Attribute2Image --- Conditional Image Generation from Visual Attributes 论文笔记
Attribute2Image --- Conditional Image Generation from Visual Attributes
Target: 本文提出一种根据属性生成图像的产生式模型 。
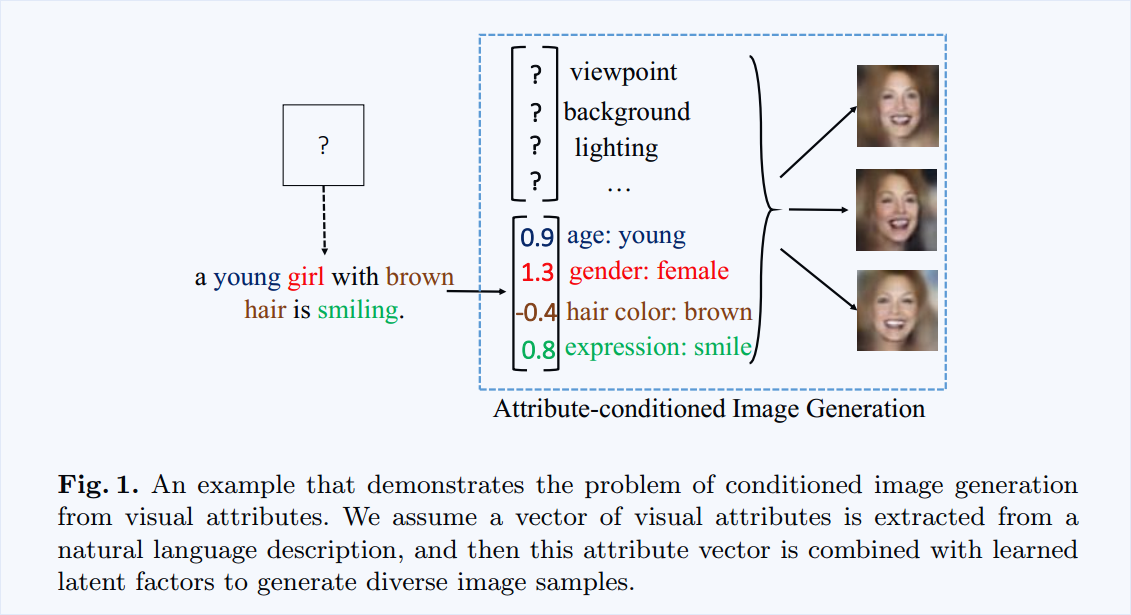
有了具体属性的协助,生成的图像更加真实,降低了采样的不确定性。
基于这个假设,本文提出一种学习框架,得到了基于属性的产生式模型。
1. Attribute-conditioned Generative Modeling of Images.
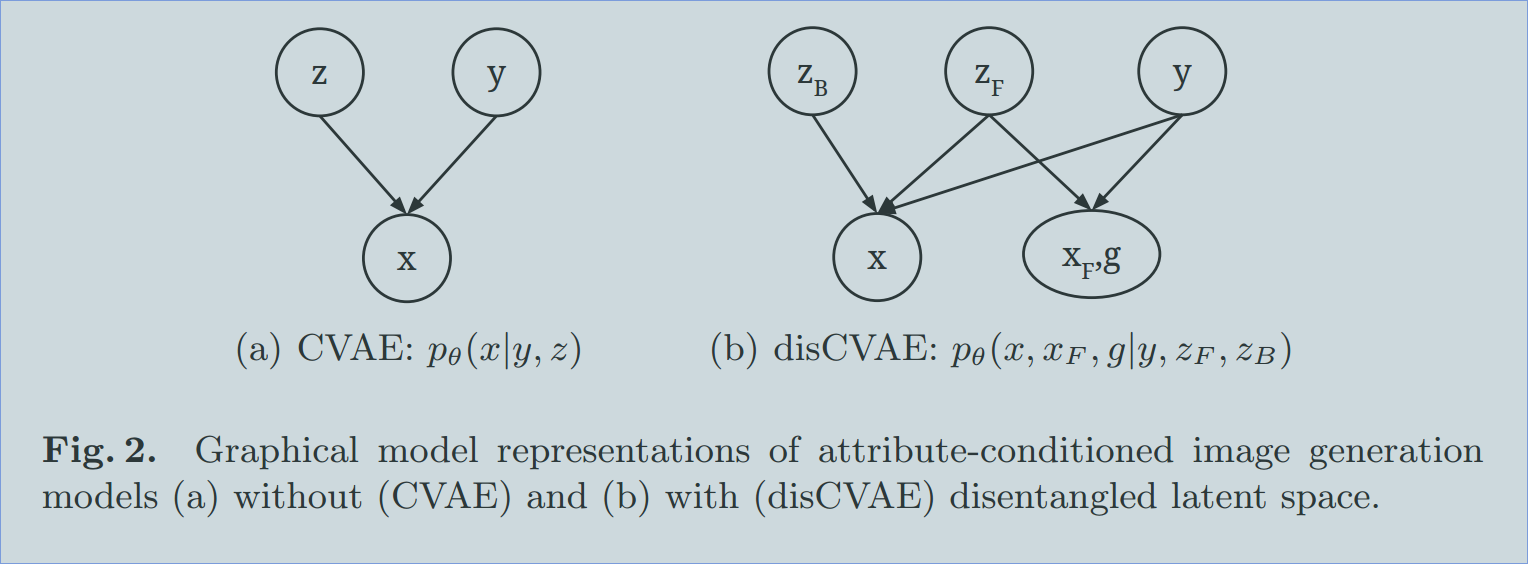
3.1 Base Model: Conditional Variational Auto-Encoder (CVAE)
关于该节,可以参考博文:http://www.cnblogs.com/wangxiaocvpr/p/6231019.html
给定属性 y 和 latent variable z, 我们的目标是构建一个模型,可以在条件 y 和 z 的基础上产生真实的图像。此处,我们将 $p_\theta$ 看作是一个产生器,参数为 $\theta$。
条件式图像产生是简单的两部操作,如下:
1. 随机的从先验分布 p(z) 中采样出 latent variable z;
2. 给定 y 和 z 作为条件变量,从 $p_\theta (x|y, z)$ 产生图像 x。
此处,学习的目标是找到最佳的参数 $\theta$ 可以最大化 log-likelihood $log p_\theta (x|y)$. VAE 试着去最大化 log-likelihood 的 variational lower bound。特别的,一个辅助的分布 q 被引入来估计真实的后验概率。

