
20192401王麦齐 实验四《Python程序设计》使用爬虫爬取【网易新闻 肺炎疫情实时动态播报】页面信息实验报告
2019-2020-2 《Python程序设计》实验四报告
课程:《Python程序设计》
班级:1924
姓名:王麦齐
学号:20192401
实验教师:王志强
实验日期:2020年4月12日
必修/选修: 公选课
1.实验内容
-
1>使用爬虫爬取【网易新闻 肺炎疫情实时动态播报】页面信息。
(https://wp.m.163.com/163/page/news/virus_report/index.html?nw=1&anw=1)
![]()
-
2>将爬取的数据存储为csv格式文件。
-
3>读取csv文件,对数据进行相应的处理。
-
4>对处理后的数据进行可视化分析。
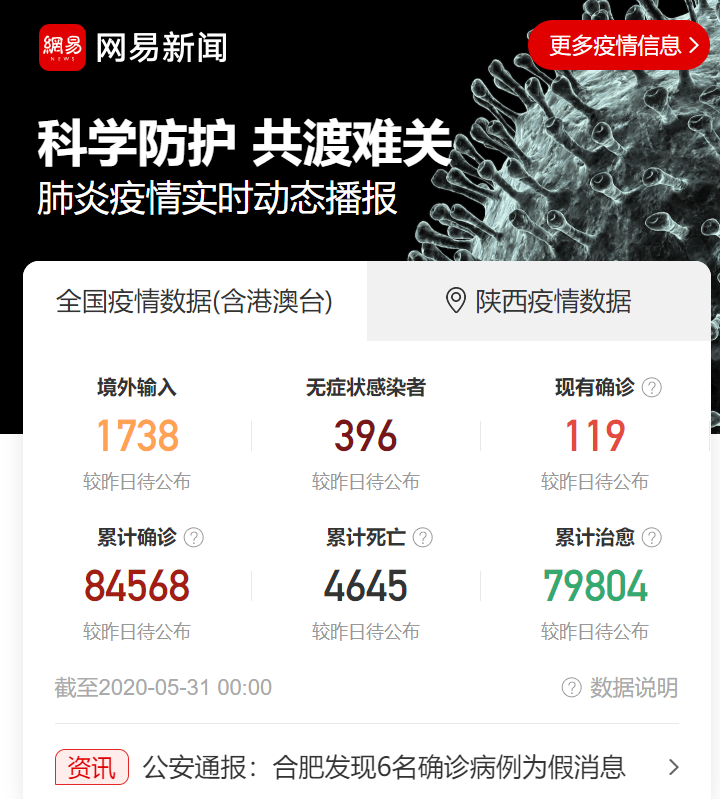
2.实验过程及结果
1>找到目标网址,伪装浏览器,请求数据
(1)通过响应network找到数据源如下:
(https://c.m.163.com/ug/api/wuhan/app/data/list-total?t=317836035959#)
(2)伪装浏览器,headers如下:
(headers = {'user-agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'})
(3)使用requests库对目标网址进行请求,打印响应码:

(4)打印响应内容:
2>使用Json模块对响应内容进行初步解析
(1)data_json = json.loads(req.text) #使用json.loads将json字符串转化为字典
(2)打印字典的key值

可以看到我们需要的是其中的data数据,再次打印data查看结果。

