


并发编程之多线程
一.线程理论
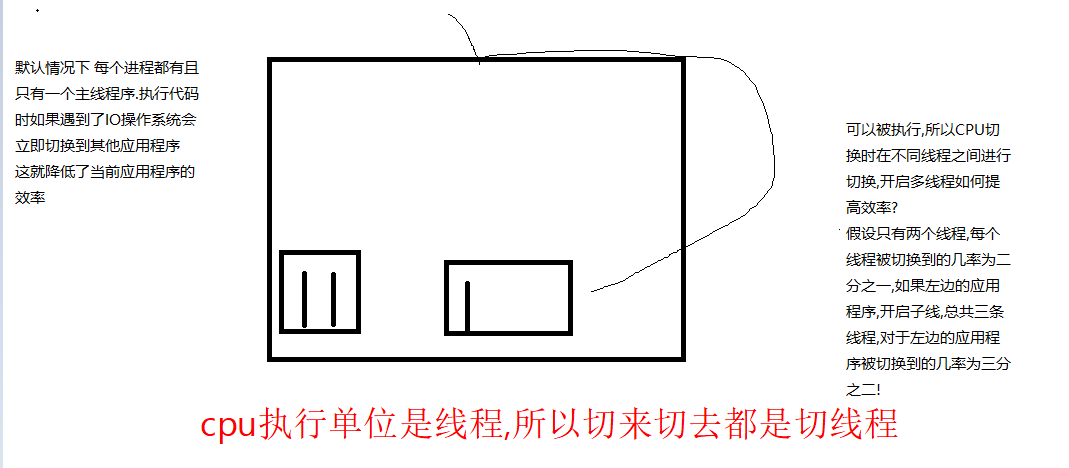
多进程
核心是多道技术
本质上就是切换加保存状态
当程序IO操作较多,可以提高程序效率
多线程
什么是线程?
程序的执行线路,每一个进程默认有一条线程,称之为主线程
相当于与一条流水线,其包含了程序的具体执行步骤
如果我们把操作系统比喻为一个工厂, 进程就是车间, 线程就是流水线
多线程也是用于提高程序的效率
线程和进程的关系
进程中包含了运行该程序需要所有的资源 *进程是一个资源单位, 线程是CPU的最小执行单位 * 每一个进程一旦被创建.就默认开启了一条线程, 称之为主线程 一个进程可以包含多个线程 进程包含线程,而线程依赖进程
为什么使用线程?
是为了提高程序效率,
为何不用多进程提高效率?
是因为进程对操作系统的资源耗费非常高
线程是如何提高效率的?
多线程可以使CPU在一个进程内进行切换, 从而提高cpu占用率
开启线程的方式
1.实例化Thread类
2.继承Thread类,覆盖run方法
什么情况下应该开启多线程?
当程序中遇到IO的时候
当程序中时纯计算任务时
也无法提高效率, 切线程无法提升效率,还会降低效率
进程和线程的区别?
1.进程对于操作系统的资源耗费非常高, 而线程相反非常低(比进程低10 - 100倍)
2.在同一个进程, 多个线程之间资源是共享的


# 开启线程的第一种方式 from threading import Thread from multiprocessing import Process def task(): print("threading running!") t1 = Thread(target=task) t1.start() print("over") # 第二种方式 class MyThread(Thread): def run(self): print("子线程 running....") MyThread().start() print("over2") # 对比进程启动时间 # from multiprocessing import Process # # def task(): # print("threading running!") # if __name__ == '__main__': # # t1 = Process(target=task) # t1.start() # # print("over")
二.线程对比进程测试
#统计100个进程的执行时间 from multiprocessing import Process import time def task(): print("子进程任务...") if __name__=="__main__": start=time.time() ps=[] for i in range(100): p=Process(target=task) p.start() ps.append(p) for p in ps: p.join() print(time.time()-start)
#统计100个线程的执行时间 from multiprocessing import Process from threading import Thread import time def task(): print("子线程任务...") start=time.time() ts=[] for i in range(100): t=Thread(target=task) t.start() ts.append(t) for t in ts: t.join() print(time.time()-start)
得到结论线程效率高很多
三.线程间资源的共享
from threading import Thread x = 100 def task(): print("run....") global x x = 0 t = Thread(target=task) t.start() t.join() print(x) print("over")
四 .守护线程
守护线程
守护线程会在所有非守护线程结束后结束
三个线程 分别 皇帝 太子 和皇后
如果把皇后设置为守护线程 那么皇后线程会在 太子和皇帝都死亡后死亡
当所有非线程结束后 守护线程也跟着结束了
进程 守护进程会在被守护进程死亡跟着死亡
同一个进程 可以有多个守护线程
单个线程设置为护线程
from threading import Thread import time def task(): print("sub thread run...") time.sleep(3) print("sub thread over...") t=Thread(target=task) t.setDaemon(True) t.start() t=Thread(target=task) t.setDaemon(True) t.start() print("over")
四.线程常用属性
from threading import Thread,current_thread,enumerate,active_count import os def task(): print("running..") # print(os.getpid()) # print(current_thread()) print(active_count()) t1 = Thread(target=task) t1.start() # print(t1.is_alive()) # print(t1.isAlive()) # print(t1.getName()) # 获取所有线程对象列表 print(enumerate()) # 获取当前线程对象 print(current_thread()) # 获取当前正在运行的线程个数 print(active_count()) # t2 = Thread(target=task) # t2.start()
五.线程的互斥锁
什么时候用锁 当多个进程或者多个线程需要同时修改同一份数据时.可能会造成数据的错乱,所以必须得加锁
a=100 def task(): global a #当局部修改全局变量的时候用global a-=1 from threading import Thread for i in range(100): t=Thread(target=task) t.start() print(a)#数据是共享的,你减一次,我减一次最后结果是0