此处,the prior $p_\theta (z)$ 被认为是服从 各项同性的多方差高斯分布(isotropic multivariate Gaussian distribution),两个条件分布 p 和 q 是多方差高斯分布。我们将辅助的 proposal distribution q 看作是 recognition model,条件数据分布 p 是 generation model。
上述模型的第一项 KL(q|p)是一个正则化项,目标是减少 the prior p(z) 和 the proposal distribution q 之间的差距,第二项是样本的 log likelihood。
实际上,我们通常考虑 a deterministic generation function 给定 z 和 y 的条件分布 $p_{\theta}(x|z,y)$ 的均值 $x = \mu_{\theta}(z, y)$ 。所以,标准的偏差函数 $\delta_\theta(z, y)$ 是一个固定的常量,并被所有像素点共享,因为 latent factors 捕获了所有的 data variation。所以,我们可以将第二项改写为 重构误差 L(*,*)(即:l2 loss):
![]()
3.2. Disentangling CVAE with a Layered Representation.
一张图像可以看做是一个 foreground layer 和 background layer 的组合,如下:
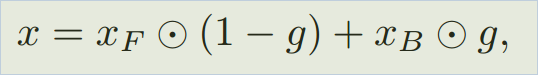
其中,圆圈符号表示元素级相乘(element-wise product)。g 是 an occlusion layer or a gating function 决定背景像素点的可见性,1-g 表示了前景像素点的可见性。
但是基于上述公式的 model 可能受到 错误预测的 mask 的干扰,因为 it gates the foreground region with imperfect mask estimation.
