YOLOv4 win10 配置 + 训练自己的数据 + 测试
配置
YOLOv4是最近开源的一个又快又准确的目标检测器。
首先看一下Github上的版本要求及下载地址:
系统:Windows or Linux
CMake >= 3.12: https://cmake.org/download/
CUDA 10.0: https://developer.nvidia.com/cuda-toolkit-archive
OpenCV >= 2.4: 直接从Opencv官网下载就好
cuDNN >= 7.0 for CUDA 10.0: https://developer.nvidia.com/rdp/cudnn-archive
Visual Studio 2015/2017/2019: https://visualstudio.microsoft.com/thank-you-downloading-visual-studio/?sku=Community
YOLO v4源码
YOLOv4仓库github地址: https://github.com/AlexeyAB/darknet.
为了防止下载压缩包解压后会丢失一些文件,建议在码云上clone下来。
CMake安装
进入官网下载最新的版本即可,图中红色标注的位置,下载后一路默认安装点下来就好。

CUDA安装
CUDA是我当初安装tensorflow2.0时安的
主要是从官网上下载安装文件,
解压缩,如图:

同意并继续,选择精简,进入安装,大概要几分钟的时间。
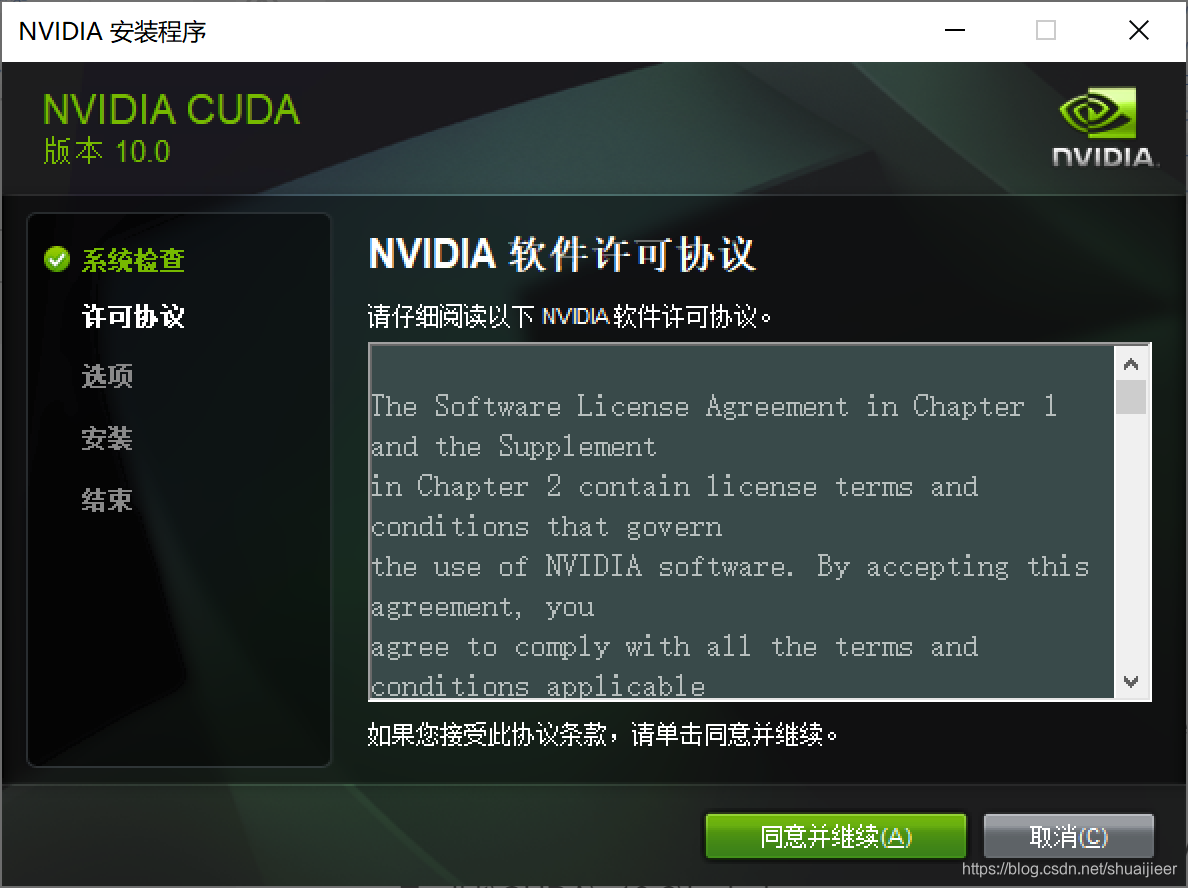
安装完成后检查是否安装成功。
win+R 进入运行界面,输入cmd进入命令行界面,输入nvcc --version 查看是否安装成功

cuDNN安装
在官网下载前需要注册NVIDIA DEVELPOER 的账号,选择与CUDA10.0对应的版本cuDNN7.6.4,点击library for win10文件,大概有240M左右。如下图所示:

官网的安装教程:https://docs.nvidia.com/deeplearning/sdk/cudnn-install/index.html#installwindows
其实就是将解压后将下面几个文件复制到CUDA的对应路径下。
- Copy ...\cuda\bin\cudnn64_7.6.5.32.dll to C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.2\bin.
