并发编程之多进程
一.什么是进程?
进程:正在进程的程序,称之为进程,而负责执行任务的是cpu。
二.进程与程序的区别
程序指的仅仅是一堆代码而已,而进程指的是程序运行的过程。
举例:
想象一位有一手好厨艺的计算机科学家egon正在为他的女儿元昊烘制生日蛋糕。
他有做生日蛋糕的食谱,
厨房里有所需的原料: 面粉、鸡蛋、韭菜,蒜泥等。
在这个比喻中:
做蛋糕的食谱就是程序(即用适当形式描述的算法)
计算机科学家就是处理器(cpu)
而做蛋糕的各种原料就是输入数据。
进程就是厨师阅读食谱、取来各种原料以及烘制蛋糕等一系列动作的总和。
现在假设计算机科学家egon的儿子alex哭着跑了进来,说:XXXXXXXXXXXXXX。
科学家egon想了想,处理儿子alex蛰伤的任务比给女儿元昊做蛋糕的任务更重要,于是
计算机科学家就记录下他照着食谱做到哪儿了(保存进程的当前状态),然后拿出一本急救手册,按照其中的指示处理蛰伤。这里,我们看到处理机从一个进程(做蛋糕)
切换到另一个高优先级的进程(实施医疗救治),每个进程拥有各自的程序(食谱和急救手册)。当蜜蜂蛰伤处理完之后,这位计算机科学家又回来做蛋糕,从他
离开时的那一步继续做下去。
需要强调的是:同一个程序执行两次,那也是两个进程,比如打开暴风影音,虽然都是同一个软件,但是一个可以播放苍井空,一个可以播放饭岛爱。
# 同一个程序执行多次是多个进程 import time import os print('爹是:',os.getppid()) print('me是: ',os.getpid()) time.sleep(500) # 查看进程id # tasklist |findstr python # 强制杀死进程 # taskkill /F /PID 1880
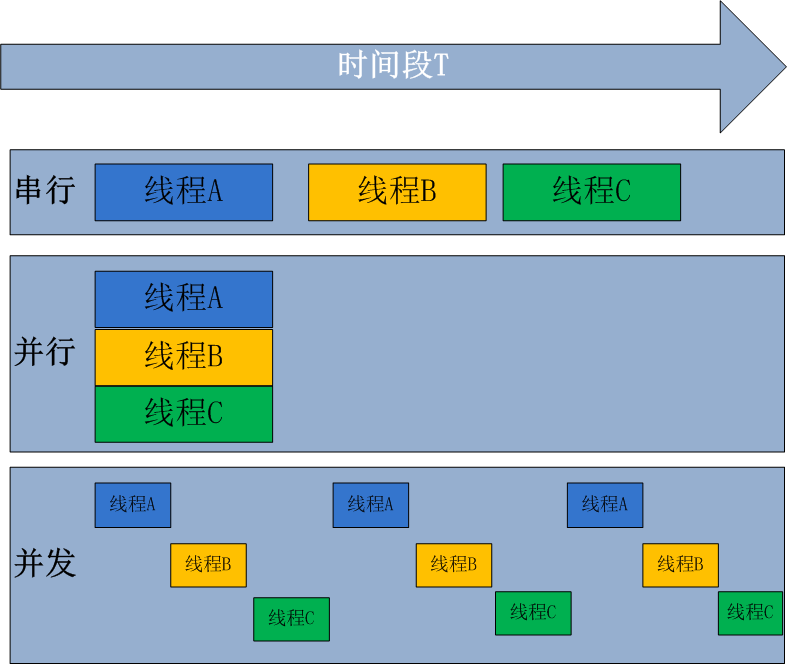
三.并发与并行
并发:即伪并行,看起来同时运行(单核加多道技术)
并行:同时运行
四.创建进程的两种方式


from multiprocessing import Process import time def task(name): print('%s is running' %name) time.sleep(3) print('%s is done' %name) if __name__ == '__main__': # 在windows系统之上,开启子进程的操作一定要放到这下面 # Process(target=task,kwargs={'name':'egon'}) 目标指向task p=Process(target=task,args=('egon',))#args传的是一个元祖,所以后面一定加逗号 p.start() # 向操作系统发送请求,操作系统会申请内存空间,然后把父进程的数据拷贝给子进程,作为子进程的初始状态 # p.start()相当于一个信号 print('======主')
第一种方式直接定义一个功能,我在开进程的时候直接调用一个类,用别人写好的类,然后用target把这个功能放到这里面去了
from multiprocessing import Process import time class MyProcess(Process): def __init__(self,name):#这里的意思是重用了父类的功能 super(MyProcess,self).__init__() self.name=name def run(self):#这里的run是固定用法,以后都这么用 print('%s is running' %self.name) time.sleep(3) print('%s is done' %self.name) if __name__ == '__main__': p=MyProcess('egon') p.start() #调的就是上面的run方法 print('主')
第二种写法继承父类,把target任务写到run里面去,用法还是一模一样,执行里面的run方法
五.进程之间内存空间相互隔离
验证进程之间,内存空间相互隔离
from multiprocessing import Process import time x=1000 def task(): time.sleep(3) global x x=0 print('儿子死啦',x) if __name__ == '__main__': print(x) p=Process(target=task) p.start() time.sleep(5) print(x)
六.父进程等待子进程
from multiprocessing import Process import time x=1000 def task(): time.sleep(3) global x x=0 print('儿子死啦',x) if __name__ == '__main__': p=Process(target=task) p.start() p.join() # 让父亲在原地等,等子进程死了 print(x)
七.进程对象的其他属性
from multiprocessing import Process import time,random x=1000 def task(n): print('%s is runing' %n) time.sleep(n) if __name__ == '__main__': start_time=time.time() p1=Process(target=task,args=(1,),name='任务1') p1.start() print(p1.pid) # print(p1.name) # p1.terminate()#操作系统发请求,需要一点时间才能干死他 # p1.join() # print(p1.is_alive()) print('主')
