Python 基础代码
1.1 Python语言概述
Python语言特点
- 简洁方便:Python提供了强大的字符串处理库函数
- 跨平台:一次编写,到处运行
- 功能强大:动态类型、自动内存管理、大型程序支持、易于扩展、丰富的内置对象、丰富的内置工具、丰富的库工具、丰富的第三方工具
- 面向对象
- 应用广泛
Python语言主要应用领域
- 云计算
- WEB开发
- 科学计算与人工智能
- 桌面GUI
- 游戏
Python的环境与安装
- IDLE
- Anaconda
- Pycharm
- Jupyter notebook
1.2 Python基本语法
标识符
- 作用:作为变量、函数、类、模块以及其他对象的名称
- 规则:1.字母、数字、下划线组成,数字不开头,中间不能有空格;2.不能和Python内置关键字相同;3.标识符可以是中文、日文、俄文等Unicode字符集支持的字符
下示Python所有内置关键字:
import keyword
keyword.kwlist
['False',
'None',
'True',
'__peg_parser__',
'and',
'as',
'assert',
'async',
'await',
'break',
'class',
'continue',
'def',
'del',
'elif',
'else',
'except',
'finally',
'for',
'from',
'global',
'if',
'import',
'in',
'is',
'lambda',
'nonlocal',
'not',
'or',
'pass',
'raise',
'return',
'try',
'while',
'with',
'yield']
Python编码
- Python3默认源文件以UTF-8编码,所有字符串以unicode编码
- 采用非默认编码需要在文件的第一行添加一个特殊的注释行,如下:
#_*_coding=enconding_*_
#其中encoding 是Python支持的有效编码方式之一
Python 关键字
- 关键字即保留字,不能作为任何标识符的名称
- Python标准库提供一个keyword模块,可以输出当前版本所有关键字
import keyword
keyword.kwlist
['False',
'None',
'True',
'__peg_parser__',
'and',
'as',
'assert',
'async',
'await',
'break',
'class',
'continue',
'def',
'del',
'elif',
'else',
'except',
'finally',
'for',
'from',
'global',
'if',
'import',
'in',
'is',
'lambda',
'nonlocal',
'not',
'or',
'pass',
'raise',
'return',
'try',
'while',
'with',
'yield']
注释
- 单行注释:以 # 开头
- 多行注释:;''' '''
连续行
- 使用反斜杠连续,当语句中包含[],{},()就不需要连续符
空行
- 空行分割两段不同功能或含义的代码,便于日后维护或重构
缩进
- Python中代码块层次关系是通过缩进来体现的
- 首行无缩进
- 使用' : '开始一个新的逻辑层
字面值
- 数值字面值:整数、浮点数、虚数
- 字符串字面值:‘a’,'abc','123'
常量
- Python常量名只能由大写字母和下划线构成
- 常量定义完成后不能再修改它的内容
- Python内置常量有True、False、Notlmplemented、Ellipsis、debug
True=0
File "C:\Users\ADMINI~1\AppData\Local\Temp/ipykernel_10928/1874625572.py", line 1
True=0
^
SyntaxError: cannot assign to True
变量
- Python变量不需要声明就可以直接赋值,变量的数据类型可以随时改变
- Python中,允许多个变量指向同一个值
- 变量在赋值(=)时就开辟了一个内存空间,内存值就是__等号右边的值__
- Python把一切数据都看成对象,它为每一个对象都分配一个内存空间,每个对象一旦被创建它的id就不会变化
- 当一个对象被创建后,它就不能被销毁,当没有变量指向该对象时,Python垃圾回收算法回收
Python修改变量指向,C修改变量的内容
a=1
id(a)
2645669734704
a=a+1
id(a)
2645669734736
表达式
- 表达式由运算符和操作数组成
- 产生或者计算新数据值的程序代码片段称为表达式
基本运算符
- + - * / %(取余) **(幂) //(地板除)
- 注意Python2中还是默认整数与整数相除的结果为整数
print(1+1)
print(10-1)
print(3*6)
print(10/2)
print(10/3)
print(2**3)
print(10//3)
2
9
18
5.0
3.3333333333333335
8
3
逻辑表达式
- and、or、not
- is、is not
- ==、!=
- is不仅仅判断两个对象内容是否相同,还需要判断两个对象地址是否相同
a=1
b=a
a is b
True
a=1
a=10
c=10
a is c
True
id(a)
2645669734704
id(b)
2645669734992
id(c)
2645669734704
关系表达式
- ==、!=
-
、>=、<、<=
位运算
- 对于正数,原码就是直接换算的二进制,补码、反码与原码相同
- 对于负数,原码就是直接换算的二进制,反码就是原码符号位不变其余各位取反,补码就是反码+1
- &、|、^、~、<<、>>
其它运算
- 赋值运算:=,+=,-=,*=,/=,%=,**=,//=
- 三元条件表达式:x if C else y
- 成员运算符 in,not in
输出 print()
- 控制台输出
- print()
** 格式化输出
** %
** format # 位置对应
** f
a=18
a
18
print("The age of {} is {}.".format("Bob",a))
The age of Bob is 18.
