一.知识储备
1.1计算机运行跟哪几个核心的硬件有关
cpu 运行程序
内存 临时存储数据
硬盘 永久存储数据
硬盘里面notepad++的指令读到内存,内存会专门申请一个空间,空间给notepad++这个文本编辑器来用,cpu通过来调notepad++来处理
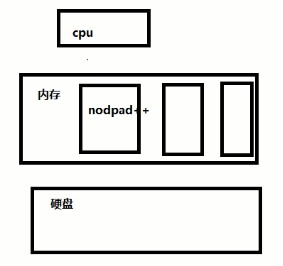
1.2文本编辑器存原理
结论:在编写py的程序的时候,是没有语法的限制的,编辑的结果跟编写一个普通的文本文件是没有任何区别,只有把py程序交给python解释并且在运行的第三个阶段才有了语言意义。
1.3.python解释器执行python程序的原理
python3 test.py
第一阶段:先启动python解释器这个软件
第二阶段:把test.py文件的内容读入内存
第三阶段:解释执行,识别语法
1.4.文本编辑器读原理
第一阶段:先启动文本编辑器
第二阶段:把文本文件的内容读入内存
第三阶段:把文件里面的内容打印到屏幕
二.字符编码
计算机读懂人类字符必须经过一个过程:
#字符--------(翻译过程)------->数字
#这个过程实际就是一个字符如何对应一个特定数字的标准,这个标准称之为字符编码
2.2什么是字符编码表?
翻译的过程必须遵循一个标准:字符与数字一一对应的关系,这个标准称之为字符编码表。
2.3字符编码的分类
ASCII
8bit=1bytes,一个英文字符占用1字节
GBK
16bit=2bytes ,2个字节表示一个中文字符,1字节表示一个英文字符
unicode(内存中固定的编码):
16bit=2bytes,2个字节表示一个字符
utf-8:Unicode Transformation Format(utf-8也称为unicode的转换版本)
1字节表示一个英文字符,3bytes表示一个中文字符
2.4保证不乱码的核心是什么?
文件是以什么编码存的,就必须以该读取
强调:我们能控制的只是存到硬盘上的编码
python3解释器:默认utf-8编码
python2解释器:默认ascii编码
文件头的作用:#coding:utf-8 是告诉python解释器,用我指定的字符编码
2.5执行python程序三个阶段发生的事
会识别python语法,定义的字符串类型又涉及到字符编码的概念
x='上' #x=str('上')
python2:
字符串分为两种形式:(str和unicode)
x='上' #python2的str类型会按照文件头指定的编码来存‘上’ (#coding:utf-8)
python3:
str:被存成了unicode
2.6字符编码发展的三个阶段
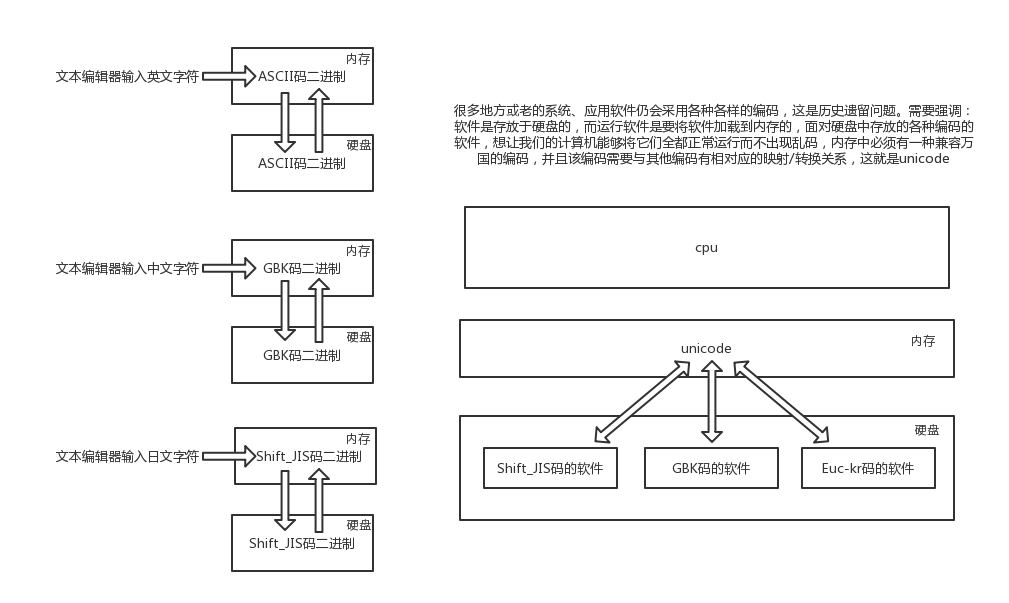
2.7转换
unicode---编码encode--->gbk
gbk------->解码decode---》unicode




 浙公网安备 33010602011771号
浙公网安备 33010602011771号