有点混乱,可以看到其仍然为字典,再次打印data的key值,得到关键信息。

前两个和中国有关,第3、4个和更新时间有关,最后一个不太确定是啥,打印再看看。

这次我们可以看到出现了很多国家的名字,按照猜测应该是对应网页这块:
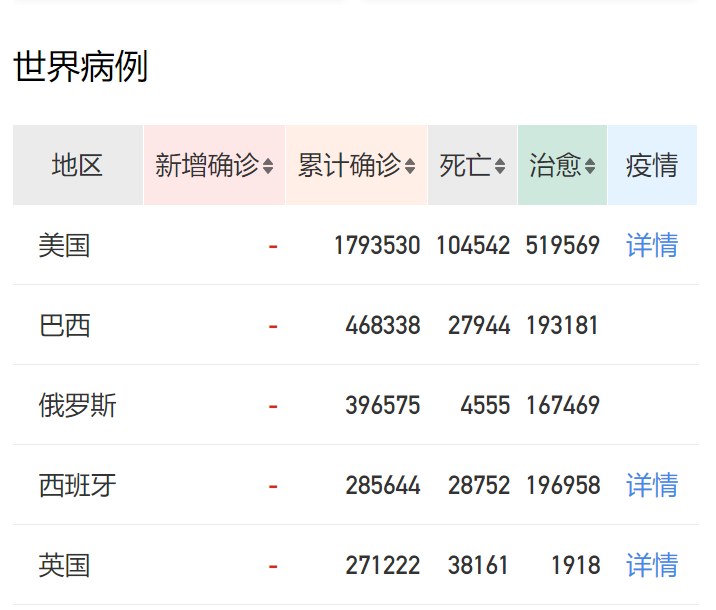
接下来我们将对这块数据进行分析处理并可视化。
(3)使用PrettyPrinter打印字典(PrettyPrinter格式化输出字典)
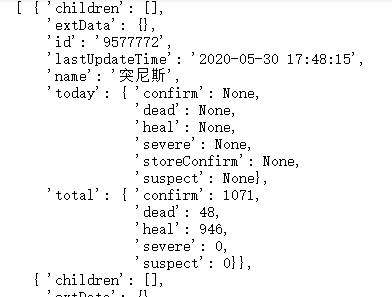
可以看到areaTree的数据格式是list,里面每一个国家对应一个字典,而字典中又嵌套着字典。
3>世界各国实时数据爬取
(1)获取areaTree数据
areaTree = data['areaTree']
(2)获取数据

today_world = get_data(areaTree,['id','lastUpdateTime','name']) #调用封装的函数获取数据
查看前5行
(3)存储数据
save_data(today_world,'today_world') #调用函数保存数据
4>数据处理
(1)更换数据列名
将英文列名换为中文列名方便我们理解数据进行处理。

使用drop()方法删除Unnamed: 0列,使用describe()方法查看对数据的描述: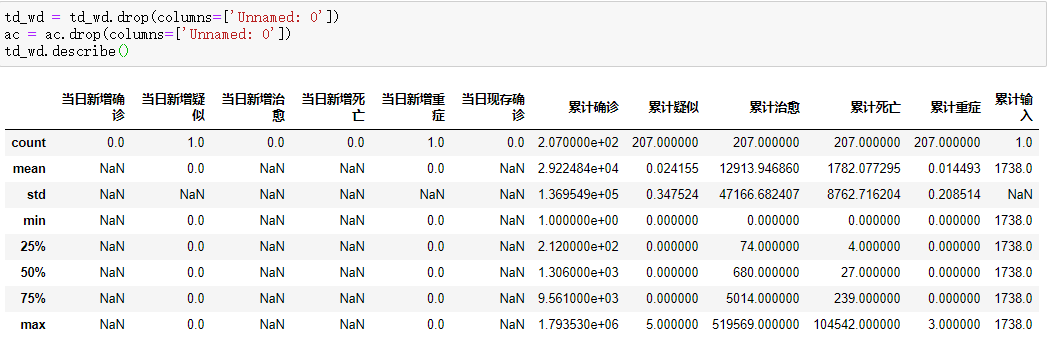
计算【当日现存确诊】公式为:累计确诊-累计治愈-累计死亡
计算【病死率】公式为:累计死亡/累计确诊
通过数据描述可以发现NaN值特别多,那么我们可以计算一下每一列NaN值占多少。
使用isnull()方法查看DataFrame数据的NaN值,并用sum()方法进行求和,除以总大小。