print("The age of {} is {}.".format(a,"Bob"))
The age of 18 is Bob.
b=("Bob",18)
print("The age of {0[0]} is {0[1]}.".format(b))
The age of Bob is 18.
b=("Bob",18)
print("The age of {b[0]} is {b[1]}.")
The age of {b[0]} is {b[1]}.
b=("Bob",18)
print(f"The age of {b[0]} is {b[1]}.")
The age of Bob is 18.
输入input()
- 参数提示字符串
- 返回值string
- 如何一次输入多个值???
a=input("请输入一个值:")
print(a)
请输入一个值:214434
214434
print(type(a))
<class 'str'>
print(a*3) # 字符串 * 代表重复
214434214434214434
a,b,c,d=input("输入四个值:").split()
e,f,g,h=input("输入四个值:").split(',')
输入四个值:1 2 3 4
输入四个值:5,6,7,8
a+e
'15'
eval(a+e)
15
eval(a)+eval(e)
6
条件语句
- python条件语句模板
if condition1:
block1
elif condition2:
block2
else condition3:
block3
- python中跟在if后面的condition不需要加括号
- python 3.10之前没有switch—case语句
循环语句
- 不定循环
while condition:
statement1
else:
statement2
- 确定循环
for 变量 in 可迭代对象:
statement1
else:
statement2
- 外加两个循环控制关键字,continue、break
- 可迭代对象指的是,元组、列表、字符串、range()
模块
- 模块是包含函数定义、类定义和变量的文件,后缀.py
- 模块的意义就是避免重复造轮子
- import numpy #导入模块
- import scipy,matplotlib #一次导入多个模块
- from……import…… #导入指定的内容
异常处理
try:
statement1
except[ExceptionName[as alias]]:
statement2
else:
statement3
finally:
statement4
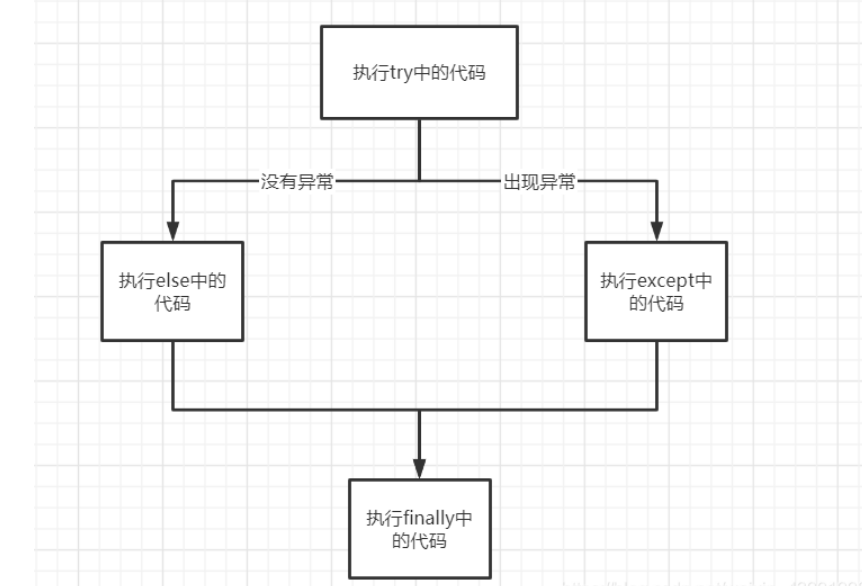
1.3 Python 数据类型
- 数字类型:int、float、bool、complex
整数 int
** int整型数据四种表示方式:十进制、二进制 0b1001、八进制)0o567、十六进制0x12fe
** type()可以查看数据类型
** int(),oct(),hex(),float()可以进行数据类型转换
浮点数 float
** 二进制下浮点数都是不准确的,解决方案是引入decimal模块,见下例:
a=0.1
b=0.2
c=0.3
a+b-c
5.551115123125783e-17
import decimal as dc
a=dc.Decimal('0.1')
b=dc.Decimal('0.2')
c=dc.Decimal('0.3')
print(a+b-c)
0.0
复数
a=1+2j
a.real
a.imag
2.0
字符串 string
- 使用单引号或者双引号创建字符串
- 反斜杠用于字符转义
- ‘r’用于防止字符转义
- 包含单引号的字符串用双引号创建
- 包含双引号的字符串用单引号创建
- 反斜杠用自身转义 \
c="I'm a student"
print(c)
I'm a student
d='I\'m a teacher'
print(d)
I'm a teacher
addr='C:\Users'
File "C:\Users\ADMINI~1\AppData\Local\Temp/ipykernel_17216/2268028194.py", line 1
addr='C:\Users'
^
SyntaxError: (unicode error) 'unicodeescape' codec can't decode bytes in position 2-3: truncated \UXXXXXXXX escape
addr='C:\\Users'
print(addr)
C:\Users
addr=r'C:\Users'
print(addr)
C:\Users
-
字符串索引
** StringName[Index]
** 支持负数索引 -
字符串截取
** StringName[SI:EI:step]
** StringName[SI:EI:step]中缺省值代表默认 -
字符长度
