Executor等系列概念介绍
这里对几个常见的的名词进行介绍
Executor
这是个接口,只声明了一个方法——
public interface Executor { void execute(Runnable command);---执行一个Runnable对象 }
Executors
然后是Executors类,这个可以看作是个公共类,它提供了许多强大有用的获取线程池的static方法:
1.public static ExecutorService newFixedThreadPool(int nThreads)
创建固定数目线程的线程池。
2.public static ExecutorService newCachedThreadPool()
创建一个可缓存的线程池,调用execute将重用以前构造的线程(如果线程可用)。如果现有线程没有可用的,则创建一个新线 程并添加到池中。终止并从缓存中移除那些已有 60 秒钟未被使用的线程。
3.public static ExecutorService newSingleThreadExecutor()
创建一个单线程化的Executor。
4.public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize)
创建一个支持定时及周期性的任务执行的线程池,多数情况下可用来替代Timer类。
ExecutorService
这也是个接口,继承了Executor接口。我觉得这个可以理解成一个代表可控线程池的一个接口,是Java提供的一个线程池,也就是说,每次我们需要使用线程的时候,可以通过ExecutorService获得线程。它可以有效控制最大并发线程数,提高系统资源的使用率,同时避免过多资源竞争,避免堵塞,同时提供定时执行、定期执行、单线程、并发数控制等功能,也不用使用TimerTask了。
ExecutorService接口继承自Executor接口,它提供了更丰富的实现多线程的方法,比如,ExecutorService提供了关闭自己的方法,以及可为跟踪一个或多个异步任务执行状况而生成 Future 的方法。 可以调用ExecutorService的shutdown()方法来平滑地关闭 ExecutorService,调用该方法后,将导致ExecutorService停止接受任何新的任务且等待已经提交的任务执行完成(已经提交的任务会分两类:一类是已经在执行的,另一类是还没有开始执行的),当所有已经提交的任务执行完毕后将会关闭ExecutorService。因此我们一般用该接口来实现和管理多线程。
ExecutorService的生命周期包括三种状态:运行、关闭、终止。创建后便进入运行状态,当调用了shutdown()方法时,便进入关闭状态,此时意味着ExecutorService不再接受新的任务,但它还在执行已经提交了的任务,当素有已经提交了的任务执行完后,便到达终止状态。如果不调用shutdown()方法,ExecutorService会一直处在运行状态,不断接收新的任务,执行新的任务,服务器端一般不需要关闭它,保持一直运行即可。
线程池实现类——ThreadPoolExecutor
这个类可以说是Exector框架的核心所在,Executors工具类中提供的很多线程池都是产自这个ThreadPoolExecutor类的构造方法,只是不同的线程池用了不同的默认参数而已。
public ThreadPoolExecutor(int corePoolSize, ----池子里面的线程数量,即便idle状态的线程也会保留这个数量 int maximumPoolSize,----池子里面能盛放最大线程数量 long keepAliveTime,----当线程数量大于core核心数量的时候,并且里有idle状态的线程,那么最大可以被terminate的的等待时间 (就是在cpu借的线程资源如果闲置多久就必须还回去) TimeUnit unit,--timeUnit BlockingQueue<Runnable> workQueue,---任务的队列 ThreadFactory threadFactory,---线程工厂 RejectedExecutionHandler handler) {---线程池处理不过来任务队列的时候的默认处理方法 if (corePoolSize < 0 || maximumPoolSize <= 0 || maximumPoolSize < corePoolSize || keepAliveTime < 0) throw new IllegalArgumentException(); if (workQueue == null || threadFactory == null || handler == null) throw new NullPointerException(); this.corePoolSize = corePoolSize; this.maximumPoolSize = maximumPoolSize; this.workQueue = workQueue; this.keepAliveTime = unit.toNanos(keepAliveTime); this.threadFactory = threadFactory; this.handler = handler; }
如果你了解这个ThreadPoolExecutor类,可以直接用它来自定义自己想要的线程池,如果不熟就直接用Executors来获取呗。
上个Executor系列框架的类图:
(图来自:https://www.cnblogs.com/congsg2016/p/5621746.html)
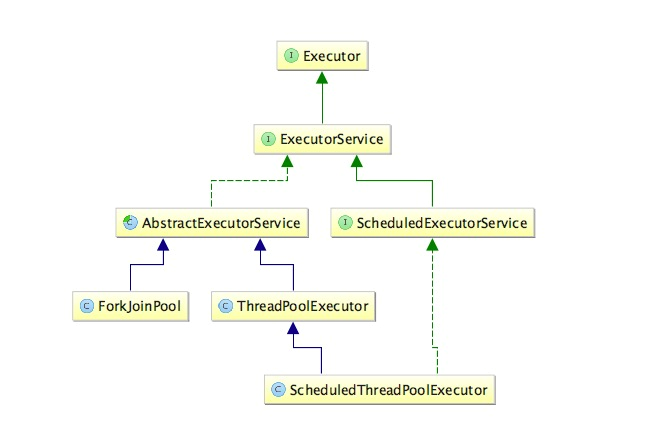
这个AbstractExecutorService就一个实现了ExecutorService接口的抽象类;
然后这个ScheduleExecutorService是和时间、周期操作有关的线程池接口,继承了ExecutorService接口;
这个ScheduledThreadPoolExecutor无疑是这个和时间周期相关的实现类,这个类继承了ThreadPoolExecutor类并实现了ScheduledExecutorService接口;
这个ForkJoinPool的优势在于,可以充分利用多cpu,多核cpu的优势,把一个任务拆分成多个“小任务”,把多个“小任务”放到多个处理器核心上并行执行;当多个“小任务”执行完成之后,再将这些执行结果合并起来即可。这种思想值得学习。
Callable和future
这两个都是接口。
Callable接口代表一段可以调用并返回结果的代码;Future接口表示异步任务,是还没有完成的任务给出的未来结果。所以说Callable用于产生结果,Future用于获取结果。
callable一般是配合ExecutorService来使用的,callable可以类比Runnable,但它是一个可以获得结果的Runnable。当你想获得一个线程的运行结果的时候,就可以用这个接口了。