import time from threading import Thread,Lock lock =Lock() a = 100 def task(): lock.acquire() global a temp = a - 1 time.sleep(0.01) a = temp lock.release() for i in range(100): t = Thread(target=task) t.start() t.join()#这个是在等最后一个,但是不能保证最后一个线程最后执行 print(a)
import time from threading import Thread,Lock lock =Lock() a = 100 def task(): lock.acquire() global a temp = a - 1 time.sleep(0.01) a = temp lock.release() ts = [] for i in range(100): t = Thread(target=task) t.start() ts.append(t) for t in ts: t.join() print(a)
线程也会有死锁问题
六.信号量
信号量
其实也是一种锁,特点是可以设置一个数据可以被几个线程(进程)共享
与普通锁的区别
普通锁一旦加锁 则意味着这个数据在同一时间只能被一个线程使用
信号量 可以让这个数据在同一时间只能被多个线程使用
使用场景,可以限制一个数据被同时访问的次数,保证程序正常运行
from threading import Semaphore,Thread,current_thread #,获取当前的线程是谁current,Thread import time,random sem = Semaphore(3) #一个公共厕所里面有3个坑 def task(): sem.acquire() print("%s run..." % current_thread()) time.sleep(3) sem.release() for i in range(10): t = Thread(target=task) t.start() # 代码的意思:我有10个线程,来一个就先加锁,加完锁就执行,执行完睡3秒,睡的过程中别的人可以进来,第二个人进来了,然后执行代码 # 然后第二个人再睡3秒,然后第三个人进来,然后重复前面2个人的行为,然后第四个人就进不来了,因为坑满了 # 信号量的意义:本来之前一个数据被一个人共享,现在我们改用信号量锁.他能够指定被几个人共享,如果超出这个数量就被锁起来了
七.GIL锁
八.进程池与线程池
8.1基于多线程实现并发的套接字通信
服务端
from socket import * from threading import Thread from concurrent.futures import ProcessPoolExecutor,ThreadPoolExecutor tpool=ThreadPoolExecutor(3) def communicate(conn,client_addr): while True: # 通讯循环 try: data = conn.recv(1024) if not data: break conn.send(data.upper()) except ConnectionResetError: break conn.close() def server(): server=socket(AF_INET,SOCK_STREAM) server.bind(('127.0.0.1',8080)) server.listen(5) while True: # 链接循环 conn,client_addr=server.accept() print(client_addr) # t=Thread(target=communicate,args=(conn,client_addr)) # t.start() tpool.submit(communicate,conn,client_addr) server.close() if __name__ == '__main__': server()
客户端
from socket import * client=socket(AF_INET,SOCK_STREAM) client.connect(('127.0.0.1',8080)) while True: msg=input('>>>: ').strip() if not msg:continue client.send(msg.encode('utf-8')) data=client.recv(1024) print(data.decode('utf-8')) client.close()
8.2为什么要用池子
池子使用来限制并发的任务数目,限制我们的计算机在一个自己可承受的范围内去并发地执行任务
8.3进程池的应用
# 池子内什么时候装进程:并发的任务属于计算密集型 from concurrent.futures import ProcessPoolExecutor,ThreadPoolExecutor import time,os,random def task(x): print('%s 接客' %os.getpid()) time.sleep(random.randint(2,5)) return x**2 if __name__ == '__main__': p=ProcessPoolExecutor() # 默认开启的进程数是cpu的核数 # alex,武佩奇,杨里,吴晨芋,张三 for i in range(20): p.submit(task,i)
8.4线程池的应用
池子内什么时候装进程:并发的任务属于计算密集型 from concurrent.futures import ProcessPoolExecutor,ThreadPoolExecutor import time,os,random def task(x): print('%s 接客' %os.getpid()) time.sleep(random.randint(2,5)) return x**2 if __name__ == '__main__': p=ProcessPoolExecutor() # 默认开启的进程数是cpu的核数 # alex,武佩奇,杨里,吴晨芋,张三 for i in range(20): p.submit(task,i)
九.同步、异步、阻塞、非阻塞
9.1阻塞与非阻塞指的是程序的两种运行状态
阻塞:程序遇到IO就发生阻塞,程序一旦遇到阻塞操作就会停在原地,并且立刻释放CPU资源
非阻塞(就绪态或运行态):程序没有遇到IO操作,或者通过某种手段让程序即便是遇到IO操作也不会停在原地,执行其他操作,力求尽可能多的占有CPU
9.2同步与异步指的是提交任务的两种方式
同步调用:提交完任务后,就在原地等待,直到任务运行完毕后,拿到任务的返回值,才继续执行下一行代码
异步调用:提交完任务后,不在原地等待,直接执行下一行代码,结果?