** len(string)获取字符串的字符数 -
字符串操作符
** 连接符+
** 复制符*
** 成员搜索符 in
** 成员搜素符 not in
** 原始字符串 r -
字符检索
** 统计指定字符串在另一个字符串中出现的次数 str.count(sub[start,[,end]])
** 是否包含指定的子字符串 str.find(sub[sart[,end]]),返回正向索引值,否则返回-1
** 是否以指定的字符串开头/结尾 str.startwith(sub[start,[,end]]),str.endwith(sub[start,[,end]]) -
字符串格式化
** 将字符(串)插入到带有字符串格式的字符中 %d,%s,%f
** %[-][+][0][m][.n] %exp,exp是要转换的项,如果有多个项则必须用元组来指定
** 字符串格式化函数 str.format()
{[index][:]}
** 位置映射
** 关键字映射
** 索引映射
string="ULOVENWPU"
print(string[1])
print(string[1:3:1])
print(string[-1::-1])
print(len(string))
print(string.count('U'))
print(string.find('O'))
'W'in string
item=('Daming',"NWPU")
print("I'm %s, a student in %s" %item)
L
LO
UPWNEVOLU
9
2
2
I'm Daming, a student in NWPU
列表 list
-
创建列表&删除列表
** 使用元素填充,lister=[元素1,元素2,……]
** 使用list()函数,lister=list(可迭代对象)
** 删除列表 del lister -
列表索引和切片
** 索引:获取指定位置的元素
** 切片:获取指定位置范围的元素 -
遍历列表
** for item in lister
** enumerate(lister) 输出索引值和元素值 -
列表添、删、改
** lister.append(新元素) 列表末尾追加元素
** lister.insert(Index,新元素) 指定位置插入新元素
** lister.entend(新列表) 将一个新列表插入列表后面
** 通过索引值获取元素并修改之
** del 删除指定位置
** remove 删除指定元素
-
列表统计计算
** lister.count(目标元素) 获取指定元素出现的次数
** lister.index(目标元素) 获取指定元素首次出现的索引值
** sum(lister) 列表元素求和 -
列表排序
** lister.sort() 列表对象方法
** sorted(interable,key=None,reverse=False) 内置函数BIM
lister1=["DaMing",1]
lister2=[list(range(10))]
print(lister1)
print(lister2)
print(list("Hello"))
del lister1[1]
lister1.remove("DaMing")
print(lister1)
['DaMing', 1]
[[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]]
['H', 'e', 'l', 'l', 'o']
[]
### 列表推导式
lister1=[]
for i in range(8):
lister1.append(i)
print(lister1)
### 快速列表生成
# lister = [Expression for var in range]
# lister = [Expression for var in list]
# newlister = [Expression for var in list if condition]
lister2=[i for i in range(18)] #range(n):0到n-1
print(lister2)
lister3=[i*i for i in lister2 if i%2==0]
print(lister3)
[0, 1, 2, 3, 4, 5, 6, 7]
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17]
[0, 4, 16, 36, 64, 100, 144, 196, 256]
二维列表
- 创建 matrix=[[1,2,3],[4,5,6],[7,8,9]]
- 二维列表推导式 seats=[[i*10+j for j in range(1,6)] for i in range(1,5)]
列表操作总结
- .append(x) # 添加元素x到列表末尾
- .sort(x) #
- .reverse(x)
