ubuntu20安装Hadoop-2.8.0详细过程(第二步)| 后续配置及安装hadoop
1、关闭防火墙

2、配置IP和主机
终端输入:
sudo gedit /etc/netplan/01-network-manager-all.yaml
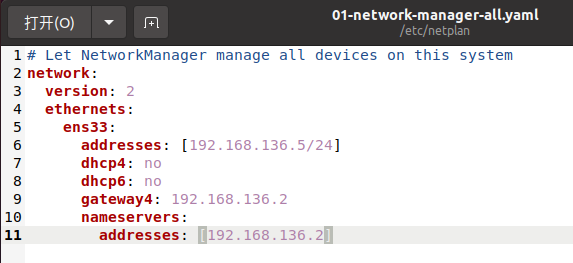
切换到root账户:
su root
修改机器名称:
gedit /etc/hostname

机器名称和IP绑定:
gedit /etc/hosts
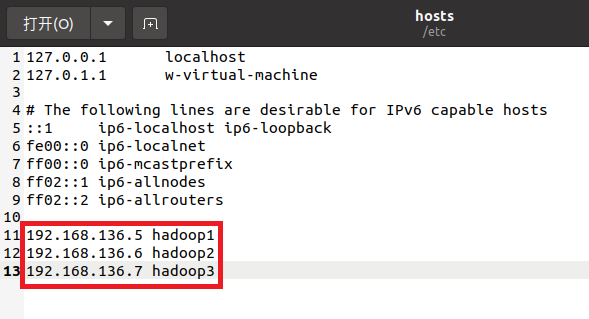
这里先这么写,hadoop2和hadoop3是后边要要复制的2台虚拟机,为的是随后这三台主机可以免密登录,至于免密登录的设置随后再做。
重启虚拟机。
在终端输入ifconfig
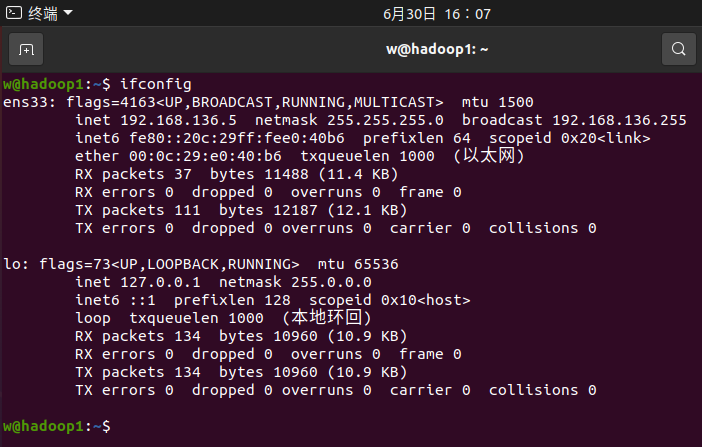
IP与刚刚设置的一样。
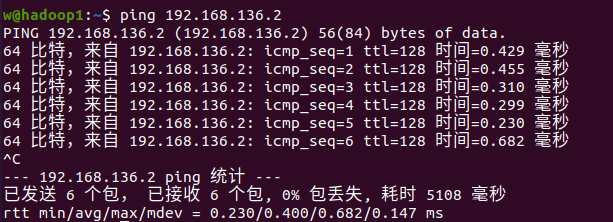
再ping一下网关,可以ping通即可。
再用xshell连接一下,可以连上即为成功。
3、复制虚拟机
3.1关闭虚拟机
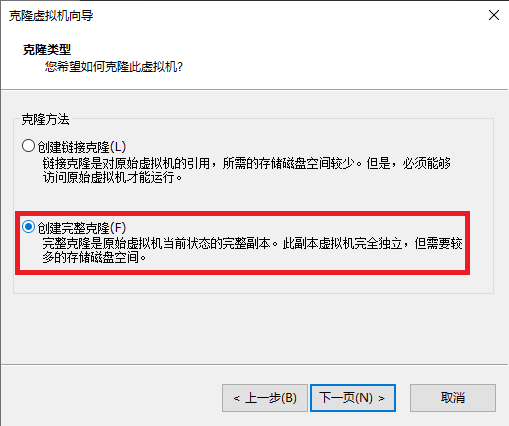
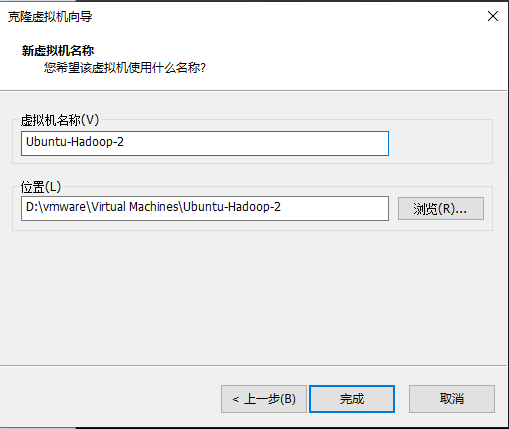
同样的方法克隆另外2台虚拟机。
克隆完成后如下图所示:
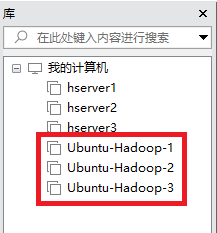
然后按前面的步骤修改hadoop2和hadoop3中的主机名和ip, 注意不要重复并且在root用户下修改,修改完以后reboot重启。
4、安装JDK
Hadoop 是基于 Java 语言开发的,运行 Hadoop 需要安装 JDK。
切换到root账户,升级文件夹权限:
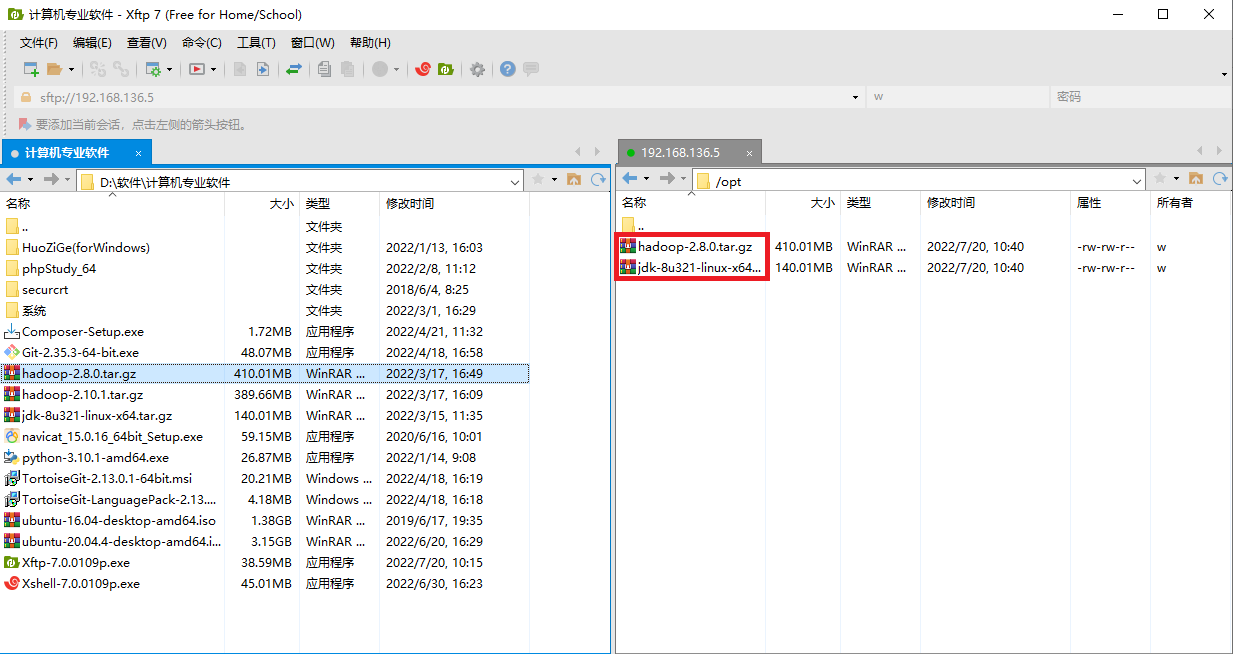
通过XFTP将Linux版本的jdk和hadoop压缩包传到hadoop1:

终端输入:
sudo tar -zxvf jdk-8u321-linux-x64.tar.gz -C /opt/
然后
sudo vi /etc/profile
在后面添加java路径:
export JAVA_HOME=/opt/jdk1.8.0_321 export CLASSPATH=$JAVA_HOME/lib export PATH=$PATH:$JAVA_HOME/bin
运行如下命令,使其生效
source /etc/profile
然后:
java -version

即为安装成功。
hadoop2、hadoop3也需安装。
5、安装Hadoop
终端输入:
sudo tar -zxvf hadoop-2.8.0.tar.gz -C /opt
添加权限:
chown -R root ./hadoop-2.8.0
修改~/bashrc文件,在后面添加hadoop路径:
sudo vi /etc/profile
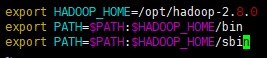
export HADOOP_HOME=/opt/hadoop-2.8.0 export CLASSPATH=$HADOOP_HOME/bin/hadoop export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
然后,再刷新一下:
source /etc/profile
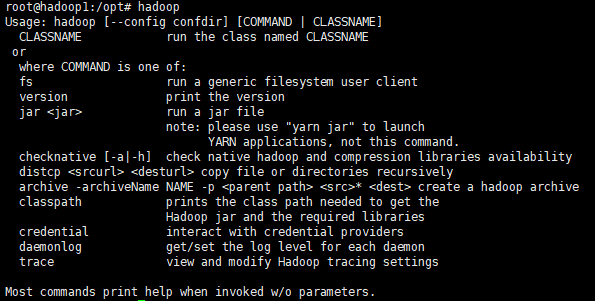
输入hadoop正常显示信息即为安装正常。
hadoop2、hadoop3也需安装。
6、配置环境变量
命令输入:
sudo vim ~/.bashrc
末尾加上:
#配置jdk环境变量
export JAVA_HOME=/opt/jdk1.8.0_321
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=$PATH:${JAVA_HOME}/bin
#配置hadoop环境变量
export HADOOP_HOME=/opt/hadoop-2.8.0
export PATH=$PATH:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin
命令输入:
source ~/.bashrc
使其生效。
hadoop2、hadoop3也需操作上述步骤。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号