

图像检索(image retrieval)- 4 - Visual Search at eBay -1-论文学习
Visual Search at eBay
ABSTRACT
在本文中,我们提出了一种新的端到端的可扩展的视觉搜索架构。我们讨论了在ebay这种有着巨大波动存储的网站中我们面临的挑战,并提出了我们的解决方案来克服这些挑战。我们利用ebay列表中大量可用的数据集和最先进的深度学习技术来执行大规模的视觉搜索。用于优化搜索的基于监督的方法将结果限制在最高(top)预测类别,使用紧凑二进制签名的基于监督的方法是扩展规模的关键并以损害精度和精度为代价。这两者都使用一个共同的深度神经网络,只需要一个前向推理。系统体系结构与它经过深入讨论后得到的基本组件和为了权衡搜索相关性和延迟的优化方法一同提出。该解决方案目前部署在分布式云基础设施中,并为eBay ShopBot和Close5中的视觉搜索提供了动力。我们展示了在ImageNet数据集上的基准测试,我们的方法比几个无监督基线更快更准确。我们分享我们的经验,希望视觉搜索成为所有大型搜索引擎的一流公民,而不是马后炮。
1 INTRODUCTION
随着在线照片和公开的图像数据集的指数增长,视觉搜索或基于内容的图像检索(CIBR)最近引起了人们的极大兴趣。尽管许多成功的商业系统已经在运行视觉搜索,但很少有出版物详细描述端到端系统,包括算法、架构、在生产中大规模部署它的挑战和优化[10,11,19]。
视觉搜索对于像eBay这样的市场来说是一个极具挑战性的问题,主要有4个原因:
Volatile Inventory: 与标准搜索引擎的情况不同,在像eBay这样的动态市场中,每分钟都有大量的商品被列出并出售。因此,清单的寿命很短。
Scale: 大多数视觉搜索解决方案工作在中小规模的数据集,但不能在eBay这样大规模数据集上使用。此外,eBay的库存包括许多难以分类的细粒度类别。我们需要一个分布式的架构来处理这种有着高搜索相关性和低延迟的庞大库存。
Data Quality: 图像质量在eBay的库存是多样的,因为它是一个平台,既可以给高容量用户,也可以给偶尔卖家使用。将此与各种流行的商业站点中的目录质量图像进行比较。而且一些列表中可能有错误的或缺失的标签,这给模型学习增加了更多的挑战。