- Copy ...\cuda\ include\cudnn.h to C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.2\include.
- Copy ...\cuda\lib\x64\cudnn.lib to C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.2\lib\x64.
简便快捷的方法就是把下载好的CUDNN文件 全部复制到C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.2中
OpenCV安装
从官网下载,版本要大于2.4
下载好直接解压就可以,并将installpath\opencv\build\路径添加到系统的环境变量中,
CMake编译的时候会自动找到这个文件夹
添加环境变量如下图所示,在此电脑右击属性,弹出下图界面,点击高级系统设置。
点击环境变量,新建环境变量,
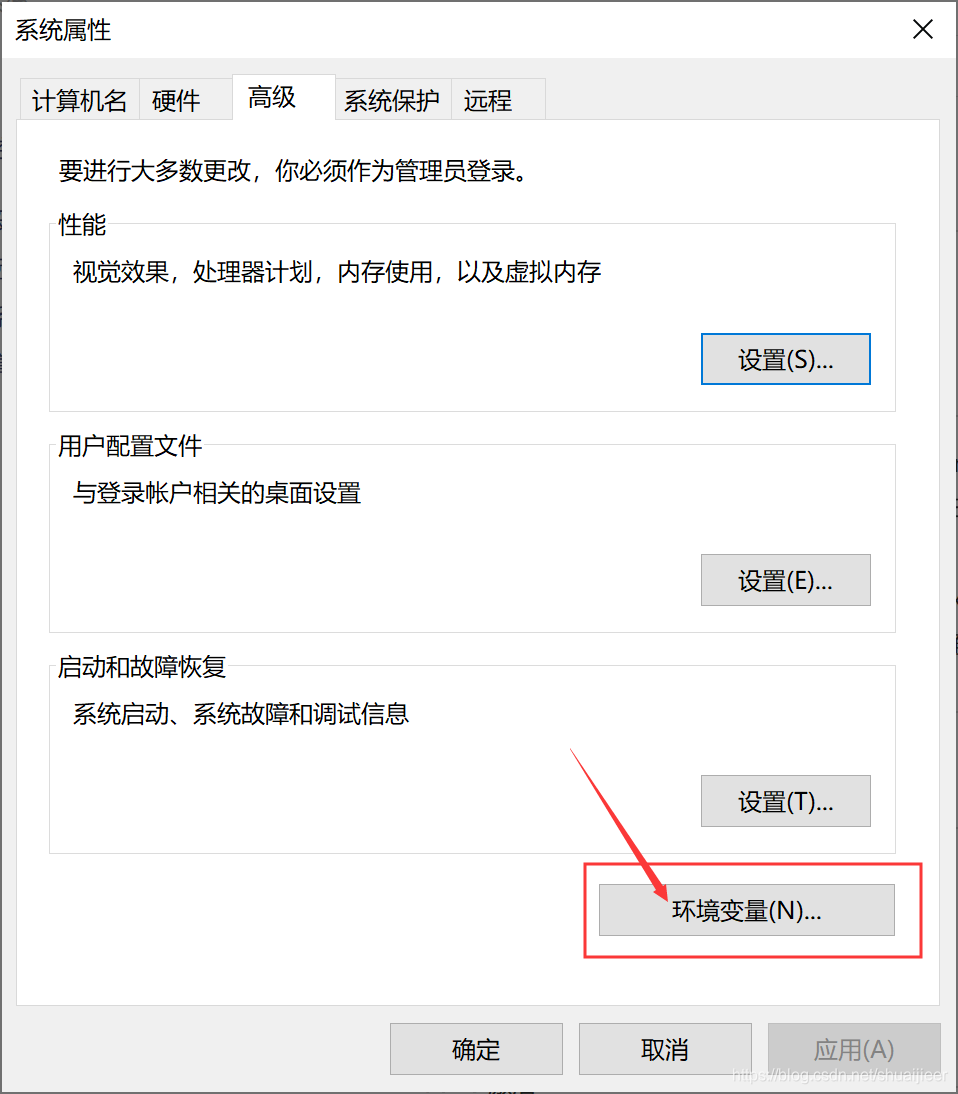
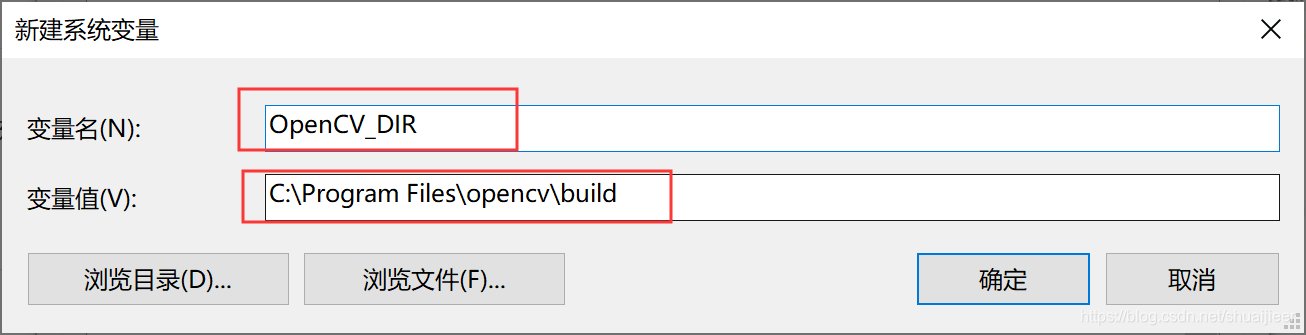
新建环境变量,变量名为OpenCV_DIR,变量地址为C:\Program Files\opencv\build
Cmake编译
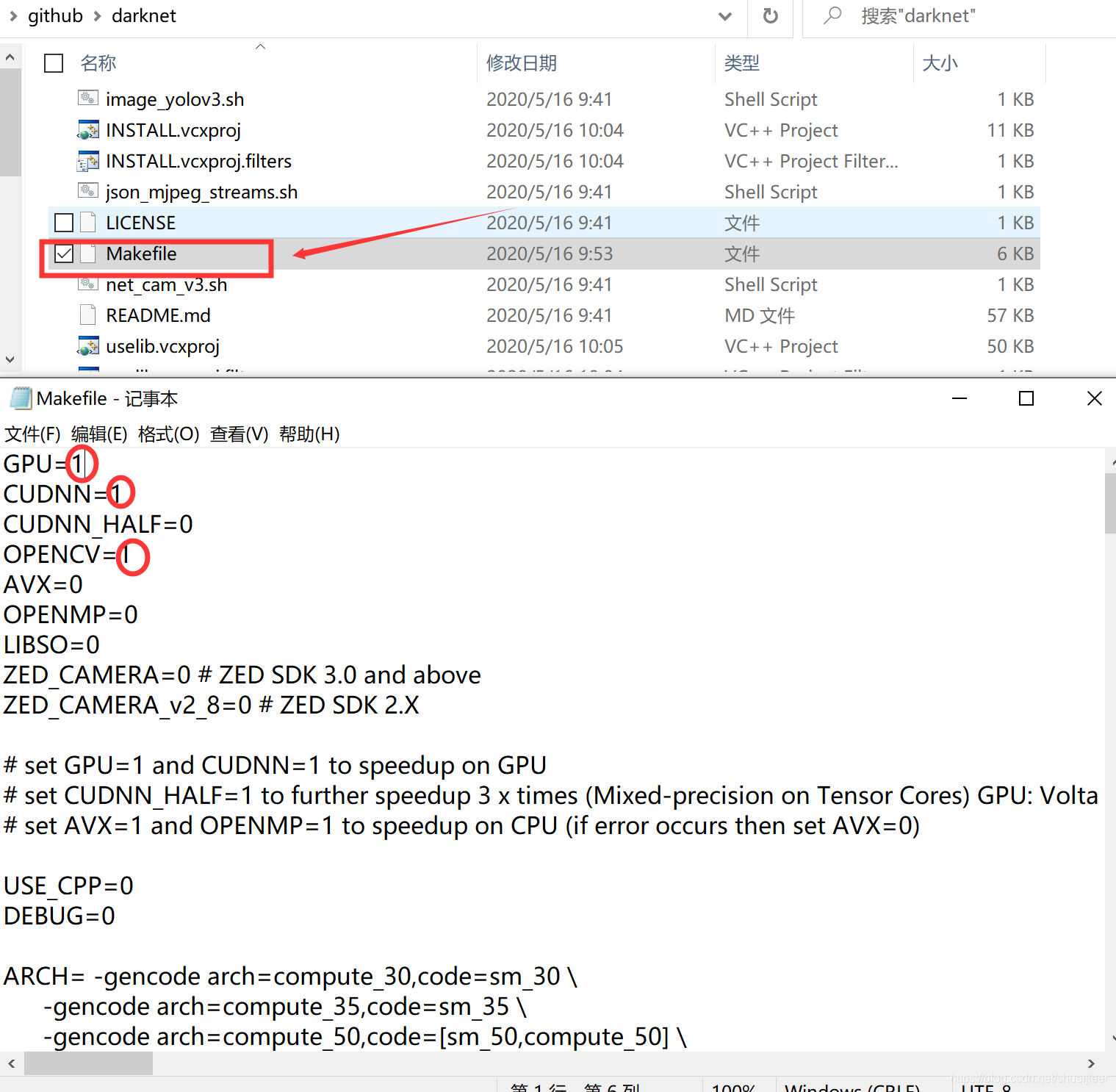
如果你想用GPU加快检测速度,需要将Makefile文件用记事本打开,更改GPU=1 CUDNN=1 CUDNN_HALF=1 OPENCV=1。如下图所示:
选择Browse Source 为源码所在文件夹,Browse Build 可以选择同一文件夹,点击Configure,弹出如下界面:

第一项选择你所安装的VS版本,第二项平台选择x64 ,点击Finish,点击Configure,没有错误后点击生成。
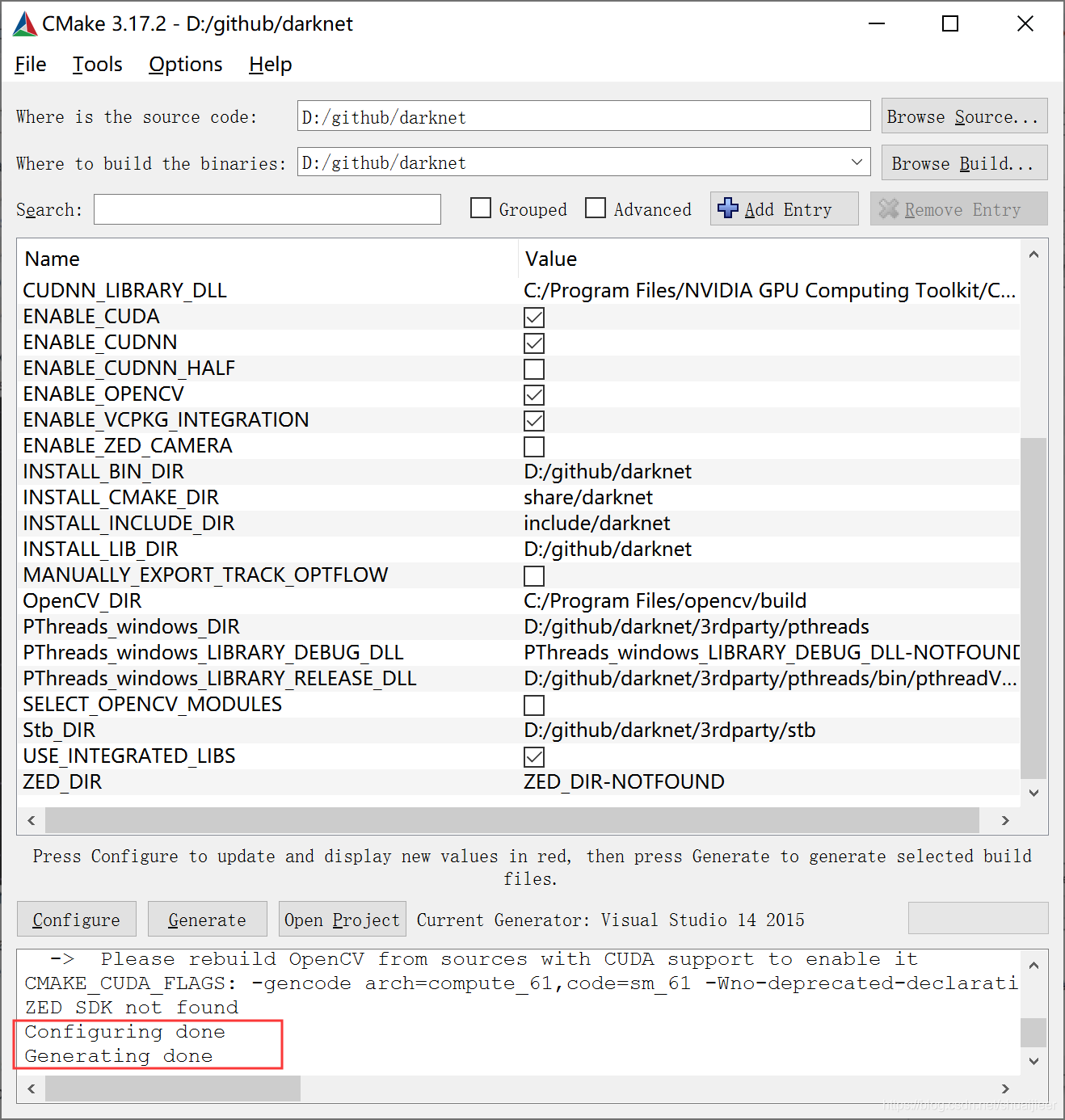
成功后点击Open Project 打开项目文件。
VS编译
注意:选择release版本,x64,直接生成解决方案。
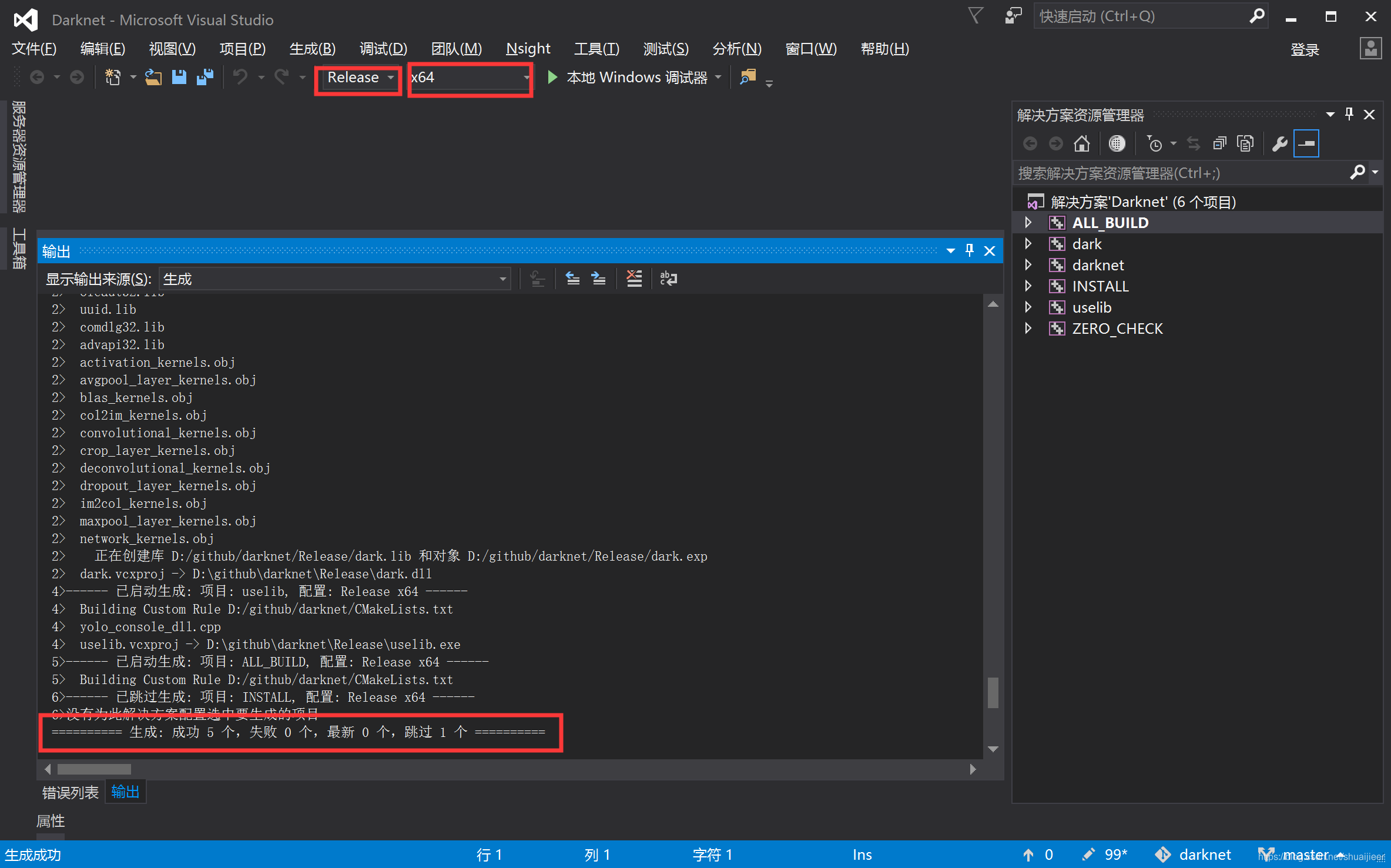
将D:\github\darknet\Release文件夹下的darknet.exe文件复制

打开到D:\github\darknet\build\darknet\x64文件夹内进行粘贴,如下图所示

将opencv ...\opencv\build\x64\vc14\bin 下的两个opencv_world330.dll和 opencv_ffmpeg330_64.dll dll文件复制到上述文件夹内。如下图所示:

