mysql慢查询分析思路
准备实验环境
CREATE TABLE t1 (f1 INT NOT NULL,f2 INT NOT NULL,PRIMARY KEY(f1,f2));
INSERT INTO t1 VALUES
(1,1), (1,2), (1,3), (1,4), (1,5),
(2,1), (2,2), (2,3), (2,4), (2,5);
INSERT INTO t1 SELECT f1,f2 + 5 FROM t1;
INSERT INTO t1 SELECT f1,f2 + 10 FROM t1;
INSERT INTO t1 SELECT f1,f2 + 20 FROM t1;
INSERT INTO t1 SELECT f1,f2 + 40 FROM t1;

explain analyze select f1,f2 from t1 where f2>40;
explain analyze 是正是执行,在生产只可用于select查询语句,尽量在只读库中执行

 (读的顺序是深度优先)
(读的顺序是深度优先)
两张图中可以看出rows analyze是真实执行的行数,explain中的rows不准确
详细信息可以
set optimizer_trace=1;
explain analyze select f1,f2 from t1 where f1>0 and f2>40;
select * from information_schema.optimizer_trace;

explain analyze select f1,f2 from t1 where f2>40;
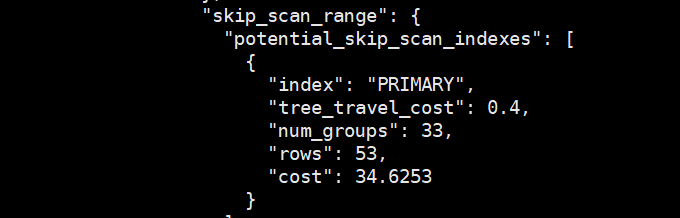
可以看到加上f1>0这个条件由于前缀不是等值所以没有用到index skip scan,导致rows真实扫描了160行

 浙公网安备 33010602011771号
浙公网安备 33010602011771号