Quality of Query Image: eBay ShopBot允许用户上传从任何来源获取的查询图像,而不仅仅局限于库存中的现有图像(参见图1)。
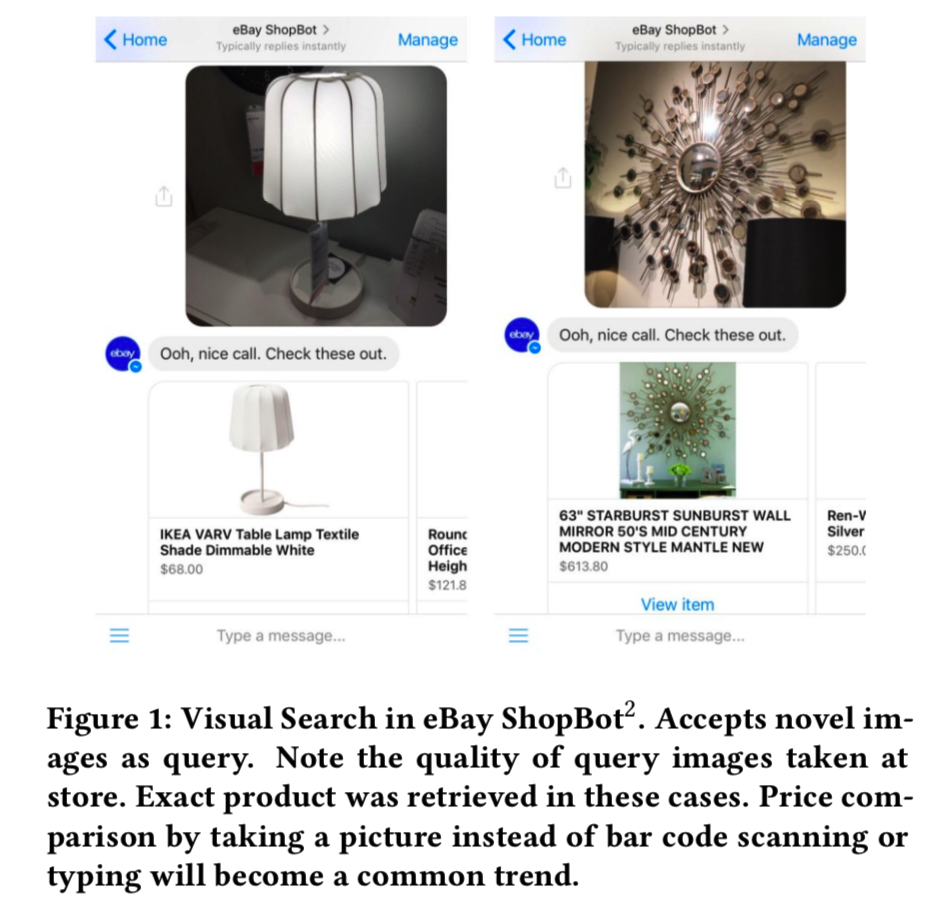
我们将描述如何应对上述挑战。我们介绍了我们的方法,技巧和技巧,以建立和运行一个计算效率高的大规模视觉搜索系统。我们将介绍我们系统的架构,以及如何利用深度神经网络来提高精度和速度。讨论了如何训练统一深度神经网络(DNN)进行类别分类、二值签名提取以及aspect预测。我们使用公共图像数据集(ImageNet[5])进行实验,以定量评估我们的网络的有效性。我们还展示了eBay的视觉搜索是如何在最近发布的产品—eBay ShopBot(一个集成到Facebook Messenger平台中的聊天机器人)和eBay拥有的基于位置的买卖移动应用程序—close5中部署使用的,该应用程序能够从eBay库存中为用户发现类似的产品。
本文的其余部分组织如下:第2节回顾了基于深度学习的视觉搜索算法的最新文献,以及我们的方法与现有商业应用的不同之处。接下来是我们在第3节中的分类/aspect 预测和二值哈希提取方法。我们将在第4节中介绍基于云的分布式图像搜索架构。接下来,我们对包含1.2M图像的ImageNet[5]进行了定量分析,并给出了实验结果,以证明我们的模型的有效性。最后,第6节和第7节给出了eBay ShopBot和Close5的结果,第8节给出了结论。
2 RELATED WORK
使用种子图像寻找相似项是[4]深入研究的问题,但它仍然是一个具有挑战性的问题,因为图像可以在多个层次上相似。近年来,随着深度卷积神经网络的兴起,视觉搜索引起了广泛关注[2,9,10,21]。在像ImageNet[12]这样的大型图像数据集上,深度学习已经被证明在语义特征表示和多类图像分类方面非常强大。
Krizhevsky等人[12]在ImageNet上展示了强大的视觉检索结果,他们使用最后的隐藏层对图像进行编码,并计算欧氏空间中图像之间的距离。这对于大规模的视觉搜索是不可行的(大量高维特征计算欧式距离十分费时)。各种方法利用深度卷积神经网络(CNNs)学习图像的紧凑表示(即更低维的表征),以实现快速和准确的检索,同时减少存储开销。大多数方法[1,7,13,14,20,22]都专注于通过监督的方式学习哈希函数,使用成对相似和不相似图像的相似度,以便学习的二值哈希捕获原始欧几里得空间中图像的相似度。