本篇内容基于西瓜书与邹博视频总结而成
第一部分:有关信息论以及熵的构造
主要知识点:
我的理解:熵等价于不确定度
熵的构造:
- 基本想法:当一个不可能发生的事情发生了,包含的信息的不确定性大
太阳东升西落:这件事情不携带任何不确定性,而地震发生的不确定性还是有的,我们的目标就是找到事情发生的不确定性,并且使它发生的概率最小。
- 构造:首先希望满足概率可加性:加对数 (经典底为2,不过底数对于模型极值无意义) ,其次:概率越小\(\Rightarrow\) 不确定信息越多\(\Rightarrow\) 添负号
即:\(p\) 【事件发生的概率)】 | 度量:\(-ln(p)\)
熵:所有随机事件不确定度的综合,即求事件的期望
\[\sum_{i=1}^N p(i)\cdot lnp(i)
\]
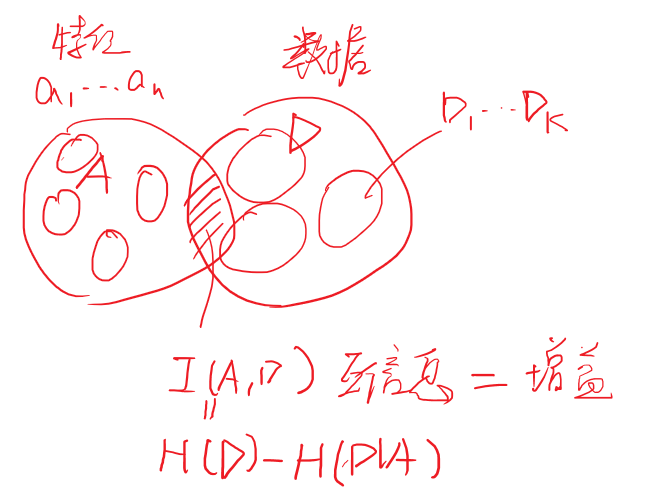
条件熵 H(Y|X)
条件熵的定义是:是在X已经发生的情况后,Y发生“新”的不确定度(熵)
根据上述定义可有:\(H(X,Y)-H(X)\)
【X,Y所有包含的不确定度 】 减去 【X所含的不确定度 】 等于 【在X的基础上的额外的不确定度】
如果画出文氏图就能更好的理解:
推导:
\[\begin{aligned}
H(X, Y)-H(X)={} &-\sum_{x, y} p(x, y) \log p(x, y)+\sum_{x} p(x) \log p(x)\\
={} & -\sum_{x, y} p(x, y) \log p(x, y)+\sum_{x}\left(\sum_{y} p(x, y)\right) \log p(x)\\
={} & -\sum_{x, y} p(x, y) \log p(x, y)+\sum_{x, y} p(x, y) \log p(x) \\
={} & -\sum_{x, y} p(x, y) \log \frac{p(x, y)}{p(x)} \\
={} & -\sum_{x, y} p(x, y) \log p(y | x)
\end{aligned}
\]
可以发现上面最后这个式子不是很友好,前面是联合概率,后面是条件概率,将上面的联合概率变为条件概率看你那个得到什么结果?
\[\begin{aligned}
H(X, Y)-H(X)={}& -\sum_{x, y} p(x, y) \log p(y | x) \\
={} & -\sum_{x} \sum_{y} p(x, y) \log p(y | x) \\
={} & -\sum_{x} \sum_{y} p(x, y) \log p(y | x) \\
={} & -\sum_{x} p(x) p(y | x) \log p(y | x) \\
={} & \sum_{x} p(x)\left(-\sum_{y} p(y | x) \log p(y | x)\right) \\
={} &\sum_{x} p(x) H(Y | X=x)
\end{aligned}
\]
上述公式其实很好理解,我们代入决策树的思考环境去思考这个问题。加入新的信息量是有两个。一是真实类别信息,二是\(A=(a_1,a_2,\dots,a_V)\) ,熵的英文为:\(information \ entropy\) ,\(D\) 代表数据集,根据标签\(target\)可将\(D\)分为\(K\)类。根据特征\(A\),可将\(D\)分为\(V\)类。
始终记住:熵的公式是根据真实类别计算的“纯度或不确定度”
\[Ent(D)=-\sum_{k=1}^{K}p_kln(p_k)