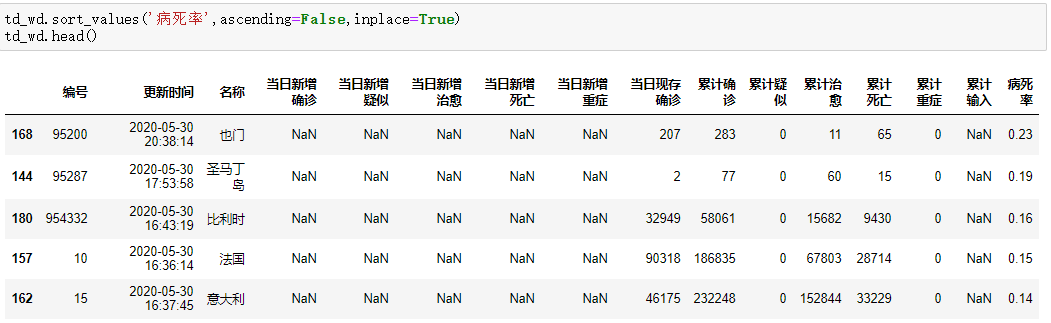
使用sort_values方法对DataFrame进行排序,排序方式以病死率,按降序方式,得到如下结果:
将索引改为国家名称:
td_wd.set_index('名称',inplace=True)
并按累计确诊进行再次排序,取出['累计确诊','累计死亡','病死率']三列前10赋给新的变量: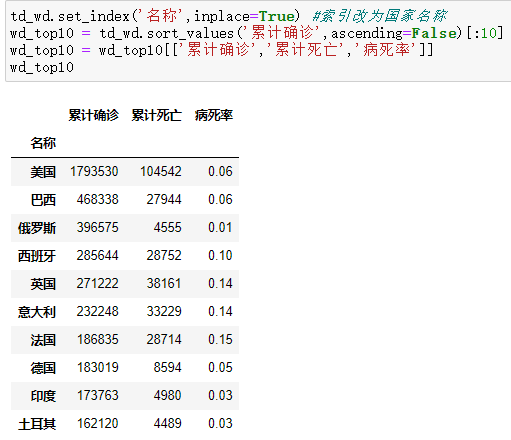
5>数据可视化
(1)从matplotlib可视化库中导入pyplot
(2)指定plt.rcParams['font.sans-serif'] = ['SimHei'] #防止中文乱码
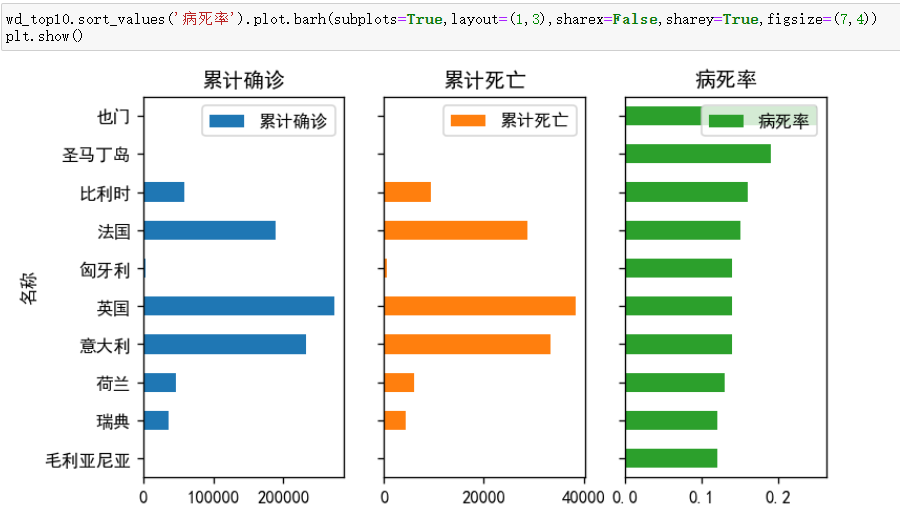
(3)按照病死率对10位数据进行排序,并将['累计确诊','累计死亡','病死率']三列分别作为每一张子图,得到可视化结果。
(4)同样的,爬取最近几月内历史数据。需要执行 2>——4>步
经过适当处理后得到如下结果: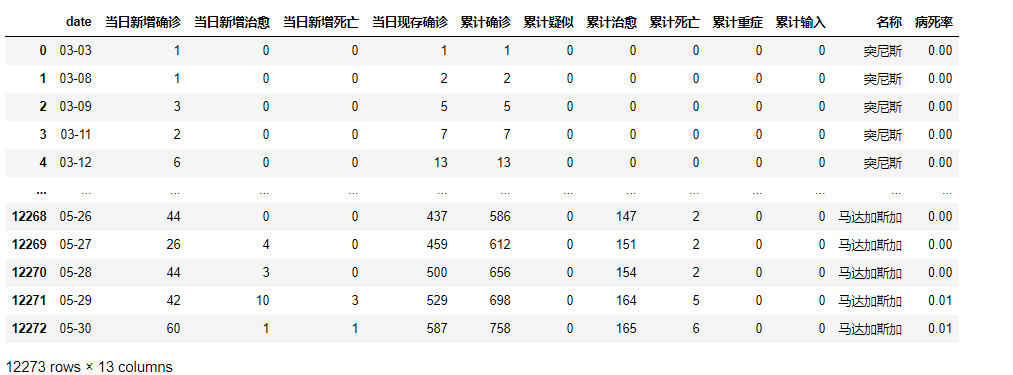
可以看到一个国家对应最近俩月不同的行,这种数据结构不易处理,再将其国家名称作为key值,存储每一天的数据。
for i in ac.index:
name = ac['名称'][i]
if name not in hisc.keys():
hisc[name] = []
hisc[name].append(list(ac.loc[i]))
else:
hisc[name].append(list(ac.loc[i]))
循环读取数据的每一行,判断当前行国家名在此字典key值是否存在,如果存在直接添加数据,不存在则创建值空列表再添加当前行数据。
