Zookeeper学习记录
Zookeeper学习记录
一、简介
ZooKeeper 是一个开源的分布式协同服务框架,
它的设计目标是将那些复杂且容易出错的分布式协同服务封装起来,抽象出一个高效可靠的原语集,并以一系列简单的接口提供给用户使用。
ZooKeeper 是 Google 的 Chubby 项目的开源实现,它曾经作为 Hadoop 的子项目,在大数据领域得到广泛应用。
ZooKeeper 基于分布式计算的核心概念而设计,主要目的是给开发人员提供一套容易理解和开发的接口,从而简化分布式系统构建的任务。
ZooKeeper 的设计保证了其健壮性,这就使得应用开发人员可以更多关注应用本身的逻辑,而不是协同工作上。
ZooKeeper 从文件系统 API 得到启发,提供一组简单的 API,使得开发人员可以实现通用的协作任务,包括选举主节点、管理组内成员关系、管理元数据等。
ZooKeeper 包括一个应用开发库(主要提供 Java 和 C 两种语言的 API)和一个用 Java 实现的服务组件。
ZooKeeper 的服务组件运行在一组专用服务器之上,实现服务组件。
作用:存储与管理数据,并监控数据变化,通知到注册在zookeeper上的服务。
二、应用场景
Zookeeper 的主要应用场景有统一命名服务,统一配置管理,统一集群管理,服务器节点动态上下线等。
三、服务器角色
维度一
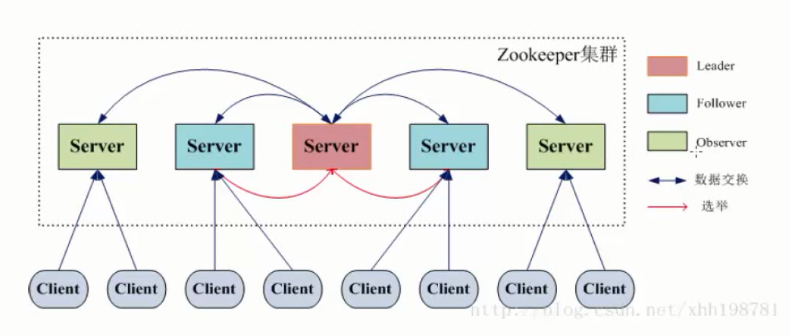
Leader:领导者。Leader服务器为客户端提供读服务和写服务。
Follower:追随者。提交来自领导者的提议。Follower 服务器为客户端提供读服务,参与 Leader 选举过程,参与写操作“过半写成功”策略。
Observer:观察者。提交来自领导者的提议。不参加选举过程。Observer 服务器为客户端提供读服务,不参与 Leader 选举过程,不参与写操作“过半写成功”策略。用于在不影响写性能的前提下提升集群的读性能。
Learner:学习者。由于领导者将 状态变化发送给追随者和观察者,这两种服务器也都被称为学习者。
Client:客户端。服务请求发起方。
维度二
Participant :参与者。可以是领导者也可以是追随者。
Observer :观察者。
Zookeeper集群管理图:
Paxos角色:
三种角色: Proposer 提案者、Acceptors 接受者、Learner 学习者;
在分布式场景下需要作出一个决策时,需要给 Proposer 提交一个提案;
Acceptors 判断是否接受这个提案,如果超过半数接受提案,需要把确定的结果发送给 Learner;
有的 Acceptors 会拒提案,有可能是已经收到其他服务器发送的请求,所以有新的提案进来时会拒绝;
四、集群服务器状态
LOOKING:竞选状态;当前 Server 未知集群中的 Leader,并且正在寻找。
LEADING:领导者状态;当前 Server 即为选举出来的 Leader。
FOLLOWING:追随者状态;当前 Follower 已与选举出来的 Leader 同步。
OBSERVING:观察者状态;当前 Observer 已与选举出来的 Leader 同步。
五、数据结构
Zookeeper 的数据结构与 Unix 文件系统很类似,整体上可以看作是一棵树,与 Unix 文件系统不同的是 Zookeeper 的每个节点都可以存放数据,
每个节点称作一个 ZNode,默认存储1MB的数据,每个 ZNode 都可以通过其路径唯一标识。
DataTree类