- .index(x) # 返回指定元素的索引
- .insert(i,x)
- .count(x)
- .remove(x)
- .pop(x)
- len(list) # 求列表中元素个数
元组 Tuple
-
创建元组
** 逗号创建法 # 逗号才是元组的标志
** tuple() # 将可迭代对象转化为元组 -
访问元组
** print()打印
** 索引
** 切片 -
修改元组元素
** 元组不可以用索引修改元素,只能重新赋值
** 错误:c[6]=0
** 正确:c=(1,2,3) -
元组推导式
** tupler=tuple(Expression for var in interal)
a=(1)
b=(1,)
c=tuple(range(9))
print(type(a))
print(type(b))
print(type(c))
print(c[5])
print(c[-1:0:-1])
# c[6]=0
d=tuple(i*i for i in range(10))
print(d)
<class 'int'>
<class 'tuple'>
<class 'tuple'>
5
(8, 7, 6, 5, 4, 3, 2, 1)
(0, 1, 4, 9, 16, 25, 36, 49, 64, 81)
元组 V.S. 列表
字典
-
字典创建与删除
** 大括号创建
** zip() & dict()创建
** dict.fromkeys(interal) 创建值为空的列表
** del 删除整个字典
** dict.clear()删除字典元素 -
通过键访问值
** dict[key]
** dict.get(key[,default])函数 -
遍历字典
** dic.items() # 提取字典的每一个键值对生成列表
** dic.keys() # 提取字典的每一个键生成列表
** dic.values() # 提取字典的每一个值生成列表 -
添、改、删字典元素
** dic[key]=value
** del dic[key] -
字典推导式
** dic=dict({Key_Expression:Value_Expression for i in range(6)})
dic1={"Daming":"22","Xiaohong":"23","Limei":"24"} # 键必须唯一,值可以不唯一
list_key=list(("Daming","Xiaohong","Limei"))# 通过元组这个可迭代对象创建列表
list_vaule=list(("22","23","24"))# 通过元组这个可迭代对象创建列表
dic2=dict(zip(list_key,list_vaule)) # 通过dict()创建列表
print(dic2)
dic3=dict.fromkeys(tuple(i for i in range(9)))
print(dic3)
print(dic1["Xiaohong"])
print(dic1.get("Daming"))
print(dic1.items())
print(dic1.keys())
print(dic1.values())
dic4=dict({i:i*i for i in range(6)})
print(dic4)
{'Daming': '22', 'Xiaohong': '23', 'Limei': '24'}
{0: None, 1: None, 2: None, 3: None, 4: None, 5: None, 6: None, 7: None, 8: None}
23
22
dict_items([('Daming', '22'), ('Xiaohong', '23'), ('Limei', '24')])
dict_keys(['Daming', 'Xiaohong', 'Limei'])
dict_values(['22', '23', '24'])
{0: 0, 1: 1, 2: 4, 3: 9, 4: 16, 5: 25}
集合 set
-
集合中元素是无序且不可重复
-
集合创建
** 大括号创建
** set(interal)创建 -
集合添加元素
** set.add(element) # element只可以是字符串、数字、布尔类型,不可以是列表、元组等可迭代对象 -
集合中删除元素
** set.remove(element) # 删除一个指定元素
** set.pop(element) # 随机删除一个元素
** set.clear() # 删除所有元素 -
集合运算
** 交集 &
** 并集 |
** 差集 -,只在一个集合出现且在另一个集合不出现
** 对称差集 ^,只在其中一个集合出现
set1={"Zhangsan","Lisi","Laoliu"}
set2={tuple(i for i in range(10))}
set3={i for i in range(10)}
print(set1)
print(set2)
print(set3)