9.3异步调用的应用
from concurrent.futures import ProcessPoolExecutor,ThreadPoolExecutor import time,os,random def task(x): print('%s 接客' %x) time.sleep(random.randint(1,3)) return x**2 if __name__ == '__main__': # 异步调用 p=ThreadPoolExecutor(4) # 默认开启的线程数是cpu的核数*5 # # alex,武佩奇,杨里,吴晨芋,张三 obj_l=[] for i in range(10): obj=p.submit(task,i) obj_l.append(obj) # p.close()#不允许再放新的任务 # p.join() p.shutdown(wait=True)#不允许往里面在提交任务 上述两步合并 print(obj_l[3].result()) print('主') # 提交完任务之后,等任务结束之后再拿结果
9.4同步调用的应用
from concurrent.futures import ProcessPoolExecutor,ThreadPoolExecutor import time,os,random def task(x): print('%s 接客' %x) time.sleep(random.randint(1,3)) return x**2 if __name__ == '__main__': # 同步调用 p=ThreadPoolExecutor(4) # 默认开启的线程数是cpu的核数*5 # alex,武佩奇,杨里,吴晨芋,张三 for i in range(10): res=p.submit(task,i).result() print(res) print('主')
十.异步调用+回调机制(回调函数)
11.1爬取数据的下载解析过程及所遇到的问题
from concurrent.futures import ProcessPoolExecutor,ThreadPoolExecutor import requests import os import time import random def get(url): print('%s GET %s' %(os.getpid(),url)) response=requests.get(url) time.sleep(random.randint(1,3)) if response.status_code == 200: return response.text def pasrse(res): print('%s 解析结果为:%s' %(os.getpid(),len(res))) if __name__ == '__main__': urls=[ 'https://www.baidu.com', 'https://www.baidu.com', 'https://www.baidu.com', 'https://www.baidu.com', 'https://www.baidu.com', 'https://www.baidu.com', 'https://www.baidu.com', 'https://www.baidu.com', 'https://www.python.org', ] pool=ProcessPoolExecutor(4) objs=[] for url in urls: obj=pool.submit(get,url) objs.append(obj) pool.shutdown(wait=True) # # 问题: # # 1、任务的返回值不能得到及时的处理,必须等到所有任务都运行完毕才能统一进行处理 # # 2、解析的过程是串行执行的,如果解析一次需要花费2s,解析9次则需要花费18s for obj in objs: res=obj.result() pasrse(res)
11.2回调函数的应用
from concurrent.futures import ProcessPoolExecutor,ThreadPoolExecutor
from threading import current_thread
import requests
import os
import time
import random
def get(url):
print('%s GET %s' %(current_thread().name,url))
response=requests.get(url)
time.sleep(random.randint(1,3))
if response.status_code == 200:
# 干解析的活
return response.text
def pasrse(obj):
res=obj.result()
print('%s 解析结果为:%s' %(current_thread().name,len(res)))
if __name__ == '__main__':
urls=[
'https://www.baidu.com',
'https://www.baidu.com',
'https://www.baidu.com',
'https://www.baidu.com',
'https://www.baidu.com',
'https://www.baidu.com',
'https://www.baidu.com',
'https://www.baidu.com',
'https://www.python.org',
]
# pool=ProcessPoolExecutor(4) #进程池
pool=ThreadPoolExecutor(4) #线程池
for url in urls:
obj=pool.submit(get,url)
obj.add_done_callback(pasrse)#绑定了一个parse任务,相当于绑定了工具,做完了就触发了这函数,add_done_callback对象有结果了立马触发函数执行,get和parse完全解开耦合了
print('主线程',current_thread().name)
#这些活换成一个人来干
# 回调机制:干完自己该干下载的活,进程池里面去干解析的活,但他没执行parse,parse
# 由我调用他,但他完成了,他把这个函数返回给我由我调用,这个就叫函数的回调机制

 浙公网安备 33010602011771号
浙公网安备 33010602011771号