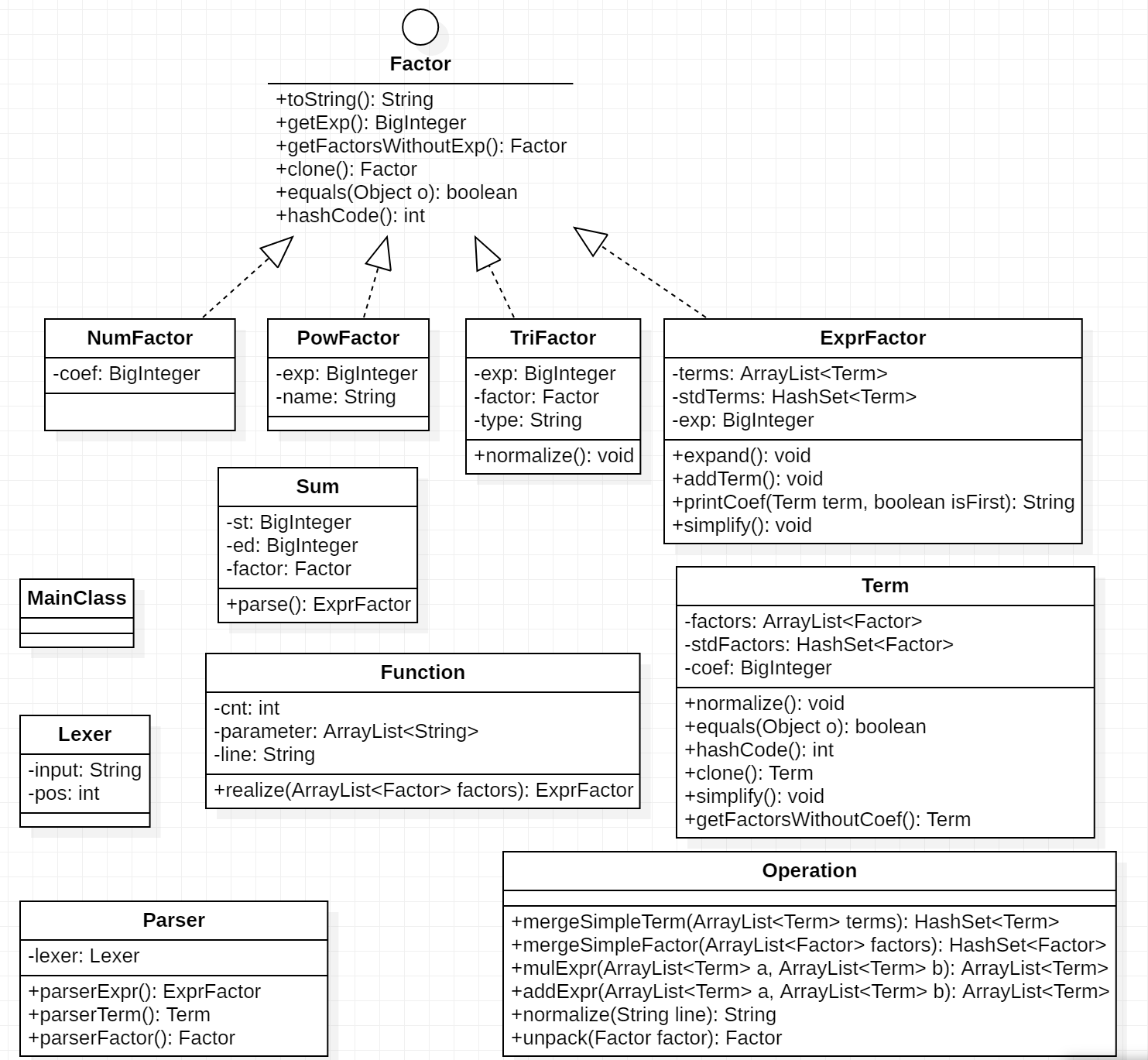
度量分析
类复杂度分析
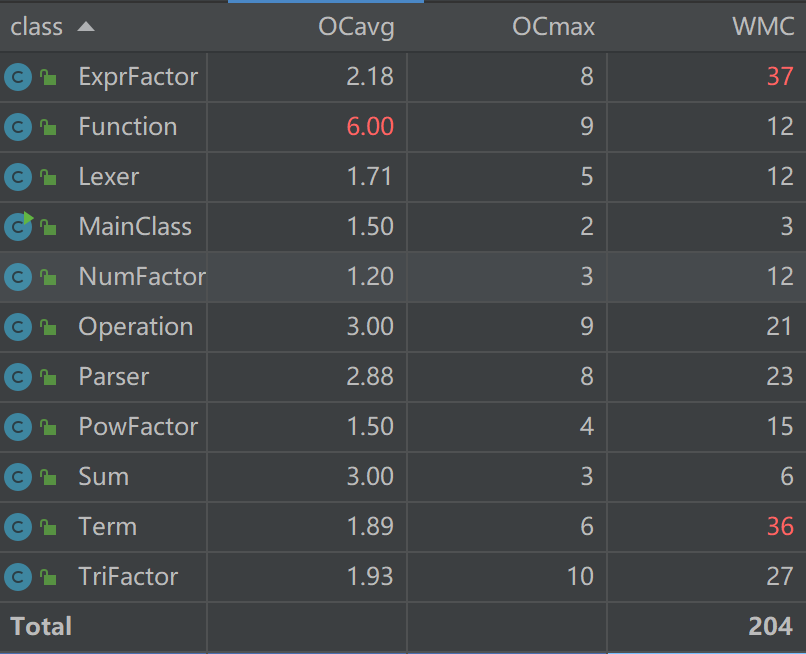
由于ExprFactor和Term承载了表达式化简的大部分功能,因此复杂度较高。Function则是由于代值时逻辑较为复杂,导致复杂度较高。
方法复杂度分析
CogC:cognitive complexity 认知复杂度,表征代码可读性
ev(G):Essential cyclomatic complexity 基本圈复杂度
iv(G):Design complexity 设计复杂度
v(G):cyclonmatic complexity 圈复杂度
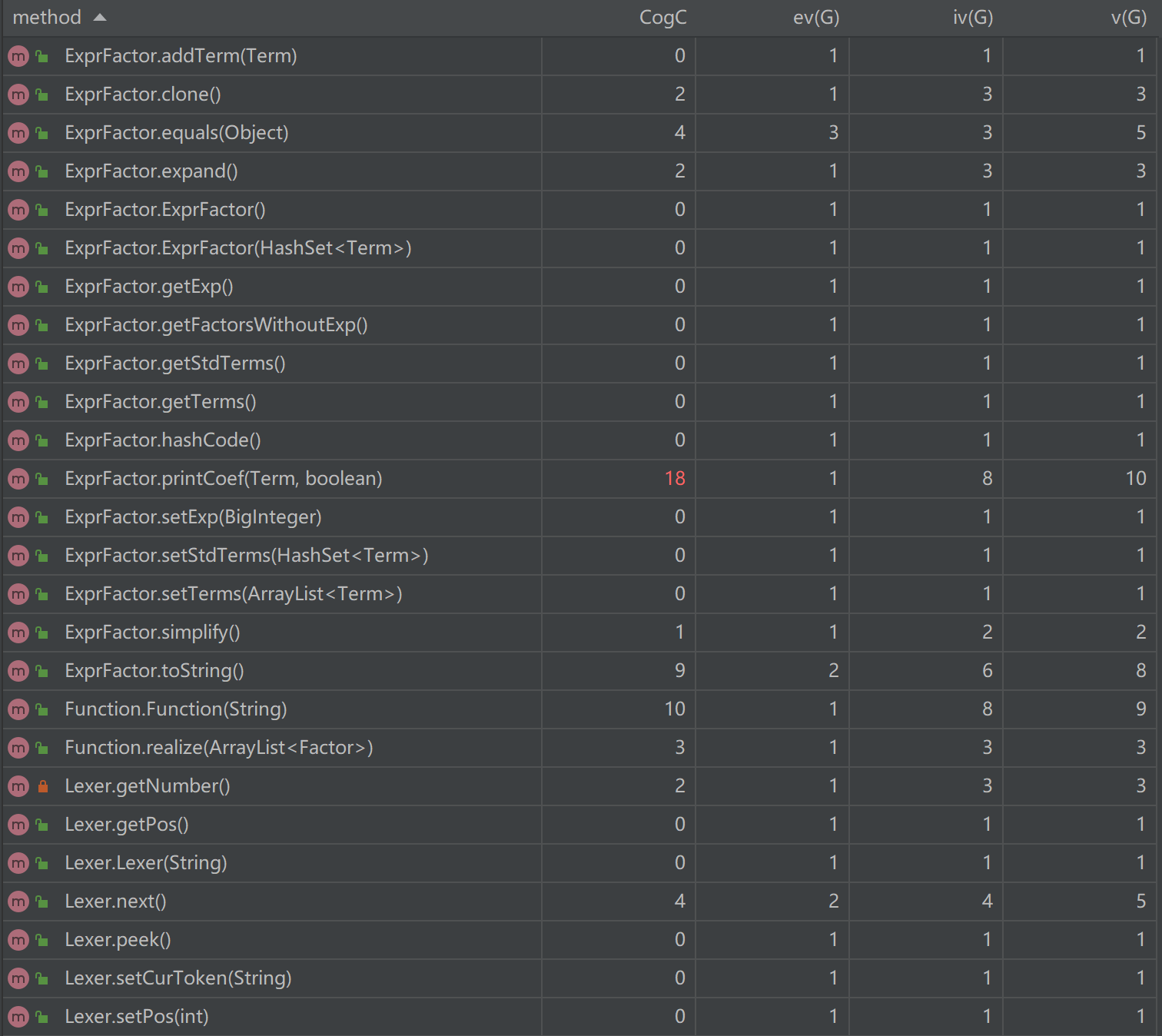
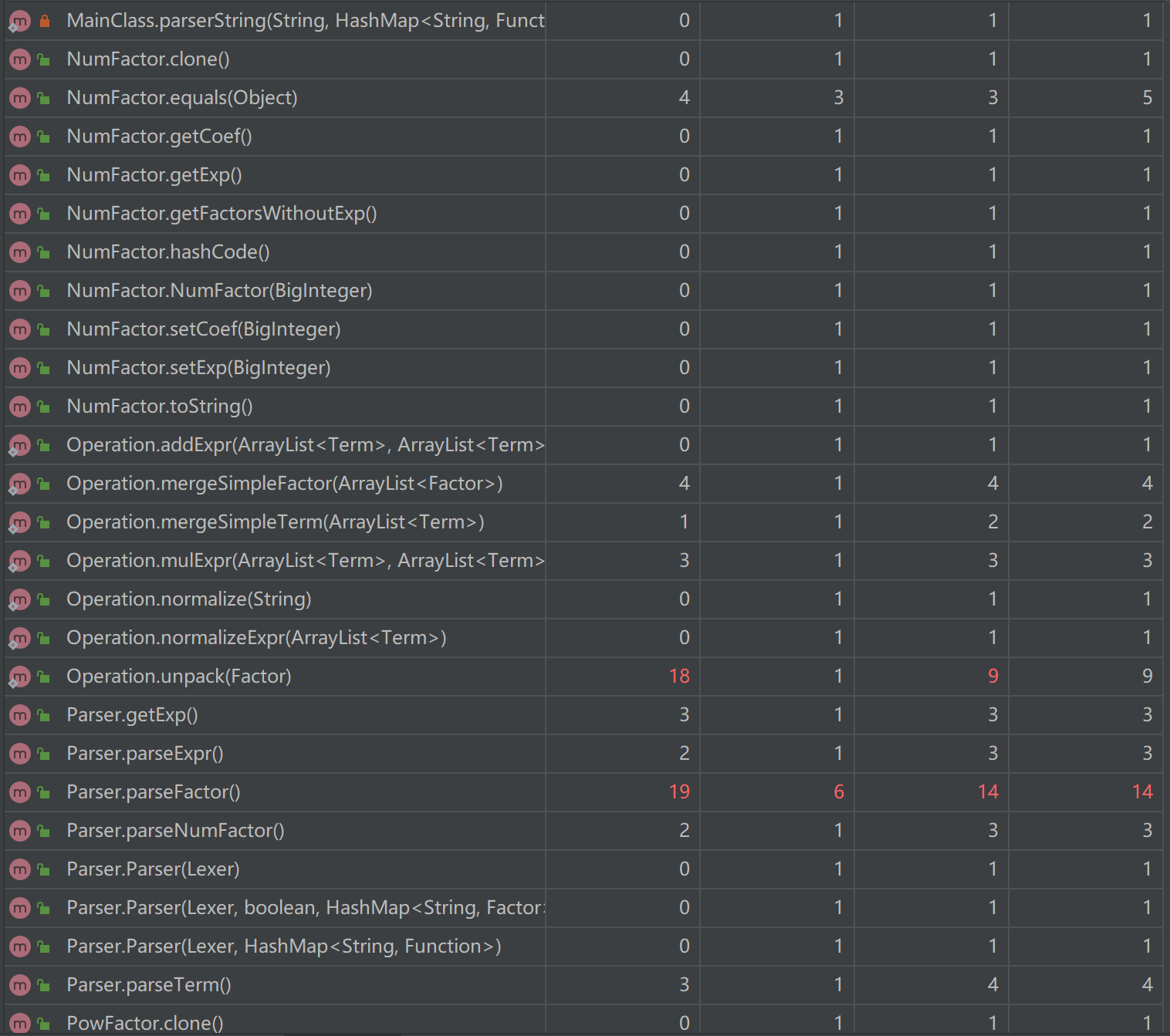
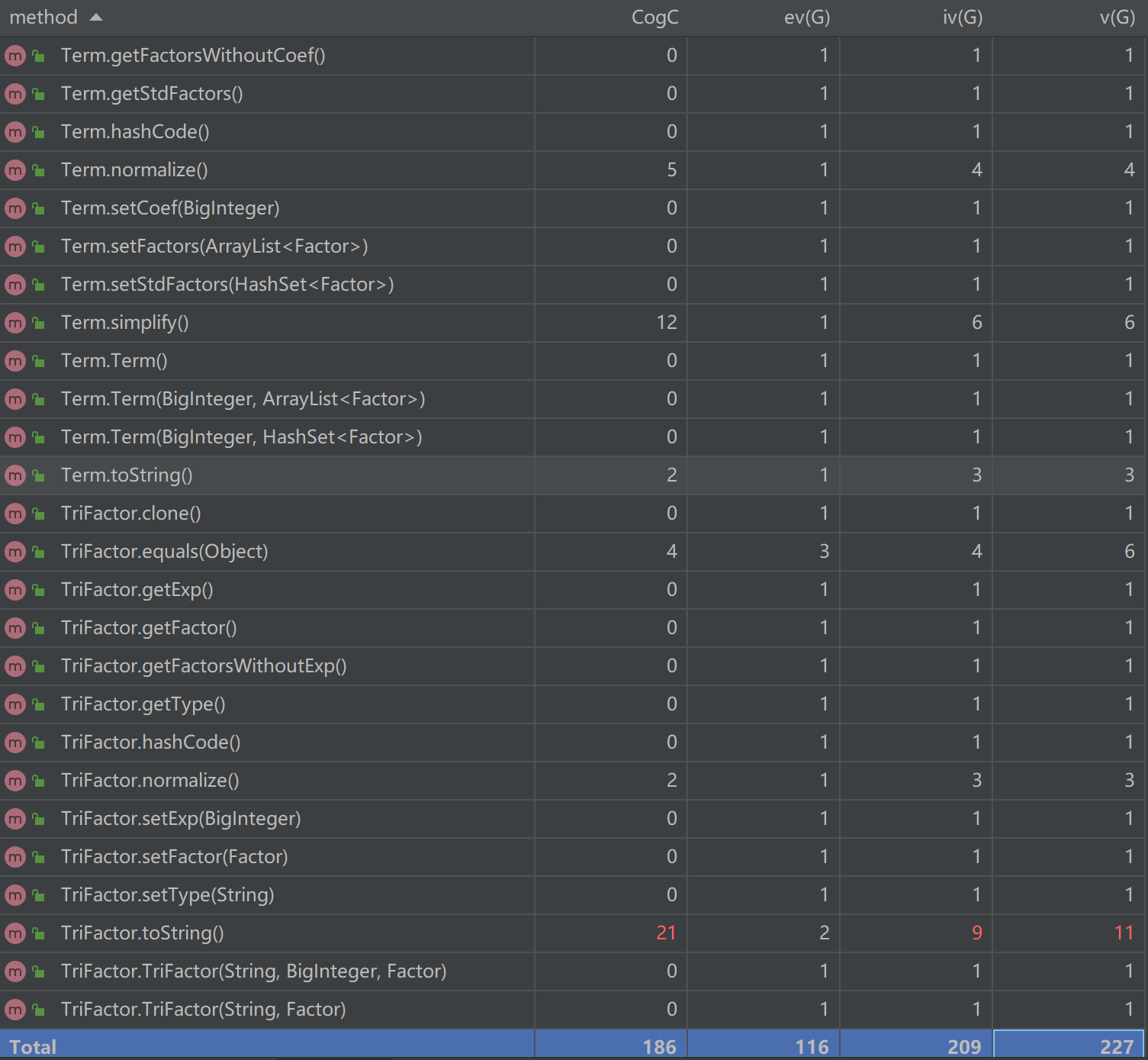
由上可知,绝大部分方法的复杂度都较为理想,整体上符合高内聚低耦合的思想。
ExprFactor中的printCoef由于要判断项前系数省略,逻辑较为繁琐;Operation中的unpack由于要判断三角函数内因子的类型和状态判断是否可以拆包展开,逻辑较为繁琐;Parser中的parserFactor由于运用了工厂模式,需要判断因子的类型,逻辑较为繁琐;TriFactor中的toString由于承担了将sin(0), cos(0)化为常数的功能,逻辑较为复杂;