from multiprocessing import Process import time,random,os x=1000 def task(): print('self:%s parent:%s' %(os.getpid(),os.getppid())) time.sleep(3) if __name__ == '__main__': p1=Process(target=task,) p1.start() print(p1.pid) print('主',os.getpid())
八.僵尸进程与孤儿进程
孤儿进程:父进程已经终止了, 但是自己还在运行, 是无害的
孤儿进程会自动过继给操作系统(民政局就相当于操作系统)
僵尸进程:子进程执行完成所有任务,已经终止了,但是还残留一些信息(进程id, 进程名)
但是父进程没有去处理这些残留信息,导致残留信息占用系统内存
结论:
僵尸进程是有害的,当出现大量的僵尸进程时,会占用系统资源,可以把父进程杀掉,僵尸就成了孤儿,操作系
统会负责回收数据。
僵尸进程
from multiprocessing import Process import time,os def task(n): print('%s is running' %n) time.sleep(n) if __name__ == '__main__': p1=Process(target=task,args=(1,)) p2=Process(target=task,args=(2,)) p3=Process(target=task,args=(3,)) p1.start() p2.start() p3.start() p1.join() p2.join() p3.join() print('======主',os.getpid()) time.sleep(10000) #僵尸进程 # 保留进程pid,还有进程cpu占用的时间,还有返回状态码
import time from multiprocessing import Process def task1(): print("子进程 run") if __name__ == '__main__': for i in range(10): p = Process(target=task1) p.start() time.sleep(100000) #死了而且找不到他就是僵尸进程 # 生了10个儿子,10个儿子一生走完了,但是他爹睡着了, # 操作系统把他爹杀了,结果僵尸变孤儿,子进程本来是僵尸进程 #,然后变成孤儿进程
八.守护进程
守护进程表示 一个进程b 守护另一个进程a 当被守护的进程a结束后,那么b也跟着结束了。就像皇帝驾崩妃子殉葬。
应用场景:
之所以开启子进程 是为了帮助进程完成某个任务,然而如果主进程
认为自己的事情一旦做完就没有必要使用子进程了就可以将子进程设置为守护进程。
例如:在运行qq的过程 开启了一个进程 用于下载文件,
然而文件还没有下完 qq就退出了 下载任务也应该跟随qq 的退出而结束。
但是守护进程在手机操作系统中不一样。
import time from multiprocessing import Process def task(): print("妃子的一生") time.sleep(5) print("妃子凉了") if __name__ == '__main__': fz = Process(target=task) fz.daemon = True # 将子进程作为主进程的守护进程 要注意 必须在开启子进程之前 设置! fz.start() print("皇帝登基了") time.sleep(2) print("当了十年皇帝..") print("皇帝驾崩")
安卓守护进程的作用是保证主进程一直存活
安卓手机比较费电,为什么费电呢?因为后台很多进程在跑
因为他没有办法能够让程序和服务器一起保持连接,所以后台一直跑进程保持tcp连接
早些年安卓版的qq发消息有可能收不到 因为要手动启动qq才能收到,因为后台连接有可能断开
后来为了让安卓系统不把qq杀掉就设置了守护进程,然后发现qq被杀掉就一直拉起来
在安卓里面保持主进程一直活着
九.守护进程的应用
""" 生产者与消费者模型 吃热狗 与 做热狗 """ import time,random from multiprocessing import Process,JoinableQueue#,JoinableQueue表示可以被等的q def eat_hotdog(name,q): while True: res = q.get() # if not res: # print('吃完了...') # break print("%s吃了%s" % (name,res)) time.sleep(random.randint(1,2)) q.task_done() #记录已经被处理的数据的数量 def make_hotdog(name,q): for i in range(1,6): time.sleep(random.randint(1, 2)) print("%s生产了第%s个热狗" % (name,i)) res = "%s的%s个热狗" % (name,i) q.put(res) # q.put(None) if __name__ == '__main__': q = JoinableQueue() #生产者1 c1 = Process(target=make_hotdog,args=("万达热狗店",q)) c1.start() #生产者2 c2 = Process(target=make_hotdog, args=("老男孩热狗店", q)) c2.start() # 消费者 p2 = Process(target=eat_hotdog,args=("思聪",q)) p2.start() # 首先保证生产者全部产完成 c1.join() c2.join() # 保证队列中的数据全部被处理了 q.join() # 明确生产方已经不会再生成数据了
十.互斥锁及其应用