将cuDNN中的cudnn64_7.dll复制到上述文件夹。

图像测试
为了验证是否配置成功,下载推荐的yolov4.weights文件,文件大概有245M,百度云.密码:wg0r
将下载后的文件放在D:\github\darknet\build\darknet\x64文件夹下。
打开cmd命令行,转到上述的文件夹内,如下图所示:
按照GitHub,测试图像和视频复制对应的命令:
Yolo v4 COCO - image: darknet.exe detector test cfg/coco.data cfg/yolov4.cfg yolov4.weights -thresh 0.25
Output coordinates of objects: darknet.exe detector test cfg/coco.data yolov4.cfg yolov4.weights -ext_output dog.jpg
Yolo v4 COCO - video: darknet.exe detector demo cfg/coco.data cfg/yolov4.cfg yolov4.weights -ext_output test.mp4

测试结果
-
自带的dog图像

-
羊群

训练
标注工具
labelImg: https://github.com/tzutalin/labelImg适用于图像检测的数据集制作,可以直接生成yolo的标注格式。
label 文件格式:
<目标类别> <中心点X坐标> <中心点Y坐标> <宽> <高>
(归一化到了【0,1】之间,除以图像宽高)
eg:<x> = <absolute_x> / <image_width>
<height> = <absolute_height> / <image_height>
几个常用的快捷键:
| w | 创建矩形框 |
|---|---|
| d | 下一张图片 |
| a | 上一张图片 |
另一个工具Yolo_mark:https://github.com/AlexeyAB/Yolo_mark
准备数据集
下面是标注文件为xml格式的处理过程,txt文件的话直接复制到labels文件夹即可
文件夹格式
VOCdevkit
——VOC2020
————---Annotations #放入所有的xml文件
————---ImageSets
——————-----Main #放入train.txt,val.txt文件
————---JPEGImages #放入所有的训练图片文件
————---labels #放入所有的txt文件,会自动生成此文件夹