1.4 第三次作业
由于在第二次作业时我已经考虑了三角函数内嵌套表达式因子、自定义函数和求和函数嵌套的情况,且递归下降法与表达式树结构天然支持表达式因子嵌套的情形,因此第三次作业我只在第二次作业的基础上加了几处对clone的调用,其他几乎没有区别。
2 bug 分析和测试
2.1 第一次作业
自己的bug
在第一次作业中,我将表达式因子的指数在解析时处理,即将同一个表达式多次放进容器中,这导致了数据共享,在面对(x+1)**2这种数据时会出错。在自测时我发现了这个bug,并通过clone修改,但由于修改时未全面检查,有一处修改漏掉了,导致在某些特殊的情况下仍然会出错。
后来反思时,总结了至少3个导致错误的原因。第一是没有深入理解类、对象和对象引用之间的关系,没有考虑到数据共享;第二是在发现数据共享的问题后,只在一处做了修改后就急于测试,且测试通过后就没有再检查是否有其他地方需要做相同的修改;如果将同质化的代码抽象成单独的方法就可以避免这样的问题;第三是在写数据生成器时,忘记考虑表达式因子带指数的情况,导致生成的数据无法测试出上述bug;这反应了我没有深刻理解形式化表述,没有意识到数据的全覆盖性的重要性。
别人的bug