# 造成了进程争抢资源,整体程序会乱 from multiprocessing import Process import time,random def task1(): print('task1:名字是egon') time.sleep(random.randint(1,3)) print('task1:性别是male') time.sleep(random.randint(1,3)) print('task1:年龄是18') def task2(): print('task2:名字是alex') time.sleep(random.randint(1,3)) print('task2:性别是male') time.sleep(random.randint(1,3)) print('task2:年龄是78') def task3(): print('task3:名字是lxx') time.sleep(random.randint(1,3)) print('task3:性别是female') time.sleep(random.randint(1,3)) print('task3:年龄是30') if __name__=="__main__": p1=Process(target=task1) p2=Process(target=task2) p3=Process(target=task3) p1.start() p2.start() p3.start()
from multiprocessing import Process import time,random def task1(): print('task1:名字是egon') time.sleep(random.randint(1,3)) print('task1:性别是male') time.sleep(random.randint(1,3)) print('task1:年龄是18') def task2(): print('task2:名字是alex') time.sleep(random.randint(1,3)) print('task2:性别是male') time.sleep(random.randint(1,3)) print('task2:年龄是78') def task3(): print('task3:名字是lxx') time.sleep(random.randint(1,3)) print('task3:性别是female') time.sleep(random.randint(1,3)) print('task3:年龄是30') if __name__=="__main__": p1=Process(target=task1) p2=Process(target=task2) p3=Process(target=task3) p1.start() p1.join() p2.start() p2.join() p3.start() p3.join()
可以用join函数串行来解决但是效率太低
from multiprocessing import Process,Lock import time,random mutex=Lock() # 互斥锁: #强调:必须是lock.acquire()一次,然后 lock.release()释放一次,才能继续lock.acquire(),不能连续的lock.acquire() # 互斥锁vs join的区别一: # 大前提:二者的原理都是一样,都是将并发变成串行,从而保证有序 # 区别:join是按照人为指定的顺序执行,而互斥锁是所以进程平等地竞争,谁先抢到谁执行 def task1(lock): #这把锁都传进去,父进程不参与抢三个子进程参与抢 lock.acquire() #抢锁 print('task1:名字是egon') time.sleep(random.randint(1,3)) print('task1:性别是male') time.sleep(random.randint(1,3)) print('task1:年龄是18') lock.release()#开锁 def task2(lock): lock.acquire() print('task2:名字是alex') time.sleep(random.randint(1,3)) print('task2:性别是male') time.sleep(random.randint(1,3)) print('task2:年龄是78') lock.release() def task3(lock): lock.acquire() print('task3:名字是lxx') time.sleep(random.randint(1,3)) print('task3:性别是female') time.sleep(random.randint(1,3)) print('task3:年龄是30') lock.release() if __name__ == '__main__': p1=Process(target=task1,args=(mutex,)) p2=Process(target=task2,args=(mutex,)) p3=Process(target=task3,args=(mutex,)) p1.start() p2.start() p3.start()
互斥锁的应用
PS.json文件
{"count": 1}
import time,random,os,json from multiprocessing import Process def search(): time.sleep(random.randint(1, 3)) with open('db.json','r',encoding='utf-8') as f: dic=json.load(f) print('%s剩余票数:%s'%(os.getppid(),dic['count'])) def get(): with open('db.json','r',encoding='utf-8') as f: dic=json.load(f) if dic['count']>0: dic['count']-=1 time.sleep(random.randint(1,3)) with open('db.json','w',encoding='utf-8') as f: json.dump(dic,f) print('%s购票成功'%os.getpid()) def task(): search() get() if __name__=="__main__": for i in range(10): p=Process(target=task) p.start()