————---TESTImages #放入所有的测试图片文件
#Main中的文件分别表示test.txt是测试集,train.txt是训练集,val.txt是验证集
创建文件夹的程序
import os
import time
def mkFolder(path):
year = str(time.localtime()[0])
floderName = 'VOC' + year
# path = os.path.normpath(path)
floderPath = os.path.join(path, floderName)
if not os.path.exists(floderPath):
os.makedirs(floderPath)
print(floderPath)
subfloderName = ['Annotations', 'ImageSets', 'JPEGImages', 'labels', 'TESTImages']
for name in subfloderName:
subfloderPath = os.path.join(path, floderName, name)
print(subfloderPath)
if not os.path.exists(subfloderPath):
os.makedirs(subfloderPath)
if name == 'ImageSets':
secSubFolderName = 'Main'
secSubFolderPath = os.path.join(path, floderName, name, secSubFolderName)
print(secSubFolderPath)
if not os.path.exists(secSubFolderPath):
os.makedirs(secSubFolderPath)
if __name__ == '__main__':
path = r'D:\program' #更换自己的文件夹路径
mkFolder(path)
获取所有文件名
可以修改训练集和验证集的比例,生成train.txt 和val.txt 文件
import os
from os import listdir, getcwd
from os.path import join
if __name__ == '__main__':
source_folder = 'D:/github/darknet/build/darknet/x64/scripts/VOCdevkit/VOC2020/JPEGImages'