有同学在处理指数前的-时将-放进了指数中运算,导致-+x**2这类数据出错;
2.2 第二次作业
自己的bug
无
别人的bug
有同学在结果为0时没有输出;
有同学在三角函数中的因子如果是负数且后面带有指数时会出错;
有同学用正则表达式+replaceAll化简系数和指数为1的情况,在遇到11*x、x**11这类结果时会出错;
2.3 第三次作业
自己的bug
由于在TriFactor的normalize方法中未判断三角函数内嵌套的是三角函数时需要对内层三角函数继续normalize的情况,导致在合并同类项时会出错;
在第二次作业中TriFactor的toString方法遇到sin(0)会输出(0),然后对第一次输出的结果再进行一次解析化简。由于第二次作业括号嵌套层数不多因此不会出错,但到第三次作业时,可能遇到sin(sin(0))的情况,由于只进行了一次重解析化简,最终会输出(0),含有多余的括号,格式非法。
后来反思时,总结这两个错误都是由于迭代开发时未仔细检查代码中每一处需要修改的地方,导致第二次作业不会暴露的问题在第三次作业中暴露,其实这两个bug最终仅需要修改三行,本身并非是设计、逻辑上出的问题,而是细节上的疏忽。
此外还有我过于依赖自动测试,以为自动测试没发现bug就没有再去检查阅读代码;但事实上,第一个bug由于我在自动生成器中设置了最大递归层数maxLevel = 3(这样的目的是防止数据过大跑不出来),导致会产生bug的数据很难被生成出来;第二个bug则是由于测评机本身无法判断多余的括号(这也是我的疏漏,我之前认为只要python库不报错格式就没问题,但这没考虑到我们作业要求不能出现多余的括号,但python库即使有多余的括号也不会报错);
别人的bug
有同学sum无法处理超过int的情况;
有同学sum中出现指数时会出错;
2.4 bug总结
对比分析发现,出现了bug的方法在代码行和圈复杂度明显高于未出现bug的方法,这是因为代码行和圈复杂度高的方法一般运用的是面向过程的思维,含有繁琐的分类讨论,容易因疏忽出错。
2.5 测试方法
在测试方面,我和zkg同学合作,我做了数据自动生成,他负责自动测试。
关于数据生成,我基于形式文法和递归下降思想,生成了完全符合作业格式要求且全覆盖的数据;为了让常数具有特点,采用了常量池,并设置了参数调节常数的规模;为了控制最终表达式展开的复杂度,我在宏定义中设置了maxLevel控制递归的深度,设置了maxPow控制指数的范围,设置了项中因子个数的上下界和表达式中项的个数的上下界,设置了是否允许出现空白符;
生成的一大难点在于自定义函数,我将自定义函数的定义式和调用式分开,其中调用式只需要生成随机的因子即可。关于定义式,首先随机得到函数自变量个数,然后随机得到函数自变量的种类,然后通过allowVar[4]控制生成的函数表达式中允许出现的变元名称;在求和函数中,也可以用类似的方法生成只含i和x的求和表达式;
