


一. 简介
首先来看百度百科对最小二乘法的介绍:最小二乘法(又称最小平方法)是一种数学优化技术。它通过最小化误差的平方和寻找数据的最佳函数匹配。利用最小二乘法可以简便地求得未知的数据,并使得这些求得的数据与实际数据之间误差的平方和为最小。最小二乘法还可用于曲线拟合。其他一些优化问题也可通过最小化能量或最大化熵用最小二乘法来表达。
简而言之,最小二乘法同梯度下降类似,都是一种求解无约束最优化问题的常用方法,并且也可以用于曲线拟合,来解决回归问题。最小二乘法实质就是最小化“均方误差”,而均方误差就是残差平方和的1/m(m为样本数),同时均方误差也是回归任务中最常用的性能度量。
二. 对于一元线性模型
如果以最简单的一元线性模型来解释最小二乘法。回归分析中,如果只包括一个自变量和一个因变量,且二者的关系可用一条直线近似表示,这种回归分析称为一元线性回归分析。如果回归分析中包括两个或两个以上的自变量,且因变量和自变量之间是线性关系,则称为多元线性回归分析。对于二维空间线性是一条直线;对于三维空间线性是一个平面,对于多维空间线性是一个超平面...
对于一元线性回归模型, 假设从总体中获取了m组观察值(X1,Y1),(X2,Y2), …,(Xm,Ym)。对于平面中的这m个点,可以使用无数条曲线来拟合。要求样本回归函数尽可能好地拟合这组值。综合起来看,这条直线处于样本数据的中心位置最合理。 选择最佳拟合曲线的标准可以确定为:使总的拟合误差(即总残差)达到最小。有以下三个标准可以选择:
(1)用“残差和最小”确定直线位置是一个途径。但可能会出现计算“残差和”存在相互抵消的问题。
(2)用“残差绝对值和最小”确定直线位置也是一个途径。但绝对值的计算比较麻烦。
(3)最小二乘法的原则是以“残差平方和最小”确定直线位置。用最小二乘法除了计算比较方便外,得到的估计量还具有优良特性。这种方法对异常值非常敏感。
最常用的是普通最小二乘法( Ordinary Least Square,OLS):所选择的回归模型应该使所有观察值的残差平方和达到最小。
在讲最小二乘的详情之前,首先明确两点:1.我们假设在测量系统中不存在有系统误差,只存在有纯偶然误差。比如体重计或者身高计本身有问题,测量出来的数据都偏大或者都偏小,这种误差是绝对不存在的。(或者说这不能叫误差,这叫错误)2.误差是符合正态分布的,因此最后误差的均值为0(这一点很重要) 。
明确了上面两点以后,重点来了:为了计算β0,β1的值,我们采取如下规则:β0,β1应该使计算出来的函数曲线与观察值的差的平方和最小。用数学公式描述就是:
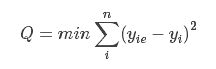
其中,yie表示根据y=β0+β1x估算出来的值,yi是观察得到的真实值。
为什么要用残差的平方和最小?用差的绝对值不行么?
以下是一个相对靠谱的解释:
我们假设直线对于坐标 Xi 给出的预测 f(Xi) 是最靠谱的预测,所有纵坐标偏离 f(Xi) 的那些数据点都含有噪音,是噪音使得它们偏离了完美的一条直线,一个合理的假设就是偏离路线越远的概率越小,具体小多少,可以用一个正态分布曲线来模拟,这个分布曲线以直线对 Xi 给出的预测 f(Xi) 为中心,实际纵坐标为 Yi 的点 (Xi, Yi) 发生的概率就正比于 EXP[-(ΔYi)^2]。(EXP(..) 代表以常数 e 为底的多少次方)。
所以我们在前面的两点里提到,假设误差的分布要为一个正态分布,原因就在这里了。
另外说一点我自己的理解:从数学处理的角度来说,绝对值的数学处理过程,比平方和的处理要复杂很多。搞过机器学习的同学都知道,L1正则就是绝对值的方式,而L2正则是平方和的形式。L1能产生稀疏的特征,这对大规模的机器学习灰常灰常重要。但是L1的求解过程,实在是太过蛋疼。所以即使L1能产生稀疏特征,不到万不得已,我们也还是宁可用L2正则,因为L2正则计算起来方便得多。。。
明确了前面的cost function以后,后面的优化求解过程反倒变得s容易了。
样本的回归模型很容易得出:

现在需要确定β0、β1,使cost function最小。学过高数的同志们都清楚,求导就OK。对于这种形式的函数求导,根据数学知识我们知道,函数的极值点为偏导为0的点。
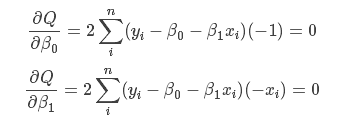
将这两个方程稍微整理一下,使用克莱姆法则,很容易求解得出:

这就是最小二乘法的解法,就是求得平方损失函数的极值点。需要注意的一点是β0是常数项对应的系数,此处相当于添加了一个特征值x0且x0恒为1,也就是目标函数中的β0可以看成β0x0,这样的话就不同单独考虑常数项了(在后面的多元线性模型就用到了该性质)。
三. 对于多元线性模型
如果我们推广到更一般的情况,假如有更多的模型变量x1,x2,⋯,xn,可以用线性函数表示如下:
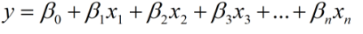
对于m个样本来说,可以用如下线性方程组表示:
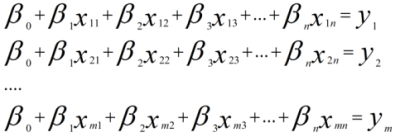
如果将样本矩阵xij记为矩阵A,将参数矩阵记为向量β,真实值记为向量Y,上述线性方程组可以表示为:
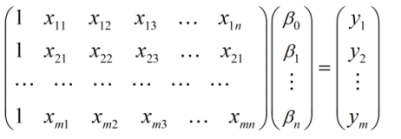
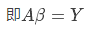
对于最小二乘来说,最终的矩阵表达形式可以表示为:
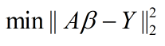
![]()
其中m≥n,由于考虑到了常数项,故属性值个数由n变为n+1。
关于这个方程的解法,具体如下:
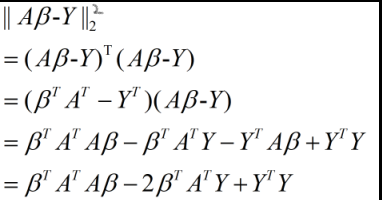
其中倒数第二行中的中间两项为标量,所以二者相等。然后利用该式对向量β求导:
 (1)
(1)
由矩阵的求导法则:

可知(1)式的结果为:
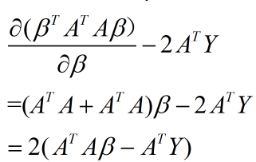
令上式结果等于0可得:
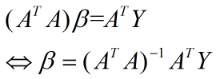 (2)
(2)
上式就是最小二乘法的解析解,它是一个全局最优解。
四. 其他一些想法
1. 最小二乘法和梯度下降
乍一看看β的最终结果,感觉很面熟,仔细一看,这不就是NG的ML课程中所讲到的正规方程嘛!实际上,NG所说的的正规方程的解法就是最小二乘法求解析解的解法。
(1)最小二乘法和梯度下降法在线性回归问题中的目标函数是一样的(或者说本质相同),都是通过最小化均方误差来构建拟合曲线。
(2)二者的不同点可见下图(正规方程就是最小二乘法):
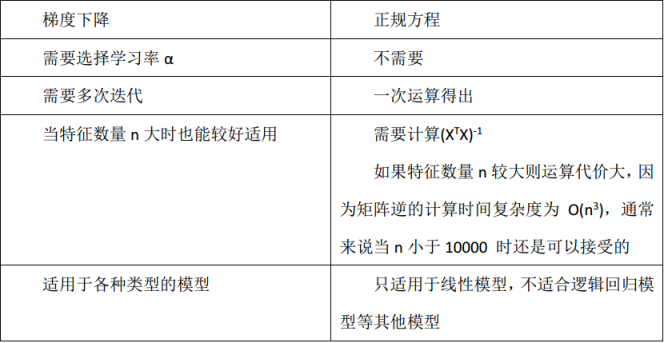
需要注意的一点是最小二乘法只适用于线性模型(这里一般指线性回归);而梯度下降适用性极强,一般而言,只要是凸函数,都可以通过梯度下降法得到全局最优值(对于非凸函数,能够得到局部最优解)。
梯度下降法只要保证目标函数存在一阶连续偏导,就可以使用。
2.最小二乘法的一些限制和解决方法:
我们由第三部分(2)式可知道,要保证最小二乘法有解,就得保证ATA是一个可逆阵(非奇异矩阵);那如果ATA不可逆怎么办?什么情况下ATA不可逆?
关于ATA在什么情况下不可逆:
(1)当样本的数量小于参数向量(即β)的维度时,此时ATA一定是不可逆的。例如:你有1000个特征,但你的样本数目小于1000的话,那么构造出的ATA就是不可逆的。
(2)在所有特征中若存在一个特征与另一个特征线性相关或一个特征与若干个特征线性相关时,此时ATA也是不可逆的。为什么呢?
具体来说假设,A是m*n维的矩阵,若存在线性相关的特征,则R(A)<n,R(AT)<n,R(ATA)<n,所以ATA不可逆。
如果ATA不可逆,应该怎样解决?
(1)筛选出线性无关的特征,不保留相同的特征,保证不存在线性相关的特征。
(2)增加样本量。
(3)采用正则化的方法。对于正则化的方法,常见的是L1正则项和L2正则项,L1项有助于从很多特征中筛选出重要的特征,而使得不重要的特征为0(所以L1正则项是个不错的特征选择方法);如果采用L2正则项的话,实际上解析解就变成了如下的形式:
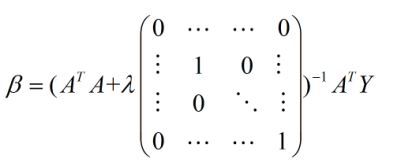
λ即正则参数(是一种超参数)后面的矩阵为(n+1)*(n+1)维,如果不考虑常数项的话,就是一个单位阵;此时括号中的矩阵一定是可逆的。
3.最小二乘法的改进
最小二乘法由于是最小化均方差,所以它考虑了每个样本的贡献,也就是每个样本具有相同的权重;由于它采用距离作为度量,使得他对噪声比较敏感(最小二乘法假设噪声服从高斯分布),即使得他它对异常点比较敏感。因此,人们提出了加权最小二乘法,
相当于给每个样本设置了一个权重,以此来反应样本的重要程度或者对解的影响程度。
参考:NG《机器学习》
《矩阵分析与应用》
http://www.cnblogs.com/iamccme/archive/2013/05/15/3080737.html
http://blog.csdn.net/bitcarmanlee/article/details/51589143

 浙公网安备 33010602011771号
浙公网安备 33010602011771号