dest = 'D:/github/darknet/build/darknet/x64/scripts/VOCdevkit/VOC2020/ImageSets/Main/train.txt' # train.txt文件路径
dest2 = 'D:/github/darknet/build/darknet/x64/scripts/VOCdevkit/VOC2020/ImageSets/Main/val.txt' # val.txt文件路径
file_list = os.listdir(source_folder)
train_file = open(dest, 'a')
val_file = open(dest2, 'a')
file_num = 0
for file_obj in file_list:
file_path = os.path.join(source_folder, file_obj)
file_name, file_extend = os.path.splitext(file_obj)
file_num = file_num + 1
if (file_num % 4 == 0): # 每隔4张选取一张验证集
val_file.write(file_name + '\n')
else:
train_file.write(file_name + '\n')
# val_file.write(file_name + '\n')
#
# train_file.write(file_name + '\n')
train_file.close()
val_file.close()
运行voc_label
将voc_label.py放到VOCdevkit文件夹下,如下图所示:

import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets=[('2020', 'train'), ('2020', 'val')] ##这里要与Main中的txt文件一致
#classes = ["bubble", "adhension","outer","inner"]
classes = ["bubble"] # #你所标注的类别名
def convert(size, box):
dw = 1./(size[0])
dh = 1./(size[1])
x = (box[0] + box[1])/2.0 - 1
y = (box[2] + box[3])/2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(year, image_id):
in_file = open('VOCdevkit/VOC%s/Annotations/%s.xml'%(year, image_id), encoding="utf8")