关于自定义函数定义中不能出现自定义函数调用,以及sum求和表达式中不能出现求和表达式和自定义函数的调用,我用了allowFunc和allowSum两个全局变量来控制。
2.6 发现bug的策略
主要通过黑箱测试和白箱测试相结合的方法,先通过自动测试工具初步判定是否存在bug,再通过二分法不断缩小测试样例的规模精确定位bug的范围,最后通过阅读代码找到bug的所在。在修复bug后,再通过回归测试检验是否仍有其他bug。
在hack他人的代码时,也会根据对方使用的设计模式采取一些额外的策略。例如,如果发现对方用的是正则表达式,我则会直接通过逻辑找正则的漏洞,然后定点hack。
3 改进方面和心得体会
改进方面
与三角函数化简相关的部分的复杂度较高,代码也略显臃肿,没能很好反应面向对象的思想。关于在迭代开发时,如何做到不漏细节也是一个值得思考的问题。本单元作业的所有bug基本都是由于细节的处理上的疏忽,而非整体架构设计的问题。或许在每次迭代开发结束后,静下心来认真读地从头到尾读一遍代码、整理一下不同类和方法之间的逻辑关系可以减少这种细节问题的发生。
心得体会
在面对一个复杂的工程问题时,应当花足够的时间思考一个好的架构。好的架构应当完全反应问题的原貌,这个架构不能仅仅满足于解决当前的问题需求,还应当考虑到后续的增量开发与迭代需求。在三次作业中,我基本没有重构,第一次作业主要实现了递归下降解析和表达式树的结构;第二次作业主要扩充了自定义函数和求和函数、实现了合并同类项;在第三次作业时,第二次作业的代码已经基本上完全符合第三次作业的需求了。
同时,本单元的作业也加深了我对OOP的理解:
-
封装:封装是指外部隐藏实现细节,仅提供必要的接口用于数据交互,实现“高内聚、低耦合”的状态。一段需要重复使用的代码可以封装成一个方法,一组在语义上关联紧密的数据可以与管理这些数据的方法一起共同封装成一个类。例如,我将在不同数据类中可能会重复用到的方法抽象成了一个公共的方法类;在每个方法的设计中,也尽量保证每个方法在逻辑上具有一个明确的含义,比较复杂的方法一般也会拆分成几个子方法的组合。
-
继承与多态:通过重写方法,使得同一个方法在不同层级的类中有不同的表现;通过归一化管理,由上层的抽象来实现无差别的引用和访问。例如,我重写了
equal hashCode toString clone等方法,定义了Factor接口,并在每个子类中重写了接口中定义的方法。
另外,本单元作业使我初步了解了形式文法分析和递归下降法;通过理解形式化表述、递归下降解析和递归下降生成随机数据,我对形式文法也产生了一定的兴趣。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号