我们预测下面的函数,该函数对 mask的预测误差更加鲁邦:
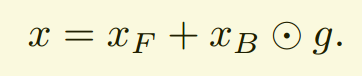
当照明条件稳定的时候,以及背景在一定的距离,我们放心的假设: foreground and background pixels 是从相互独立的 latent factors.
为了这个目标,我们提出一种分离的表达(a disentangled representation) 在 latent space 的,z = [zF, zB]。zF 和 属性 y 一起捕获了 the foreground factors,而 zB 捕获了 the background factors. 所以,对应的,the foreground layer xF 是从 $\mu_{\theta F}(y, z_F)$ 中产生的,而 the background layer xB 从 $\mu_{\theta F}(z_B)$ 中产生的。前景的形状和位置决定了背景遮挡,所以,
the gating layer g 是从 s 产生的。其中 the last layer of s(*) 是 sigmoid function。
总的来说,我们按照下面的过程来进行 the layered generation process:
1. 采样前景和背景隐层变量zF, zB ;
2. 给定 y 和 zF, 产生前景层 xF 和 gating layer g; 以及 背景layer。
3. 合成一张图像 x 。
Learning 。以完全无监督的方式学习我们的 layered generative model 是非常有挑战的。我们仅仅从图像 x infer 关于 xF, xB and g.
本文中,我们进一步的假设 the foreground layer xF (as well as the gating variable g) 在训练的过程中,是可见的。我们训练一个模型,最大化 the joint log-likelihood $log p_\theta (x, xF, g|y)$ 而不是 $log p\theta(x|y)$。有了解绑的 latent variable zF 和 zB,我们 infer layered model a disentangleing conditional variational auto-encoder (disCVAE)。我们对比了 the graphical models of disCVAE with vanilla CVAE in Figure 2.
基于 the layered generation process, 我们将 产生式模型 (the generation model) 写成下面的方式:
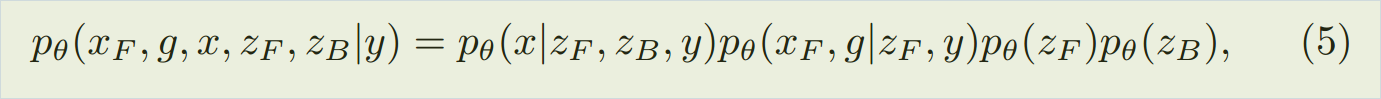
而 判别式模型 (the recogniton model)记为:

the variational lower bound $L_{disCVAE}$ 记为:
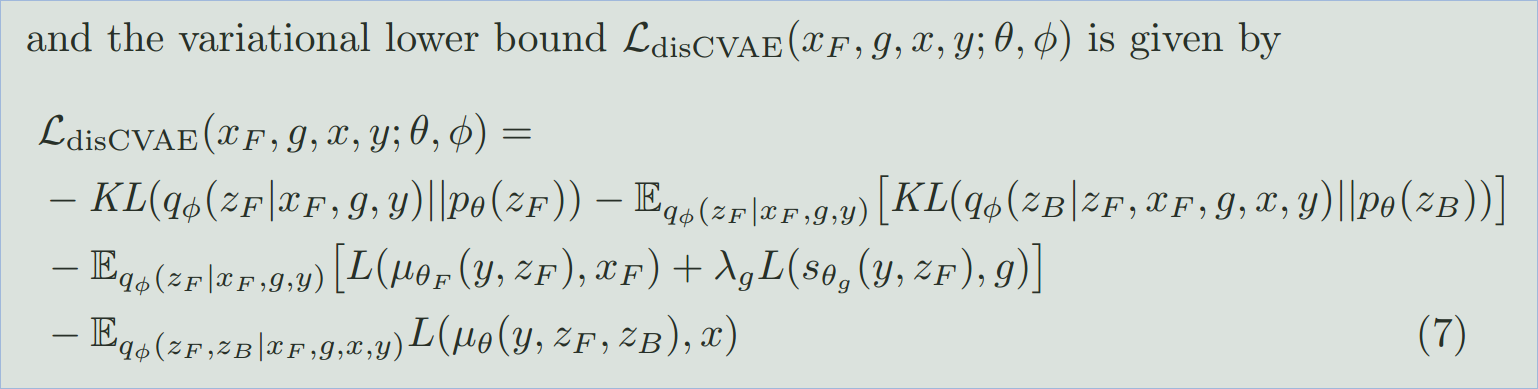
4. Posterior Inference via Optimization.
一旦 the attribute-conditioned generative model 训练完成后,给定属性 y 和 latent variable z 后,图像 x 的 the inference 或者 generation 是非常直观的。
但是,给定 an image x,latent variable z 的 inference 及其对应的属性 y 是未知的。实际上,the latent variable inference 是非常有用的,因为其确保了在新图像上的 model evaluation。
首先,我们注意到:the recognition model q may not be directly used to infer z.
一方面,作为估计,我们不知道其距离真实的 posterior p 有多远。因为在 variational learning object 中,KL divergence 被扔掉了;
另一方面,这种估计在其他模型,如:GANs,甚至不存在。
我们给出了一种 general approach 进行 posterior inference,在 latent space 进行 optimization:
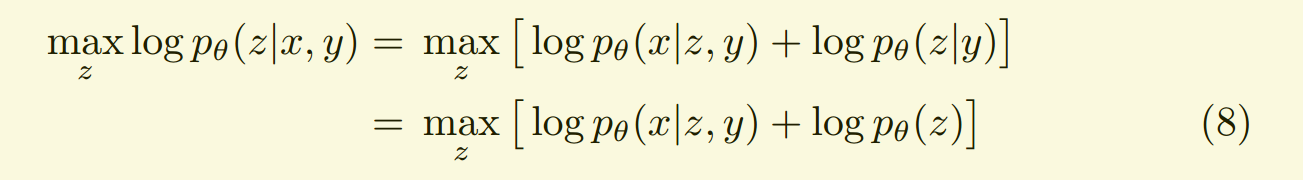
注意到,the generation models or likelihood terms 可以是 non-Gaussian or even a deterministic function with no proper probabilistic definiton.
所以,为了使得我们的算法更加 general,我们将上述的 inference 的过程,写成下面能量最小化的问题:
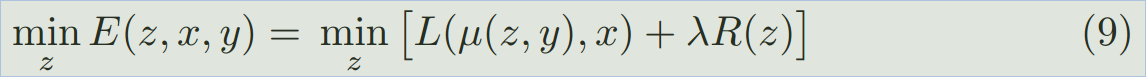
其中,L 是图像重构的 loss,R 是 先验正则化项。以简单的高斯model 作为例子,the posterior inference 可以重新写作:
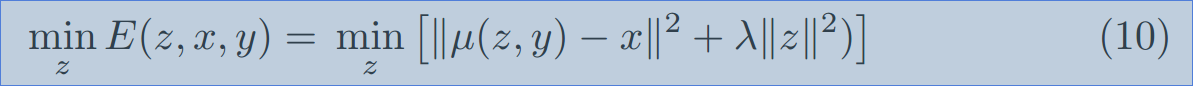
注意到,我们用 the mean function u 为 a general image generation function。因为 u 是一个复杂的神经网络,优化 公式(9)本质上是误差回传,我们利用 ADAM method 来求解。
本文与最新提出的 神经网络可视化 和 文本合成算法 的区别在于:
We use generation models for recogniton; while others use recogniton model for generation.
实验部分:





 浙公网安备 33010602011771号
浙公网安备 33010602011771号