out_file = open('VOCdevkit/VOC%s/labels/%s.txt'%(year, image_id), 'w', encoding="utf8")
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult)==1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for year, image_set in sets:
if not os.path.exists('VOCdevkit/VOC%s/labels/'%(year)):
os.makedirs('VOCdevkit/VOC%s/labels/'%(year))
image_ids = open('VOCdevkit/VOC%s/ImageSets/Main/%s.txt'%(year, image_set)).read().strip('\n').split('\n')
list_file = open('%s_%s.txt'%(year, image_set), 'w')
for image_id in image_ids:
list_file.write('%s/VOCdevkit/VOC%s/JPEGImages/%s.jpg\n'%(wd, year, image_id))
convert_annotation(year, image_id)
list_file.close()
#os.system("cat 2020_train.txt 2020_val.txt > train.txt")
新建obj.data
复制cfg文件夹下的voc.data,重命名为obj.data
classes= 1
train = scripts/2020_train.txt
valid = scripts/2020_val.txt
names = data/obj.names
backup = backup/
新建obj.names
复制data目录下的voc.name,改为obj.name,里面写标签的名字,每行一个
修改cfg文件
把第三行batch改为batch=64
把subdivisions那一行改为 subdivisions=16
将max_batch更改为(数据集标签种类数(classes)*2000 但不小于训练的图片数量以及不小于6000)
将第20的steps改为max_batch的0.8倍和0.9倍
把位于8-9行设为width=416 height=416 或者其他32的倍数:
将classes=80 改为你的类别数 (有三个地方,969行,1056行,1143行)