{'Laoliu', 'Lisi', 'Zhangsan'}
{(0, 1, 2, 3, 4, 5, 6, 7, 8, 9)}
{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
Python数据类型总结
-
可变/不可变数据类型
** 二者的本质区别在于:内存地址所存储的值是否可以修改
** 不可变数据类型:数据类型变量值变化则对应的地址也变化,如:整数、浮点数、字符串、元组
** 可变数据类型:数据类型变量值变化对应的地址不变化,如:列表、字典、集合 -
数据类型转化
** int(x,[,base]) # 将整数x转化成base制的整数
** float(x)
** complex(real[,imag]}
** str(x) # 将对象x转换成字符串
** eval(str) # 计算字符串中的有效Python表达式
** tuple(s) # 将序列s转换成一个元组
** list(s) # 将序列s转换成一个列表
** set(s) # 将序列s转换成一个集合
** dict(s) # 将序列s转换成一个字典
** chr(n) # 将整数n转换成一个字符
Numpy库
Pandas库
pandas 数据分析
- 数据分析就是以数据中提炼出内在规律为目的,用统计学方法,揭示不同数据之间存在关系,并绘制出统计信息图简洁的表示出数据中所包含的主要信息。
- pandas适用于含有异构列的表格数据,带行列标签的矩阵数据,无标记数据。
- pandas大数据处理,灵活性强,但可视化不强。
数据集的获取
df=pd.read_csv("medal.csv",encoding='gb2312')
df=pd.read_html("medal.csv",encoding='gb2312')
print(df)
df.shape
df.dtypes
df.columns
df.describe
建立索引
df.set_index("国家地区奥委会",inplace=True) # 设置“国家地区奥委会”为新的行索引(设置为第一列)
df.columns=["RankByGold","Gold","Silver","Bronze","Score","RankByScore","CountryNo"] # 列索引命名
数据筛选
-
选择某一列
df["CodeNo"] #打印"CodeNo"这一列
df.Gold #打印Gold这一列
df[["CodeNo","Score"]] #打印多列
df.loc[:,["CodeNo","Score"]] # .loc[[row],[cow]]强大的数据选择函数, -
选择某一行
df[0:5]
df.loc[["美国","中国","ROC"],:] -
行列都选择
df.loc[["中国","ROC"],["Gold","Silver"]]
df.iloc[0:5,1:4] -
用条件表达式
df[df.Score>50]
df[df.CodeNo=="ROC"]
df[df.Score>30].loc[df.Bronze>=20] -
数据聚合
contienTable=pd.read_json{"continent.json",orient="recodes"}
contientTable.columns -
数据分组 pandas支持表格按指定列合并
将df和continentTable的两列,按照”国家奥组委”和”Country”两列作为参考键,进行合并
nemdf=pd.merge(df,continentTable[["CountryReg","Continent"]],left_on="国家地区奥委会",right_on="CountryReg",how="left")
手动修改俄罗斯的NAN值,因为俄罗斯的参赛名称是”ROC”
newdf.loc[newdf.CodeNo=="ROC", ("CountryReg","Continent")]=["俄罗斯","欧洲"]
重新设置行索引
newdf=newdf.set_index("CountryReg")
对分组的所有数据进行按列求和
newdf.groupby["Continent"].sum()
对分组所有数据按列求平均值
newdf.groupby("Continent").mean()
- 数据可视化
Pandas可以通过plot()函数调用matplotlib的绘图工具,快速绘制可视化图表
df["Score"].plot()
newdf.gorupby("Continent").Score.sum().plot.pie()
df.loc[["美国","中国"],["Gold","Silver","Bronze"]].plot.bar()
pandas数据结构
- pandas的数据分析与处理都是在DataFrame和Series两个容器上的操作展开的。
- DataFrame和Series都是基于Numpy的,因此pandas支持切片索引操作