\]
信息增益:加入特征前后的熵的便函
根据定义:\(Ent(D)-Ent(D|A)\)
\[\begin{aligned}
Ent(D)-Ent(D|A) ={} & Ent(D)-\sum_{v=1}^V\frac{|D^v|}{|D|}Ent(D^v) \\
\end{aligned}
\]
这个等号在概念上很好理解,我们根据加入A后计算各个子节点的熵,因为每个子节点划分后样本数量不相同,所以要对这些熵进行加权处理。但是数学上又需要一个解释。
\[\begin{aligned}
Ent(D|A) ={} &-\sum_{v, k} p\left(D_{v}, A_{i}\right) \log p\left(D_{v} | A_{i}\right) \\
={} & -\sum_{v, k} p\left(A_{v}\right) p\left(D_{k} | A_{v}\right) \log p\left(D_{k} | A_{v}\right)\\
={} & -\sum_{v=1}^{V} \sum_{k=1}^{K} p\left(A_{v}\right) p\left(D_{k} | A_{v}\right) \log p\left(D_{k} | A_{v}\right)\\
={} & -\sum_{v=1}^{V} \frac{\left|D_{v}\right|}{|D |} \sum_{k=1}^{K} \frac{\left|D_{v k}\right|}{\left|D_{v}\right|} \log \frac{\left|D_{v k}\right|}{\left|D_{v}\right|} =-\sum_{v=1}^V\frac{|D^v|}{|D|}Ent(D^v)
\end{aligned}
\]
这里的公式比较复杂,在西瓜书中\(D^v\) 说明一开这个数据集是由特征\(A\) 进行划分,但是这又是熵的计算,熵是根据样本分类\(K\)计算的不确定度。所以这里数据集\(D_{vk}\) 是先对\(A\)进行划分,之后再在\(D_V\)的基础上对分类\(K\)进行划分。
第二部分 决策树生成策略
决策树采用的是自顶而下的递归方法,其基本思想是以信息熵为度量,选择熵值下降最快【信息增益最大】的属性作为第一个结点,之后的特征依次以此为标准生成决策树。终止条件:到叶子结点处的熵值为0,此时每个叶节点中的实例属于同一类。
如下图分析:

之前我们以信息熵作为度量,以信息增益作维选择特征的决策依据,其实还有其他的依据:
常用三种算法:
- ID3:信息增益(已学)
- C4.5:信息增益率(本节内容)
- CART:Gini系数(本节内容)
信息增益率
信息增益有个缺点。假设西瓜分为两类,好瓜和坏瓜。50个样本,其中一特征有100个属性。若用此属性作为划分依据,划分后每个类别的熵都为0【因为每个类别的瓜都可以被分到一节点,还记得怎么计算增益率吗?是先用V进行划分,再用K进行划分。这里V划分结束后,K已经不用划分了,因为只可能是一种类别】
属性\(a\)的固有值:
\[\mathrm{IV}(a)=-\sum_{v=1}^{V} \frac{\left|D^{v}\right|}{|D|} \log _{2} \frac{\left|D^{v}\right|}{|D|}
\]
\(a\)越大\(\Rightarrow\) \(D^v\) 越均匀 \(\Rightarrow\) 熵值越大
信息增益率:
\[\text { Gain ratio }(D, a)=\frac{\operatorname{Gain}(D, a)}{\operatorname{IV}(a)}
\]
基尼系数 Gini
基尼数据定义:随机抽取两个样本,类别不一样的概率。
\[\begin{aligned} \operatorname{Gini}(D) &=\sum_{k=1}^{| \mathcal{Y |}} \sum_{k^{\prime} \neq k} p_{k} p_{k^{\prime}} \\ &=1-\sum_{k=1}^{|\mathcal{Y}|} p_{k}^{2} \end{aligned}
\]
基尼指数【对照于增益】:
\[\text { Gini } \operatorname{index}(D, a)=\sum_{v=1}^{V} \frac{\left|D^{v}\right|}{|D|} \operatorname{Gini}\left(D^{v}\right)
\]
最优划分属性:
\[a_{*}=\underset{a \in A}{\arg \min } \operatorname{Gini} \operatorname{index}(D, a)
\]
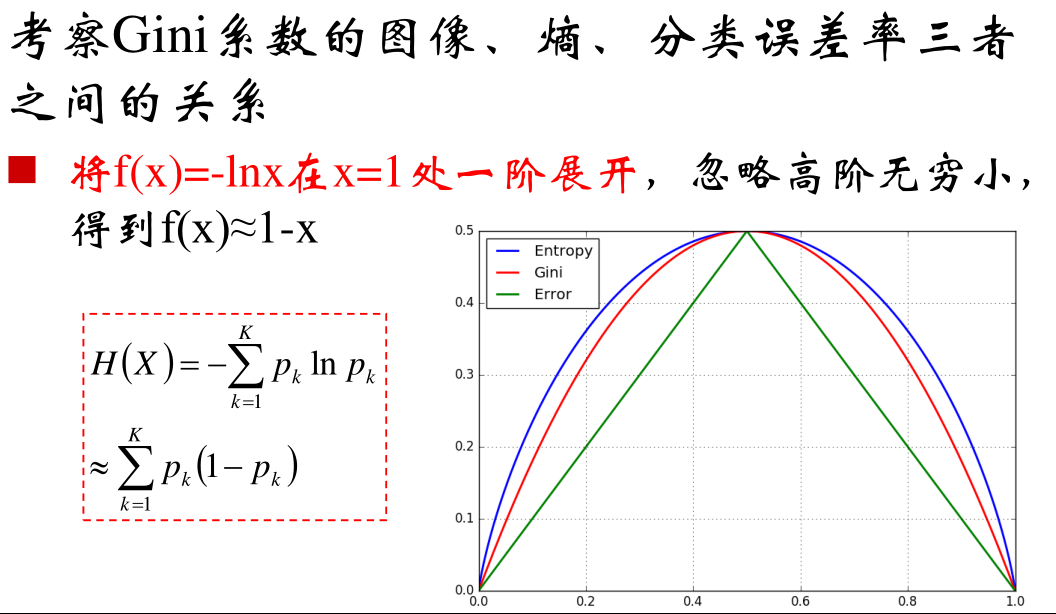
高阶认识:Gini系数就是信息熵的一阶泰勒近似
第三部分 算法调参
过拟合处理:
-
剪枝
-
随机深林
剪枝
西瓜书和邹博讲的剪枝手段不一样啊。
⭕【邹博思路】:
-
决策树的评价
纯结点的熵为:\(H_p=0\) ,最小
均结点的熵为:\(H_u=lnk\) ,最大
对所有叶节点的熵进行求和,值越小,说明样本的分类越精细。
考虑到每个结点的样本数目是不一样的,所以评价函数采用样本加权求熵和
评价函数:
\[C(T)=\sum_{t \in l e a f} N_{t} \cdot H(t)
\]
将此作为损失函数。
-
正则化考虑:以叶子的数目作为复杂度
损失函数:
\[C_{\alpha}=C(T)+\alpha|T_{leaf}|
\]
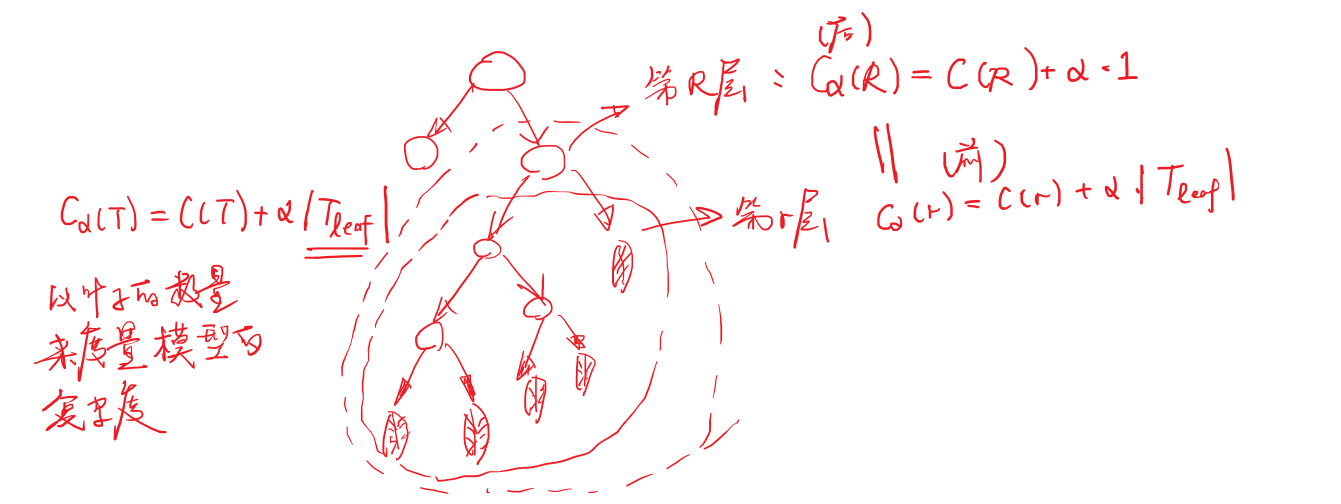
目标:求在保证损失不变的情况下,模型的复杂度是多少?(剪枝系数)
\[\alpha = \frac{C(r)-C(R)}{<R_{leaf}>-1}
\]
⭐剪枝算法:
- 对于给定的决策树T:
- 计算所有内部节点的剪枝系数;
- 查找最小剪枝系数的结点,剪枝得决策树\(T_k\);
- 重复以上步骤,直到决策树\(T\),只有1个结点;
- 得到决策树序到 \(T_0T_1T_2 \dots T_k\);
- 使用验证样本集选择最优子树。
注:当用验证集做最优子树的标准,直接用之前不带正则项的评价函数:\(C(T)=\sum_{t \in l e a f} N_{t} \cdot H(t)\)
⭕【西瓜书】
西瓜书的剪枝手段主要是通过验证集去选择,并且把剪枝分为预剪枝和后剪枝
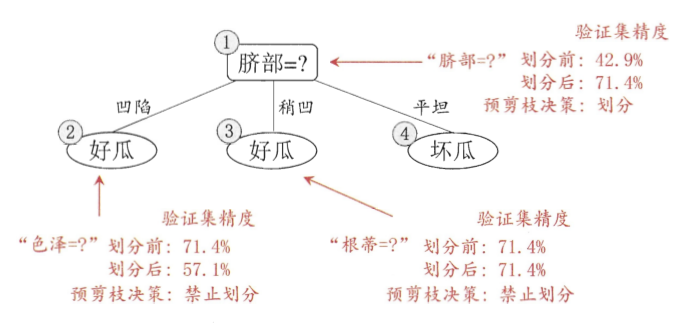

注:预剪枝基于的是贪心算法,只要验证集精度提高了,我就剪枝,所以有欠拟合的风险。而后剪枝是自底向上对所有非叶结点进行逐一考察,时间开销大的多,但是泛化能力提高。
连续值和缺失值处理
⭕连续值处理:
给定样本集\(D\)和连续属性\(a\),假定\(a\)在\(D\)上出现了\(n\)个不同的取值,将这些值从小到大进行排序,记为\(\{a_l,a_2..,a_n\}\).基于划分点\(t\)可将\(D\)分为子集\(D_t^-\)和\(D_t^+\),其中\(D_t^-\)包含那些在属性\(a\)上取值不大于\(t\)的样本,而\(D\)则包含那些在属性\(a\)上取值大于\(t\)的样本。我们可考察包含 \(n-1\) 个元素的候选划分点集合:
\[T_{a}=\left\{\frac{a^{i}+a^{i+1}}{2} | 1 \leqslant i \leqslant n-1\right\}
\]
缕一缕:一个结点有\(n-1\)个候选划分点:
综上公式改为:
\[\begin{aligned} \operatorname{Gain}(D, a) &=\max _{t \in T_{a}} \operatorname{Gain}(D, a, t) \\ &=\max _{t \in T_{a}} \operatorname{Ent}(D)-\sum_{\lambda \in\{-,+\}} \frac{\left|D_{t}^{\lambda}\right|}{|D|} \operatorname{Ent}\left(D_{t}^{\lambda}\right) \end{aligned}
\]
⭕缺省值:
我们需解决两个问题:(1)如何在属性值缺失的情况下进行划分属性选择?(2)给定划分属性,若样本在该属性上的值缺失,如何对样本进行划分?
无缺失值样本所占的比例:
\[\rho=\frac{\sum_{\boldsymbol{x} \in \tilde{D}} w_{\boldsymbol{x}}}{\sum_{\boldsymbol{x} \in D} w_{\boldsymbol{x}}}
\]
无样本下第k类的比例和第v个属性的比例:【与之前的公式相同】
\[\begin{aligned} \tilde{p}_{k} &=\frac{\sum_{\boldsymbol{x} \in \tilde{D}_{k}} w_{\boldsymbol{x}}}{\sum_{\boldsymbol{x} \in \tilde{D}} w_{\boldsymbol{x}}} \quad(1 \leqslant k \leqslant|\mathcal{Y}|) \\ \tilde{r}_{v} &=\frac{\sum_{\boldsymbol{x} \in \tilde{D}^{v}} w_{\boldsymbol{x}}}{\sum_{\boldsymbol{x} \in \tilde{D}} w_{\boldsymbol{x}}} \quad(1 \leqslant v \leqslant V) \end{aligned}
\]
\(w_x\)是每个样本\(x\)的权重,根结点中的样本权重为1。
增益公式推广为:
\[\begin{aligned} \operatorname{Gain}(D, a) &=\rho \times \operatorname{Gain}(\tilde{D}, a) \\ &=\rho \times\left(\operatorname{Ent}(\tilde{D})-\sum_{v=1}^{V} \tilde{r}_{v} \operatorname{Ent}\left(\tilde{D}^{v}\right)\right) \end{aligned}
\]
多变量决策树
⭕同一个特征可以进行多次判别:

⭕一般而言,分类边界为:轴平行(axis-parallel),但是也可以将线性分类器作为决策标准,可以产生"斜"这的分类边界。

技巧:可利用斜着的分裂边界简化决策树模型

 浙公网安备 33010602011771号
浙公网安备 33010602011771号