改正[filters=255] 为 filters=(classes + 5)x3 (位置为查找yolo,每个yolo前的[convolutional]里,注意只修改最接近yolo的那个filters需要修改,一共应该有三处)
如果使用 [Gaussian_yolo] 层,修改 filters=(classes + 9)x3 (位置为CRRL+F查找Gaussian_yolo,每个Gaussian_yolo前的[convolutional]里,注意只修改最接近Gaussian_yolo的那个filters需要修改,一共应该有三处)
训练数据
开始训练
yolov4.conv.137为预训练权重,没有的话会随机初始化权重
预训练权重,密码:jirs
darknet.exe detector train data/obj.data yolov-obj.cfg yolov4.conv.137 -map
mAP(均值平均精度) = 所有类别的平均精度求和除以所有类别
每4个Epochs计算一次map
训练生成的权重文件在<backup>目录下:
last_weights 每迭代100次保存一次
xxxx_weights 每迭代1000次保存一席
继续训练
每迭代100步可以手动停止,下次训练加载此次的权重文件便可以接着训练。
eg:从2000步停止训练后,可以使用如下命令继续训练
darknet.exe detector train data/obj.data yolo-obj.cfg backup\yolo-obj_2000.weights
停止训练
停止训练的条件:
训练过程中如果 avg出现nan,训练可能出错,需要停止
如果nan出现在其他行,训练正常
如果迭代很多次后avg补再下降,需要停止
avg越低越好—,也要防止过拟合
对小的模型、简单的数据集,avg一般为0.05
对大的模型、复杂的数据集,avg一般为3
提高目标检测准确率
- 为了在一张图像上检测大量的目标:修改cfg文件,在最后一个[yolo]层增加max=200或者更大的值
- 为了检测更小的目标(自己的图像缩放到416X416目标尺寸小于16X16):
895行 layers = 23.
892行 stride=4
989行 stride=4
-
如果你的数据左右对象作为不同的类,比如:左右手、向左转、向右转路标
在数据增强部分 17行增加flip=0 -
如果小目标和巨大的目标一起训练,需要修改模型
-
为了使定位框更准确,在每个[yolo]层增加ignore_thresh = .9 iou_normalizer=0.5 iou_loss=giou——这会提高mAP@0.9, 但是会降低mAP@0.5.