Future就是对于具体的Runnable或者Callable任务的执行结果进行取消、查询是否完成、获取结果。必要时可以通过get方法获取执行结果,该方法会阻塞直到任务返回结果。
Future接口:
public interface Future<V> { boolean cancel(boolean mayInterruptIfRunning); boolean isCancelled(); boolean isDone(); V get() throws InterruptedException, ExecutionException; V get(long timeout, TimeUnit unit) throws InterruptedException, ExecutionException, TimeoutException; }
分别介绍下这几个方法:
cancel方法用来取消任务,如果取消任务成功则返回true,如果取消任务失败则返回false。参数mayInterruptIfRunning表示是否允许取消正在执行却没有执行完毕的任务,如果设置true,则表示可以取消正在执行过程中的任务。如果任务已经完成,则无论mayInterruptIfRunning为true还是false,此方法肯定返回false,即如果取消已经完成的任务会返回false;如果任务正在执行,若mayInterruptIfRunning设置为true,则返回true,若mayInterruptIfRunning设置为false,则返回false;如果任务还没有执行,则无论mayInterruptIfRunning为true还是false,肯定返回true。
isCancelled方法表示任务是否被取消成功,如果在任务正常完成前被取消成功,则返回 true。
isDone方法表示任务是否已经完成,若任务完成,则返回true;
get()方法用来获取执行结果,这个方法会产生阻塞,会一直等到任务执行完毕才返回;
get(long timeout, TimeUnit unit)用来获取执行结果,如果在指定时间内,还没获取到结果,就直接返回null。
FutureTask类
也就是说Future提供了三种功能:
1)判断任务是否完成;
2)能够中断任务;
3)能够获取任务执行结果。
因为Future只是一个接口,所以是无法直接用来创建对象使用的,因此就有了下面的FutureTask。
FutureTask类实现了RunnableFuture接口——
public interface RunnableFuture<V> extends Runnable, Future<V> { void run(); }
其他另外自行查询
然后上一个例子来理解下Future-Callable机制:
这是个用两条线程一起寻找数组最大值的例子:
先是Callable实现类:
import java.util.concurrent.Callable; class FindMaxTask implements Callable<Integer> { private int[] data; private int start; private int end; FindMaxTask(int[] data, int start, int end) { this.data = data; this.start = start; this.end = end; } public Integer call() { int max = Integer.MIN_VALUE; for (int i = start; i < end; i++) { if (data[i] > max) max = data[i]; } return max; } }
这个call方法就有点像Runnable里面的run方法,但区别是当这个Callable所代表的线程run起来后,结束后会返回一个结果,而这个结果我们待会通过Future类可以获得。
import java.util.concurrent.*; public class MultithreadedMaxFinder { public static int max(int[] data) throws InterruptedException, ExecutionException { if (data.length == 1) { return data[0]; } else if (data.length == 0) { throw new IllegalArgumentException(); } // split the job into 2 pieces FindMaxTask task1 = new FindMaxTask(data, 0, data.length/2); FindMaxTask task2 = new FindMaxTask(data, data.length/2, data.length); // spawn 2 threads ExecutorService service = Executors.newFixedThreadPool(2); Future<Integer> future1 = service.submit(task1); Future<Integer> future2 = service.submit(task2); return Math.max(future1.get(), future2.get()); } }
这个代码下,两个子数组都是同时被搜索。
有一点要注意一下,当future1.get()方法被调用的时候,这个方法会被阻塞了,或者说理解成这个方法所在的线程(也就是主线程)会阻塞,直到这个future1代表的callable线程完成了它的call方法并返回结果后,才会调用future2.get()方法,所以很可能future2所表示的线程提前完成也就提前找到了第二个数组的max,这样future1.get()完后立刻调用future2.get()就可以获得值。
所以,利用ExecutorService、callable还有Future可以让我们可以创建很多不同的线程,然后按照需要的顺序得到我们想要的答案。
参考文章:
https://www.cnblogs.com/fengsehng/p/6048610.html——《为什么引入Executor线程池框架》讲线程池怎么用,很多例子
https://www.cnblogs.com/congsg2016/p/5621746.html——讲Executor框架中各个类、接口的大概关系
https://www.cnblogs.com/fengsehng/p/6048609.html——《Java程序员必须掌握的线程知识-Callable和Future》讲Callable、Future还有FutureTask

 浙公网安备 33010602011771号
浙公网安备 33010602011771号