创建Series,Series是一维有标签的数组,可以容纳整型、字符串、Python对象等多种数据
index <---> data
- 创建Series,s=pd.Series(data,index=index) # data可以是字典、ndarray或者标量
** 如果data是一个ndarray,index必须和data长度相等,如果不指定index则index默认为[0,…,len(data)-1]
s = pd.Series(np.random.randn(4), index=["a", "b", "c", "d"]) #指定index
a 0.2
b 0.7
c 0.3
d 0.9
s=pd.Series(np.random.randn(4)) #不指定index
0 0.2
1 0.7
2 0.3
3 0.9
** 如果data是一个字典,若没指定index,Series的index将会是index的字典key;若指定index,Series的index将会是指定的index
data= {"a": 20, "b": 15, "c": 19}
s=pd.Series(data) #不指定index, 结果如左下
a 20
b 15
c 19
s=pd.Series(data, index=["b", "c", "d", "a"]) #指定index,结果如右下
b 20
c 25
d 19
Seriexs既像字典又像ndarray
(1) 像ndarray
s = pd.Series(np.random.randn(5), index=["a", "b", "c", "d", "e"]) #创建一个Series
s[0] # 位置索引
s[2:4] # 切片索引
s[[1,3,2]] #整数列表索引
s[s >= s.mean()] #s中大于均值的元素,用布尔列表访问
np.exp(s) # 作为参数与传入numpy函数
-
两个Series的index相同元素进行“+”操作,没有相同indexd的值去NaN,Series进行矢量化操作时会自动进行index进行对齐
-
Series对象实际上是由index(保存元素标签信息)和Values(保存元素值)组成。
(2) 像字典
s["a"] # 键索引
s["b"]=4.5 # 键访问
s["a":"d"] #对s用标签切片
"d" in s #判断s的index中是否有“d”
s.get("d") #通过get()函数
DataFrame是二维有标签数据结构,column类似Series的index,第一列数据是DataFrame的index属性,即行标签
- 创建DataFrame
(1) 从series对象的字典创建
d = {"one": pd.Series([1.0, 2.0, 3.0], index=["a", "b", "c"]), "two": pd.Series([1.0, 2.0, 3.0, 4.0], index=["a", "b", "c", "d"]), } #一个Series对象的字典,一个Series形成一列
(2) 从ndarray或者元组的字典创建
a=np.array([1,2,3,4])
b=np.array([5,6,7,8])
d=pd.DataFrame({"a1":a,"a2":b}) #字典的每一项,键成为列名,值成为列的值
pd.DataFrame(d)
(3) 从字典的列表创建 # 每一个字典会被当做DataFrame的一行
data2=[{"a":1,"b":2},{"a":5,"b":10,"c":20}]
df=pd.DataFrame(data2)
DataFrame索引选择数据
(1) []列选择、[]行选择、[]布尔表达式选择
(2) 通过标签选择 df.loc[label]
(3) 通过整数位置选择df.iloc[loc]
(4) 通过行列标签获取单个值df.at[r_index,c_index]
(5) 通过行列编号获取单个值df.iat[r_index,c_index]
DataFrame选取,增加,删除列,可以把DataFrame当做一个Series的字典
df=pd.DataFrame({"one":pd.Series([1.0,2.0,3.0],index=["a","b","c"]),"two":pd.Series([1.0,2.0,3.0,4.0],index=["a","b","c","d"])})#创建DataFrame
df["one"]#选取columns为”one”的列
df["three"]=df["one"]*df["two"] #增加一列”three”为前两列之积
df.insert(0,"zero",df["one"]) #用insert函数在指定位置插入新列
deldf["two"]#删除“two”列,效果如右图
DataFrame数据对齐,DataFrame会自动在index和column两个方向上进行数据对齐
Matplotlib库
深拷贝与浅拷贝???

 浙公网安备 33010602011771号
浙公网安备 33010602011771号