

2024.11.19
实验7
Spark初级编程实践
1.实验目的
(1)掌握使用Spark访问本地文件和HDFS文件的方法
(2)掌握Spark应用程序的编写、编译和运行方法
2.实验平台
(1)操作系统:Ubuntu18.04(或Ubuntu16.04);
(2)Spark版本:2.4.0;
(3)Hadoop版本:3.1.3。
3.实验步骤
(1)Spark读取文件系统的数据
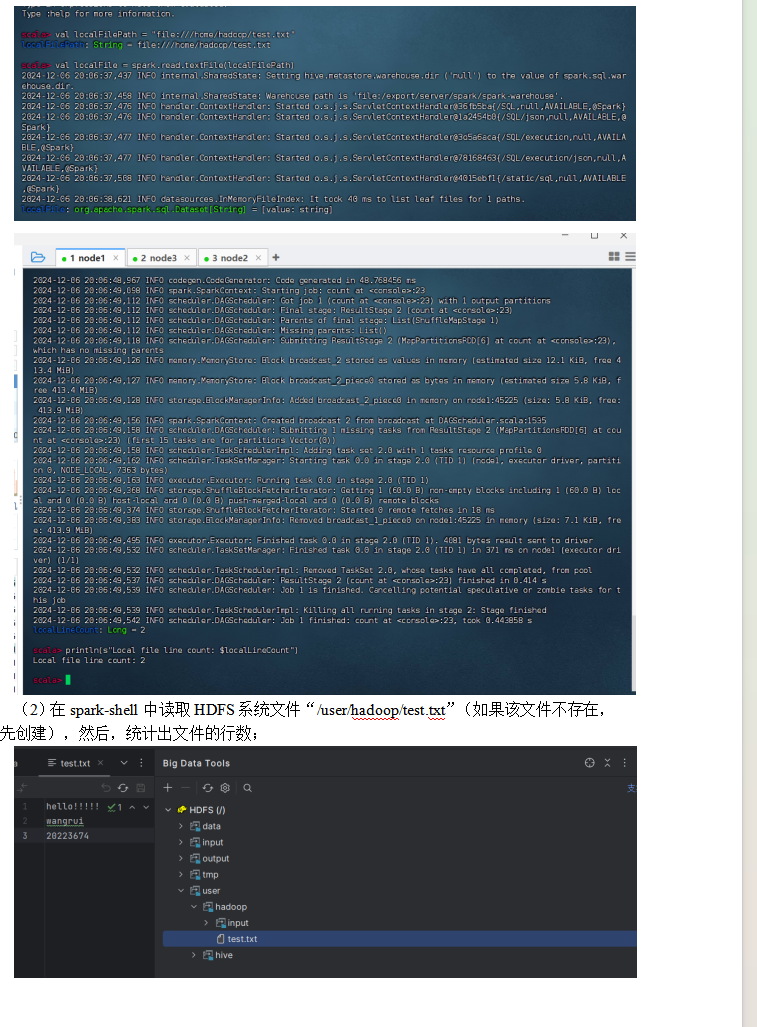
(1)在spark-shell中读取Linux系统本地文件“/home/hadoop/test.txt”,然后统计出文件的行数;
启动spark
val localFilePath = "file:///home/hadoop/test.txt"
val localFile = spark.read.textFile(localFilePath)
val localLineCount = localFile.count()
println(s"Local file line count: $localLineCount")

 浙公网安备 33010602011771号
浙公网安备 33010602011771号