Interacted Action-Driven Visual Tracking Algorithm
文章来源:Attentional Action-Driven Deep Network for Visual Object Tracking 博士论文(2017年8月份完稿)
http://s-space.snu.ac.kr/bitstream/10371/136793/1/000000145905.pdf
Chapter 4. Interacted Action-Driven Visual Tracking
4.1 Overview:
之前作者提出的 Single Agent Reinforcement Learning Tracking Algorithm 存在相似物体遮挡导致失效的问题:

这种情况下,由于只考虑到物体的那一小块区域,由于有相似物体的存在,非常容易导致物体遮挡后,跟着其他物体乱跑的情况:
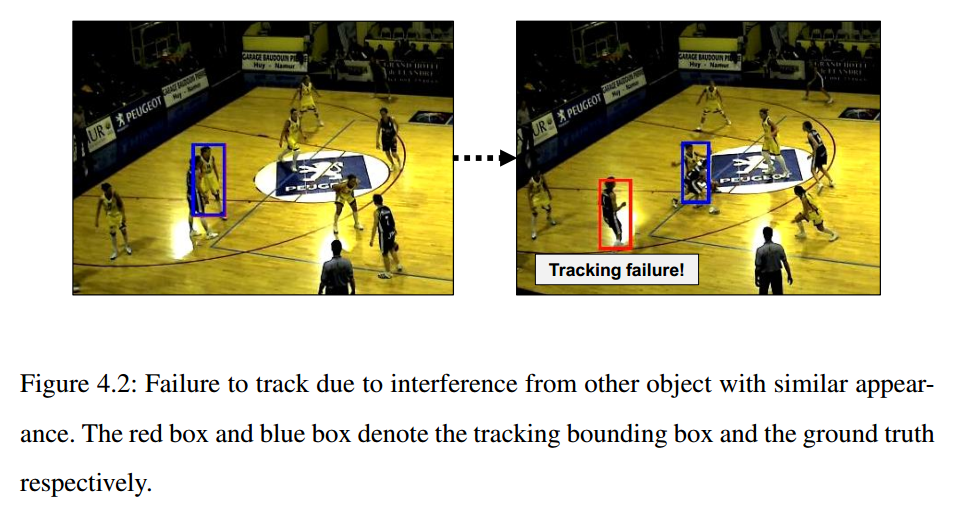
那么,如何解决这种问题呢?
作者提出了一种新颖的结合多个物体 patch 的方法来解决上述问题,并且结合 多智能体强化学习方法,提出了一种基于智能体之间相互交流的方法:
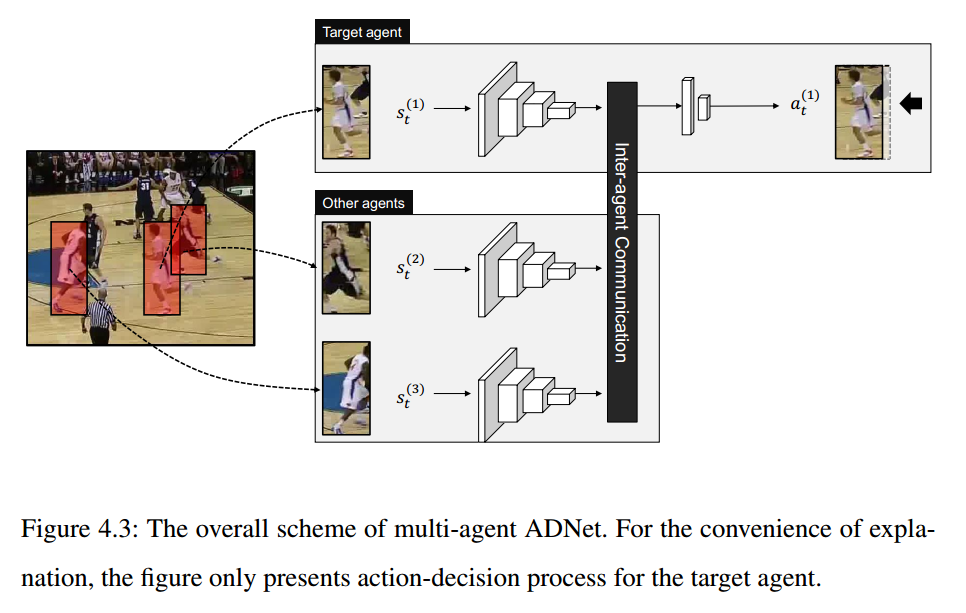
多智能体之间进行交流本来也是非常热的一个研究问题,本文将其结合到跟踪问题中去,来解决 Context 信息的问题,并且设计出了上述的网络结构,思路是比较直观的。
那么,本文的baseline 方法是:多个 agent 无交流的进行动作的选择的网络:
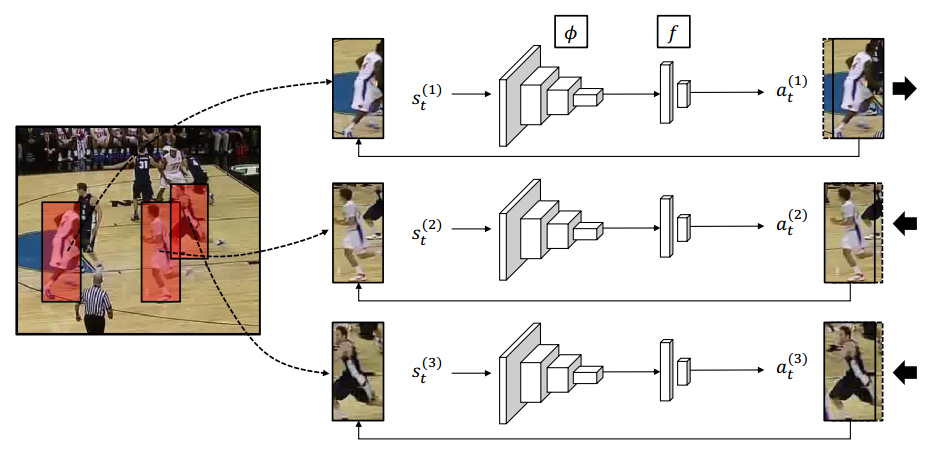
==================================================================================================================================
==================================================================================================================================