查看数据以后,发现不同国家之间爬取到的数据是存在缺失值的,我们将不存在的日期去除,只保留当前所有国家存在日期的交集:
for i in cn:
d += 1
if d==1:
p_a = ds1[i]
continue
else:
p_b = ds1[i]
p_a = set(p_a) & set(p_b)
cn为国家名称(由于数据太多,表现效果不是很理想,故只取病死率前5国家作为可视化分析的依据)
(5)当日新增确诊趋势
由于横坐标轴显示问题,将其文本旋转60°,由于太过密集的原因,再将其设置为间隔显示。
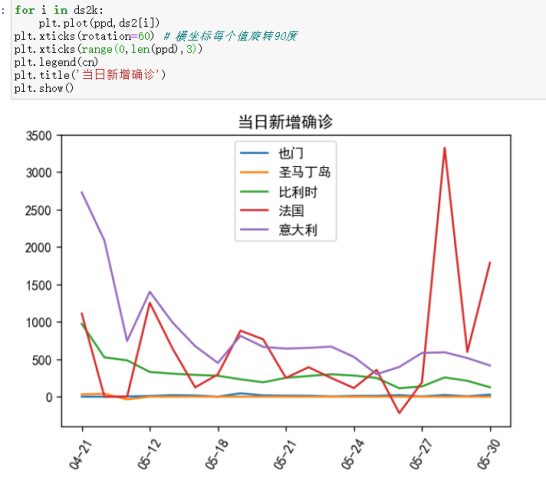
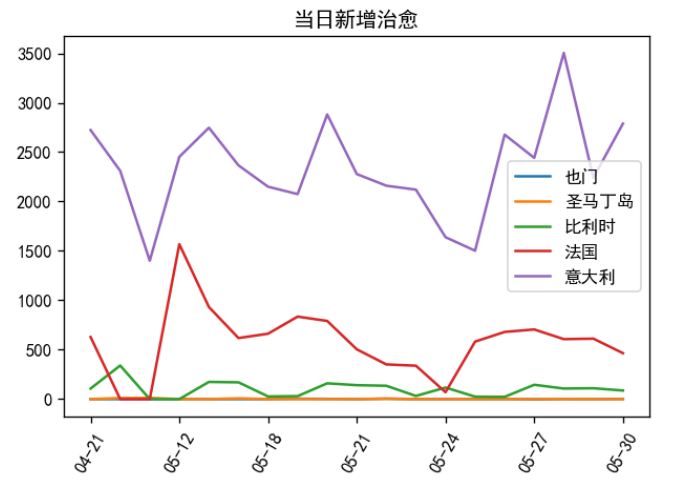
(6)当日新增确认趋势
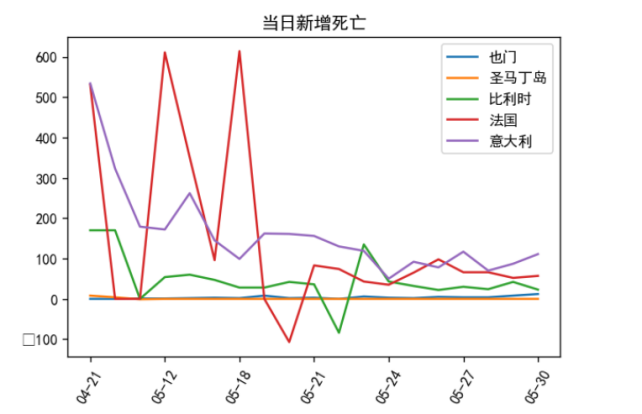
(7)当日新增死亡
(8)病死率趋势

(9)当日累计治愈
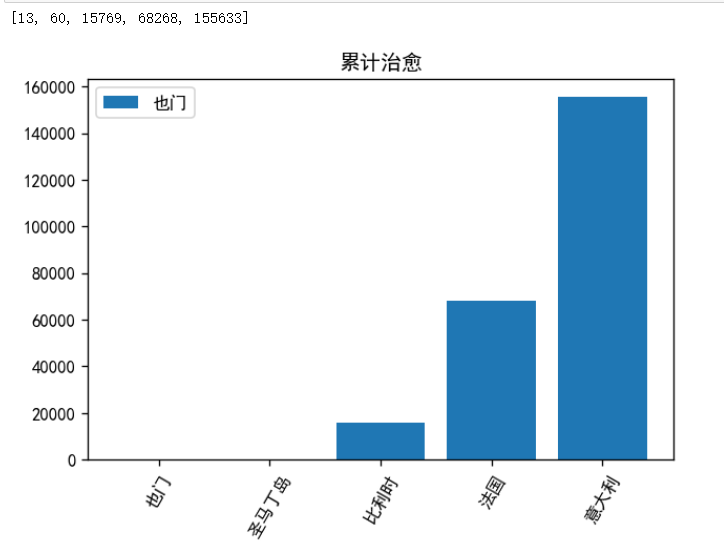
3.成果分析
从以上数据可以看到也门人口基数少,但却是病死率最高的国家。法国新增确诊波动比较大,可能是由于政策上的原因导致疫情二次扩散,同时也门有逐渐减少的趋势。意大利每天的治愈量非常大,有可能是因为人口基数的原因,同时也说明了治疗肺炎的能力也在前面。
意大利的死亡人数有减缓趋势,而法国在四月中旬波动比较大,在5月中旬趋于平缓说明法国已经在这场肺炎疫情趋势中有所好转。
从累计治愈人数来看,意大利>法国>比利时>圣马丁岛>也门
(155633>68268>15769>60>13)
3.实验过程中遇到的问题和解决过程
1>爬虫爬取数据
解决:通过network找到真实数据地址
2>数据处理
解决:DataFrame虽然好用但不是非常灵活,配合字典和列表构成新的数据格式,可以绘制出想要的可视化效果
3>数据缺失值处理