因为是共享的资源,所有人来争抢共享资源,我们需要加锁来防止争抢
串行的话查票都查不了
加锁的情况
import json import time import random import os from multiprocessing import Process,Lock mutex=Lock() # 互斥锁vs join的区别一: # 互斥锁可以让一部分代码(修改共享数据的代码)串行,而join只能将代码整体串行 def search(): time.sleep(random.randint(1,3)) with open('db.json','r',encoding='utf-8') as f: dic=json.load(f) print('%s 剩余票数:%s' %(os.getpid(),dic['count'])) def get(): with open('db.json','r',encoding='utf-8') as f: dic=json.load(f) if dic['count'] > 0: dic['count']-=1 time.sleep(random.randint(1,3)) with open('db.json','w',encoding='utf-8') as f: json.dump(dic,f) print('%s 购票成功' %os.getpid()) def task(lock): search() lock.acquire() get() lock.release() if __name__ == '__main__': for i in range(10): p=Process(target=task,args=(mutex,)) p.start() # p.join()
十一.Rlock(递归锁)与Lock的区别
RLock 表示可重入锁 特点是 可以多次执行acquire
Rlock 在执行多次acquire时 和普通Lock没有任何区别,Lock多次使用会卡死
如果在多进程中使用Rlock 并且一个进程a 执行了多次acquire
其他进程b要想获得这个锁 需要进程a 把锁解开 并且锁了几次就要解几次
普通锁如果多次执行acquire将会锁死
# RLock可重入锁 from multiprocessing import Lock,RLock,Process # lock = Lock() # # lock.acquire() # lock.acquire()#这里会阻塞 # print("haha ") # lock.release() # lock = RLock() # lock.acquire() # lock.acquire() # # print("哈哈") # lock.release() import time def task(i,lock): lock.acquire() lock.acquire() print(i) time.sleep(3) lock.release() lock.release() #第一个过来 睡一秒 第二个过来了 睡一秒 第一个打印1 第二个打印2 if __name__ == '__main__': lock = RLock() p1 = Process(target=task,args=(1,lock)) p1.start() p2 = Process(target=task, args=(2,lock)) p2.start()
十二.死锁问题
死锁 指的是 锁 无法打开了 导致程序死卡
首先要明确 一把锁 时不会锁死的
正常开发时 一把锁足够使用 不要开多把锁
第一种情况
第一位跑得快,盘子筷子都抢走了
from multiprocessing import Process,Lock import time def task1(l1,l2,i): l1.acquire() print("盘子被%s抢走了" % i) l2.acquire() print("筷子被%s抢走了" % i) print("吃饭..") l1.release() l2.release() def task2(l1,l2,i): l1.acquire() print("盘子被%s抢走了" % i) l2.acquire() print("筷子被%s抢走了" % i) print("吃饭..") l1.release() l2.release() if __name__ == '__main__': l1 = Lock() l2 = Lock() Process(target=task1,args=(l1,l2,1)).start() Process(target=task2,args=(l1,l2,2)).start()
第二种情况
睡一秒还是能吃的就是要看着别人吃
from multiprocessing import Process,Lock import time def task1(l1,l2,i): l1.acquire() print("盘子被%s抢走了" % i) time.sleep(1) l2.acquire() print("筷子被%s抢走了" % i) print("吃饭..") l1.release() l2.release() def task2(l1,l2,i): l1.acquire() print("盘子被%s抢走了" % i) l2.acquire() print("筷子被%s抢走了" % i) print("吃饭..") l1.release() l2.release() if __name__ == '__main__': l1 = Lock() l2 = Lock() Process(target=task1,args=(l1,l2,1)).start() Process(target=task2,args=(l1,l2,2)).start()