PCA和discriminative dimensionality reduction由Babenko等人提出。[1]提供了具有最高精确度的短code,但需要大量的成对图像集来最小化它们之间的距离。Xia等人[20]提出了一个两阶段的框架来学习哈希函数和特征表示,但它需要昂贵的相似矩阵分解。Lai等人[13]直接学习具有triplet排序损失的哈希函数,而Zhu等人[22]在深度CNN框架下引入了成对的交叉熵损失和成对的量化损失。然而,对于ebay这样一个新产品频繁出现的易变库存来说,在所有类别中收集大量的图像对在计算上是低效的,也是不可行的,特别是在其类别树是细粒度的并且有时会重叠的情况下。
另外,一些工作直接使用point-wise标签学习哈希函数,而不求助于图像的成对相似性[16,17]。Lin等人[16]提出了一种监督学习技术,以避免成对输入,并以point-wise方式学习二进制哈希,这使得它对大规模数据集具有吸引力。[15]还提出了一种无监督学习方法,通过在不使用图像标注的情况下优化三种类型的目标来学习二值哈希。尽管这些研究取得了成功,但如何将这些研究成果转化为实际生产仍存在挑战和未解之谜。以前的算法只能在最多包含几百万张图像的数据集上进行评估。然而,考虑到eBay的规模数据集,在低延迟的情况下执行数亿个汉明距离计算,同时发现最相关的项目,是具有挑战性且不容易的。
考虑到这些现实的挑战,我们提出了一个可扩展且资源高效的混合视觉搜索引擎。我们的第一个贡献是一种能在三个阶段使用监督学习的hybrid技术:
- 首先对一个项目进行分类图像到正确的分类桶大大减少搜索空间,
- 紧随其后的是一个由Lin等人[16]提出的监督二进制哈希技术并基于视觉aspect(品牌、颜色等)识别进行重新排序做为结尾,确保我们展示的相似物品不仅在类或类别上相似,也有着相似的aspect。
前两个任务使用一个DNN进行推理。
第二个贡献是演示我们在eBay ShopBot中部署的分布式架构,在一个高可用性和可扩展的基于云的解决方案中提供可视化搜索。一些商业视觉搜索引擎是高度以fashion为导向的[11,19],其中支持的类别仅限于服装产品(即该平台主要就是用来卖衣服的),而我们的目标是通用的视觉搜索和具有更广泛类别覆盖范围的目标检索。我们还从深度CNN学习了完全监督的二值图像表征,而不是使用低层次的视觉特征[19]或昂贵的浮点深度特征(即特征值是浮点型的)[10]。此外,我们允许用户在不受约束的环境中自由拍照,这将我们与现有的视觉搜索系统区别开来,后者只接受库存中已经存在的干净、高质量的目录图像。
