c#抽取pdf文档标题(3)
上一篇介绍了整体流程以及利用库读取pdf内容形成字符集合。这篇着重介绍下,过滤规则,毕竟我们是使用规则过滤,最后得到标题的。
首先看归一化处理,什么是归一化呢?就是使结果始终处于0-1之间(包括0,1)。
1 private static double GetMark(BlockInfo block, double maxHeight, double maxWidth, double maxYSize, double maxXSize, double maxSpace) 2 { 3 double result = 0; 4 5 if (maxYSize > 0) 6 result += 0.4 * ((double)block.CharAveYSize / maxYSize); 7 8 if (maxXSize > 0) 9 result += 0.3 * ((double)block.CharAveXSize / maxXSize); 10 11 if (maxSpace > 0) 12 13 result += (block.CharAveSpace / maxSpace) * 0.1; 14 15 if (maxHeight > 0) 16 17 result += (block.CharAveHeight / maxHeight) * 0.1; 18 19 if (maxWidth > 0) 20 result += (block.CharAveWidth / maxWidth) * 0.1; 21 if (block.RepresentativeChar.IsBold) result += 0.1; 22 return result; 23 }
这段代码,就是给块打分的一个方法。它包含了投票思想以及归一处理问题的思想。对于一个块,我们从不同的角度,也就是不同方面的特征值给分,每个特征所占的权重是不同的。YSize权重:0.4,XSize权重:0.3,它们的分值是这样计算的:
权重*(块的平均特征值 / 文档中最大特征值),拿YSize来说,假如块的CharAveYSize=40,maxYSize=60,那么结果:0.4*(40/60)= 0.267。
在这里,我想说的是,特征一定要选正确,还有特征的权重也要相对正确,否则会影响到结果的匹配率。记得之前是以Space特征为主选取的,那时候还没有采用评分系统,经测试,提取标题的准确率在30%左右,后来,看了那个同事以前的代码,发现人家的代码写的如此简单,据说准确率在60%,“大道至简”,我就又重新找到核心属性,于是经过摸索,YSize这个属性相当重要,于是准确度到了70%左右。到最后,采用了评分机制,准确度到了85%左右,再经过努力,不断完善代码,准确度提升到了92%左右。有截图为证:
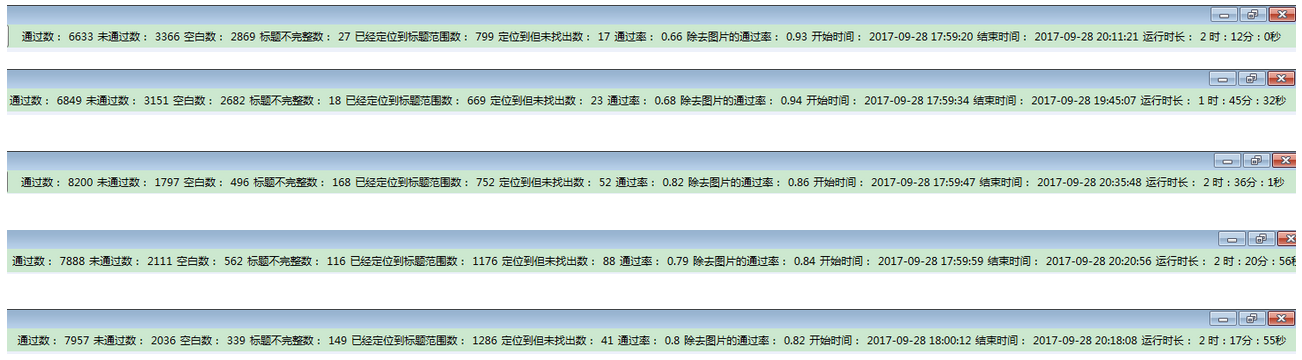
针对完全图片类型的pdf文档,我们现阶段不予处理。那么除了规则外,还有没有其它途径,来筛选标题呢?答案是肯定的,机器学习是当下一个热门领域,好了,我们下一篇就讨论这方面的话题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号