第三种情况:
第一位把盘子拿走了,结果第二位把筷子拿走了,不要把自己需要的一把锁被别人抢走
from multiprocessing import Process,Lock import time def task1(l1,l2,i): l1.acquire() print("盘子被%s抢走了" % i) time.sleep(1) l2.acquire() print("筷子被%s抢走了" % i) print("吃饭..") l1.release() l2.release() def task2(l1,l2,i): l2.acquire() print("筷子被%s抢走了" % i) l1.acquire() print("盘子被%s抢走了" % i) print("吃饭..") l1.release() l2.release() if __name__ == '__main__': l1 = Lock() l2 = Lock() Process(target=task1,args=(l1,l2,1)).start() Process(target=task2,args=(l1,l2,2)).start()
十三.进程间的通讯(IPC通讯机制)
IPC 进程间通讯
由于进程之间内存是相互独立的,所以需要对应的解决方案,能够使得进程之间相互传递数据。
方法一:使用共享文件,多个进程同时读写同一个文件,IO速度慢
特点:IO速度慢,传输数据大小不受限制(买票系统已经应用过了)。
方法二:管道 是基于内存的,速度快,但是是单向的,用起来麻烦(详见subprocess模块) (了解)
方法三:申请共享内存空间,多个进程可以共享这个内存区域.(重点)
特点:速度快但是数据量不能太大。
原理:进程向操作系统发出申请,请你为我开一个共享内存区域在里面读写
申请共享内存空间,多个进程可以共享这个内存区域(重点)
速度快但是 数据量不能太大
from multiprocessing import Manager,Process,Lock def work(d): # with lock:#不加锁而操作共享的数据,肯定会出现数据错乱 d['count']-=1 if __name__ == '__main__': with Manager() as m: dic=m.dict({'count':100}) #创建一个共享的字典 p_l=[] for i in range(100): p=Process(target=work,args=(dic,)) p_l.append(p) p.start() for p in p_l: p.join() print(dic) #结果编程0说明数据被共享了 # 死锁现象进程和线程都一样
十四.队列
队列:不止用于进程间交互,也是一种常见的数据容器
特点:先进先出
其有点是:可以保证数据不会错乱,即使在多进程下 因为其put和get默认都是阻塞的
对比堆栈刚好相反:后进先出 (函数的调用就是堆栈)
def fun1(): func2() # 函数最后调的,最先执行完 pass def fun2(): pass fun1()
from multiprocessing import Queue q = Queue(1) # 创建一个队列 最多可以存一个数据 q.put("张三") print(q.get()) q.put("李四") # put默认会阻塞 当容器中已经装满了 print(q.get()) print(q.get()) # get默认会阻塞 当容器中已经没有数据了 print("over")
from multiprocessing import Queue,SimpleQueue q = Queue(1) # 创建一个队列 最多可以存一个数据 # q.put("张三") #q.put("李四",False) # 第二个参数 设置为False表示不会阻塞 无论容器是满了 都会强行塞 如果满了就抛异常 print(q.get()) print(q.get(timeout=3))#timeout仅用于阻塞时
十五.生产者消费者模型
什么是生产者 消费者 模型 生产者 产生数据的一方 消费者 处理数据的一方 例如需要做一个爬虫 1.爬取数据 2.解析数据 爬去和解析都是耗时操作,如果正常按照顺序来编写代码,将造成解析需要等待爬去 爬去取也需要等待解析 这样效率是很低的 要提高效率 就是一个原则 让生产者和消费解开耦合 自己干自己的 如何实现: 1.将两个任务分别分配给不同进程 2.提供一个进程共享的数据容器(厨师,客户,炒菜的盘子,炒菜的盘子就是生产者消费者模型)
import random from multiprocessing import Process,Queue import time # 爬数据 def get_data(q): for num in range(5): print("正在爬取第%s个数据" % num) time.sleep(random.randint(1,2)) print("第%s个数据 爬取完成" % num) # 把数据装到队列中 q.put("第%s个数据" % num) def parse_data(q): for num in range(5): # 取出数据 data = q.get() print("正在解析%s" % data) time.sleep(random.randint(1, 2)) print("%s 解析完成" % data) if __name__ == '__main__': # 共享数据容器 q = Queue(5) #生产者进程 produce = Process(target=get_data,args=(q,)) produce.start() #消费者进程 customer = Process(target=parse_data,args=(q,)) customer.start()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号