ZNode 类型:
临时节点、持久节点、临时有序节点、持久有序节点。
- 临时(Ephemeral):当客户端和服务端断开连接后,所创建的ZNode(节点)会自动删除
- 持久(Persistent):当客户端和服务端断开连接后,所创建的ZNode(节点)不会删除
六、watch机制
为了替换客户端的轮询,避免无效的数据调用。
采用了基于通知(notification)的机制:客户端向ZooKeeper注册需要接收通知的 znode,通过对znode设置监视点(watch)来接收通知。
监视点是一个单次触发的操作,意即监视点会触发一个通知。
为了接收多个通知,客户端必须在每次通知后设置一个新的监视点。
七、version机制
八、过半写成功策略
Leader 节点接收到写请求后,这个 Leader 会将写请求广播给各个 server,各个 server 会将该写请求加入待写队列,并向 Leader 发送成功信息,
当 Leader 收到一半以上的成功消息后,说明该写操作可以执行;然后,Leader 会向各个 server 发送提交消息,各个 server 收到消息后开始写。
Follower 和 Observer 只提供数据的读操作,当他们接收的写请求时,会将该请求转发给 Leader 节点。
集群中只要有半数以上的节点存活,Zookeeper 集群就能正常服务。因此 Zookeeper 集群适合安装奇数台机器。
九、集群选举
1、一致性算法
Paxos(帕克索斯):Paxos 算法是 Lamport 宗师提出的一种基于消息传递的分布式一致性算法,使其获得2013年图灵奖。
Zookeeper 基于 Fast Paxos 算法。
2、选举要素
Epoch:逻辑时钟,每一轮投票过程中逻辑时钟必须是相同的,每投完一轮这个数值就会增加。
状态:只有 LOOKING 状态的才会参与选举。
ZXID:事务ID,服务器中存放的最大数据ID,值越大表明数据越新,在选举中所占权重越大。
myid:服务器ID,编号越大在选举中所占权重越大。
ZooKeeper 状态的每次变化都接收一个 ZXID(ZooKeeper 事务 id)形式的标记。
ZXID 是一个 64 位的数字,由 Leader 统一分配,全局唯一,不断递增。
ZXID 展示了所有的ZooKeeper 的变更顺序。
每次变更会有一个唯一的 zxid,如果 zxid1 小于 zxid2 说明 zxid1 在 zxid2 之前发生。
3、选举实现类
类:QuorumPeer
默认Leader选举实现类(快速群首选举):FastLeaderElection
接口:Election
4、选举过程

(1)服务器 1 启动,发起一次选举。服务器 1 投自己一票。此时服务器 1 票数一票,不够半数以上(3 票),选举无法完成,服务器 1 状态保持为 LOOKING;
(2)服务器 2 启动,再发起一次选举。服务器 1 和 2 分别投自己一票并交换选票信息:此时服务器 1 发现服务器 2 的 ID 比自己目前投票推举的(服务器 1)大,更改选票为推举服务器 2。
此时服务器 1 票数 0 票,服务器 2 票数 2 票,没有半数以上结果,选举无法完成,服务器 1,2 状态保持 LOOKING;
(3)服务器 3 启动,发起一次选举。此时服务器 1 和 2 都会更改选票为服务器 3。此次投票结果:服务器 1 为 0 票,服务器 2 为 0 票,服务器 3 为 3 票。
此时服务器 3 的票数已经超过半数,服务器 3 当选 Leader。服务器 1,2 更改状态为 FOLLOWING,服务器 3 更改状态为 LEADING;
(4)服务器 4 启动,发起一次选举。此时服务器 1,2,3 已经不是 LOOKING 状态,不会更改选票信息。交换选票信息结果:服务器 3 为 3 票,服务器 4 为 1 票。
此时服务器 4 服从多数,更改选票信息为服务器 3,并更改状态为 FOLLOWING;
(5)服务器 5 启动,同 4 一样当小弟。
十、Zab协议
ZooKeeper原子广播协议 (ZooKeeper Atomic Broadcast protocol)。
状态更新的广播协议。
通过该协议来广播各个服务器的状态变更信息。
十一、INFORM消息
INFORM消息本质上是包含了正在被提交的 提议信息的提交消息。
十二、CAP
zookeeper 是 CP 模式。
参考资料:
基于Docker、Registrator、Zookeeper实现的服务自动注册

 浙公网安备 33010602011771号
浙公网安备 33010602011771号