Dream------Hadoop--网络拓扑与Hadoop--摘抄
两个节点在一个本地网络中被称为“彼此的近邻”是什么意思?在高容量数据处理中,限制因素是我们在节点间
传送数据的速率-----带宽很稀缺。这个想法便是将两个节点间的带宽作为距离的衡量标准。
衡量节点间的带宽,实际上很难实现(它需要一个稳定的集群,并且在集群中成对的节点的数量的增长要是节点数量的平方),不及Hadoop采用一个简单的方法,把网络看做一棵树,两个节点间的距离是距离他们最近的共同祖先的总和。
该树中的等级是没有被预先设定的,但是他对于相当于数据中心、框架和一直在运行的节点的等级是相同的。
这个想法是,对于以下每个场景,可用带宽依次减少(啥意思?是消耗的带宽依次增多吗?):
相同节点中的进程
同一机架上的不同节点
同一数据中心的不同机架上的节点
不同数据中心的节点(目前Hadoop上不适合跨数据中心运行)
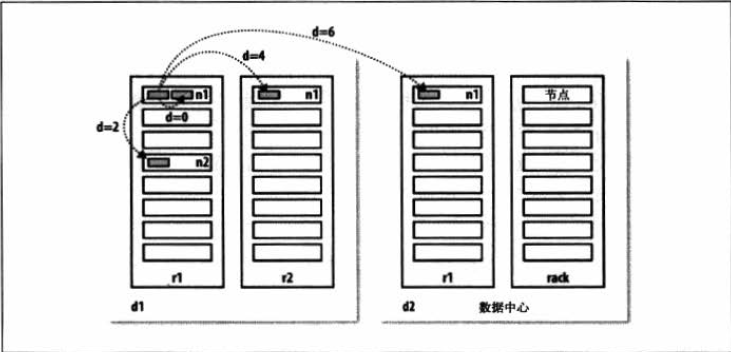
例如,假设节点n1 在数据中心d1 中的机架r1 上.这被表示成/d1/r1/n1 。
利用这种标记,这里给出四种描述的距离:
距离(/d1/r1/n1 , /d 1 /r 1 /n 1)=O(相同节点中的进程)
距离(/dl /r1 /n1 , /d 1 /r1 /n2)=2(同一机架上的不同节点)
距离(/d1/r1/n1, /d 1 /r2/n3)=4( 同一数据中心的不同机架丰的节点)
距离(/d1/r1/n1, /d2/r3/n4 }=6(不同数据中心的节点)
用图示形式表达(数学爱好者会注意到这是一个Z巨禽公制的例子) .
我们必须意识到, Hadoop 无法预测网络拓扑结构.它需要一定帮助,我
们将在第9 章讨论如何配置拓扑. 不过在默认情况下,假设网络是平的
(一个单层的等级制),或者换句话说,所有节点都在同一数据中心的同一
机架. 小的集群可能如此,所以不需要进一步的配置.
DT大数据梦工厂,微信公众号是:DT_Spark,每天都会有大数据实战视频发布,请您持续学习。
相关资料:
scala深入浅出实战经典完整视频、PPT、代码下载:
百度云盘:http://pan.baidu.com/s/1c0noOt6
腾讯微云:http://url.cn/TnGbdC
360云盘:http://yunpan.cn/cQ4c2UALDjSKy 访问密码45e2

 浙公网安备 33010602011771号
浙公网安备 33010602011771号