==================================================================================================================================
本文所提出的方法框架为:
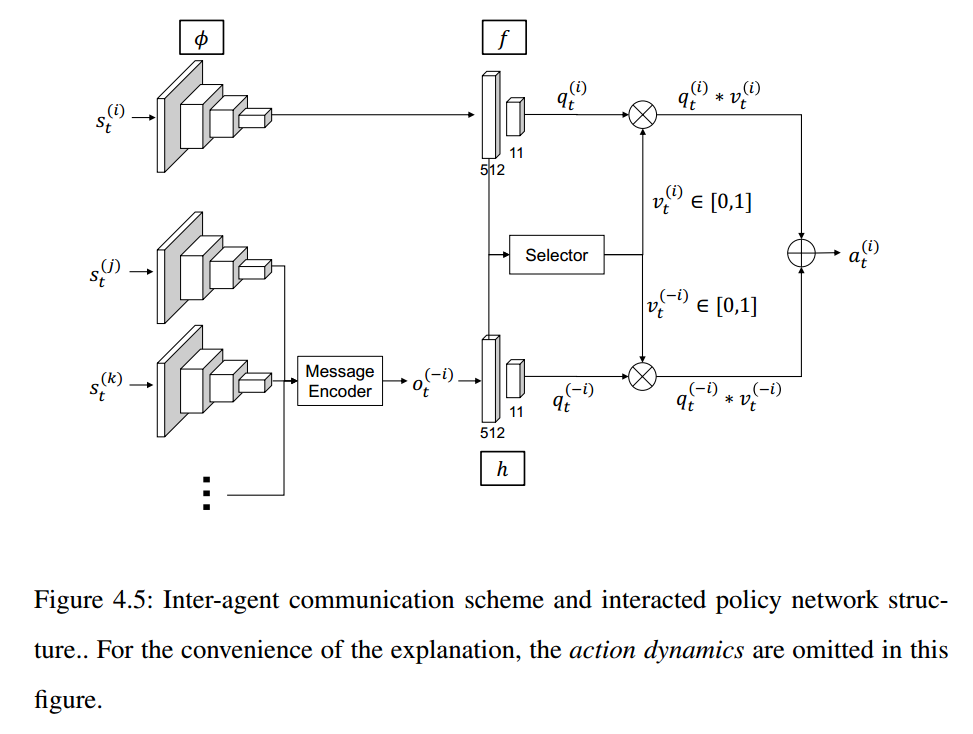
该网络主要有三个部分构成:
1. Feature Encoder;
2. Message Encoder;
3. Selector;
==================================================================================================================================
==================================================================================================================================
==================================================================================================================================
接下来,分别进行介绍:
1. feature encoder 没啥好介绍的,就是用 CNN 提取特征;
2. 信息编码网络,就是特征的叠加;
3. Selector: In order to combine the two primitive actions, the action selector module (Section 4.3.2.2) is proposed.
可以看出,本文引入这个,就是为了将两个网络的输出,进行叠加,融合两个网络的输出。

该选择器,有两维的输出,将两个网络初始的 action 分布,进行加权处理,最终融合为一个网络(多么熟悉的套路)。

可以看出,这个网络的设计,考虑到了 patch块的空间位置信息(Context 信息)。

然后,就是网络的训练,本文采用的是分阶段训练的(虽然可以 end to end 的进行 training),分别对这三个子网络进行训练。



 浙公网安备 33010602011771号
浙公网安备 33010602011771号