解决:对所有缺失值数据进行行删除,以此清洗后得到有效的数据。
4.结课总结:
通过课程的学习,我学习到了python如何使用,python语言的发展历史。学习到了流程控制语句:if-elif-else语句(elif else 可选)、for/while循环。学习到了序列如何应用、字符串与正则表达式如何实际去应用以及相关之间的关系。第六课学习到了函数如何编写,第7课学习了面向对象编程,万物皆为对象。第8课学习了异常处理,是为了防止错误中断程序使程序更加的健壮。第9课学习了数据库,python如何操作数据库,还学习到了一些简单的控制数据库语句。第10课学习了爬虫,对本次实验来说,实现并且应用!
5.课程感想体会:
通过本次课程学习,掌握了许多编程技巧。在不断进步的过程中,收获了许多新的知识。总之非常感谢老师的教导,而且本课程实用性也非常好,对于以后不懂编程很难混有极大的科普价值,当然也有一定的实用性!
码云链接:
[源代码]: https://gitee.com/wangmaiqi/untitled/commit/0ae33729b751df81538581eac47d892cd5a81ed3
参考资料
- [Python网络数据采集(https://www.ituring.com.cn/book/1709)]
- [Python数据分析:活用Pandas库(https://www.ituring.com.cn/book/2557)]
- [Python3 教程(https://www.w3cschool.cn/python3/)]
- [Python 基础教程(https://www.runoob.com/python/python-tutorial.html)]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号