-
如果你很精通,可以重新计算自己数据集的anchor
darknet.exe detector calc_anchors data/obj.data -num_of_clusters 9 -width 416 -height 416 -show
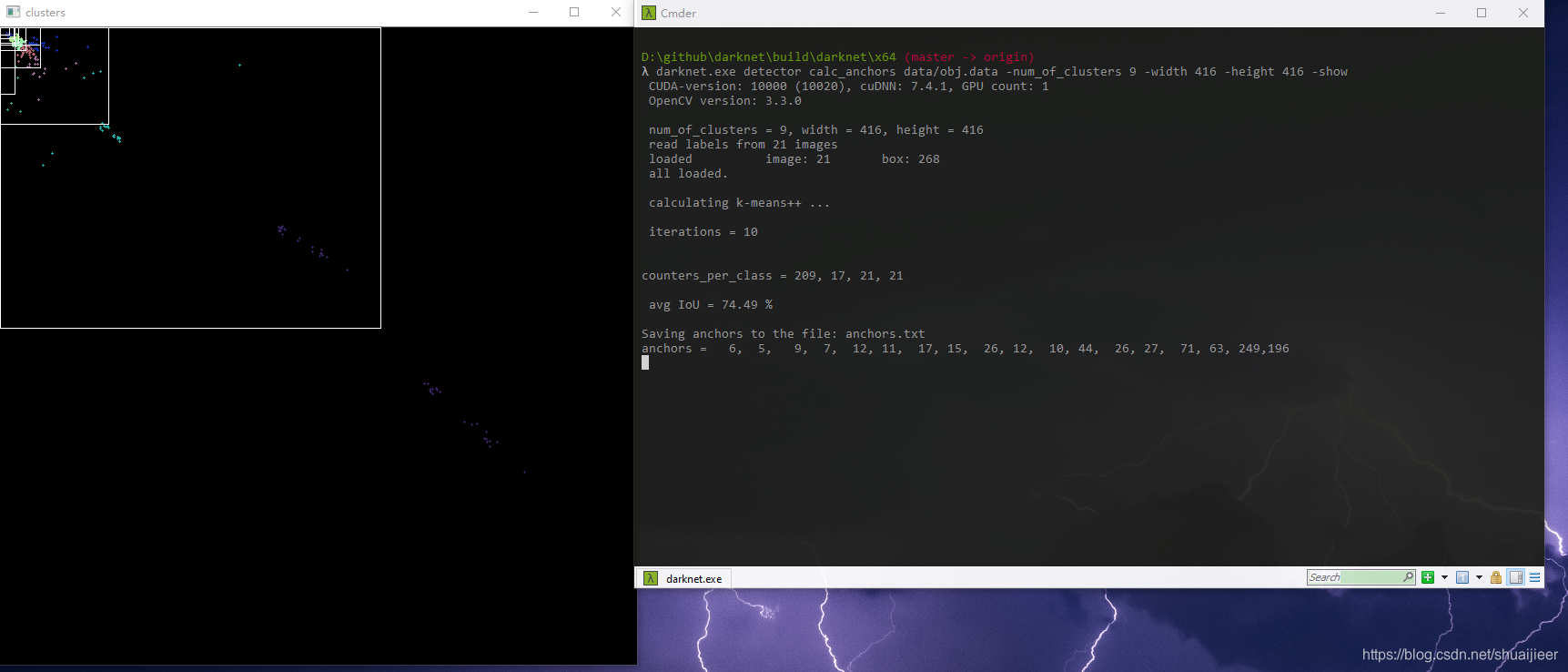
同目录下会生成anchors.txt
7. 更高的准确率需要更高的分辨率,608X608或者832X832,如果显存不够,增加subdivisions=16, 32 or 64
测试
批量测试
还是修改源码吧,修改
detector.c
大不了重新编译一次,终于发现了之前GetFilename函数获取文件名的问题,只能复制文件名的前3个字符给保存的结果文件名,就导致之前出现一直会覆盖掉之前文件的错误
char *GetFilename(char *p)
{
static char name[20] = { "" };
char *q = strrchr(p, '/') + 1; //在文件名中从后往前查找第一个/
memset(name, ' ', sizeof(name)); //清除内存位置
strncpy(name, q, 10); // 把文件名复制到name中,最多复制n个字符
return name;
}
现在这样就好啦!
记得把下面这块也改一改,在1659行左右,
方法ctrl+F查找draw_detections_v3,修改上面那个
draw_detections_v3(im, dets, nboxes, thresh, names, alphabet, l.classes, ext_output);
//save_image(im, "predictions");
char b[1024];
sprintf(b, "output/%s", GetFilename(input));
save_image(im, b);
测试前修改cfg文件,把#Testing 下的两行解除注释
[net]
# Testing
batch=1
subdivisions=1
# Training
batch=32
subdivisions=16
width=416
height=416
channels=3
momentum=0.949
decay=0.0005
angle=0
saturation = 1.5
exposure = 1.5
hue=.1
最后贴一下训练及测试的命令,谨此铭记
训练数据
darknet.exe detector train data/obj.data yolov-obj.cfg yolov4.conv.137
单张测试
darknet.exe detector test data/obj.data yolov-obj.cfg backup/yolov-obj_800.weights test.jpg -i 0 -thresh 0.25 -gpus 0,1,2,3
批量测试结果保存至output文件夹
darknet.exe detector test data/obj.data yolov-obj.cfg backup/yolov-obj_800.weights -ext_output < data/test.txt > result.txt -gpus 0,1,2,3
不想显示的话
darknet.exe detector test data/obj.data yolov-obj.cfg backup/yolov-obj_800.weights -ext_output -dont_show < data/test.txt > result.txt -gpus 0,1,2,3
想要输出坐标的话
darknet.exe detector test data/obj.data yolov-obj.cfg backup/yolov-obj_800.weights -ext_output dog.jpg
 浙公网安备 33010602011771号
浙公网安备 33010602011771号