3 APPROACH
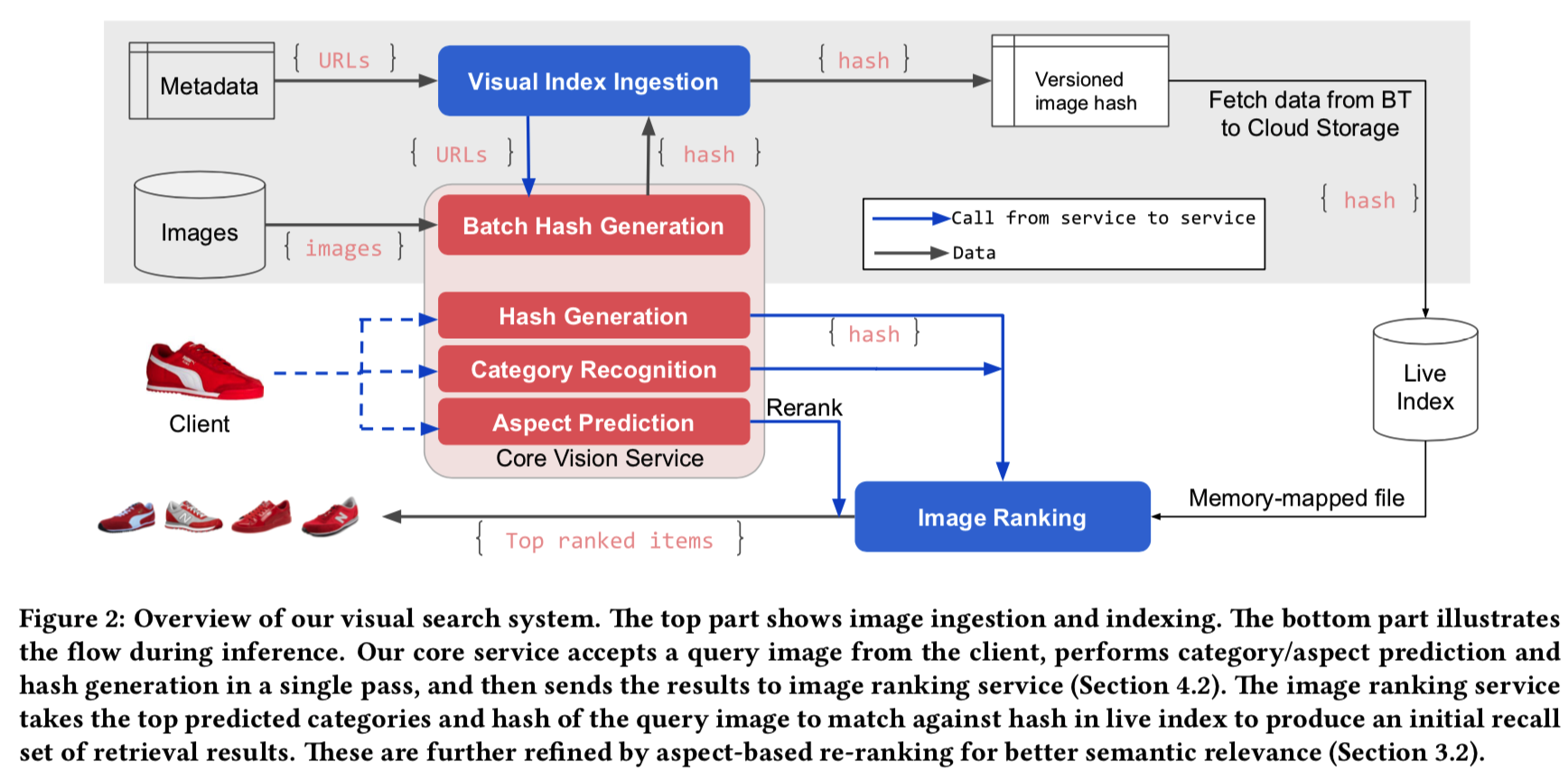
图2说明了可视化搜索系统的总体体系结构。在[10,11]中,我们的方法是基于DNN。但是,我们并没有直接从DNN中提取特征并对整个数据库进行穷举搜索,而是只在预测的最高类别中搜索,然后使用带有汉明距离的语义二值哈希进行快速排序(Pinterest)。为了提高速度和降低内存占用,我们使用共享拓扑进行类别预测和二进制hash提取,其中我们只使用一次传播进行推理。
3.1 Category Recognition
我们的目标不是将物品分类为一般的类别,如人、猫和衣服等,而是识别出更精细的产品类别。例如,我们想要区分男装运动鞋和女装运动鞋,孕妇装和跳舞装,甚至是不同国家的硬币。我们把这些细粒度的分类称为叶子类别。我们使用最先进的ResNet-50网络[8]在准确性和复杂性之间进行良好的平衡。该网络是基于一组来自不同eBay产品类别(包括时尚、玩具、电子产品、体育用品等)的图像从零开始训练的。我们删除任何重复的图像,并将数据集分成一个训练集和一个验证集,其中每个类别在训练和验证集都有图像。将每个训练图像调整为256×256像素,将进行中心227×227裁剪的图像及其镜像版本输入网络作为输入。我们利用分类任务的标准多项式logistic损失来训练网络。为了充分利用深度网络的能力,我们利用不同的学习参数组合对网络进行微调。具体地说,我们在几个epochs的训练后改变学习参数(即训练优化参数),并重复这个过程几次,直到验证精度饱和。
为了进一步提高网络处理对象变化的能力,我们在训练期间进行动态数据增强,以丰富训练数据,其中包括随机几何变换、图像变化和灯光调整。表1显示了对不同图像旋转进行数据增强后的绝对改善结果哦。本实验中使用的所有图像都来自验证集,因此涵盖了所有的类别。除了额外的数据扩充模块,所有的学习参数都是相同的。总的来说,数据的增加使类别预测的top-1的准确率绝对提高了2%。

3.2 Aspect Prediction
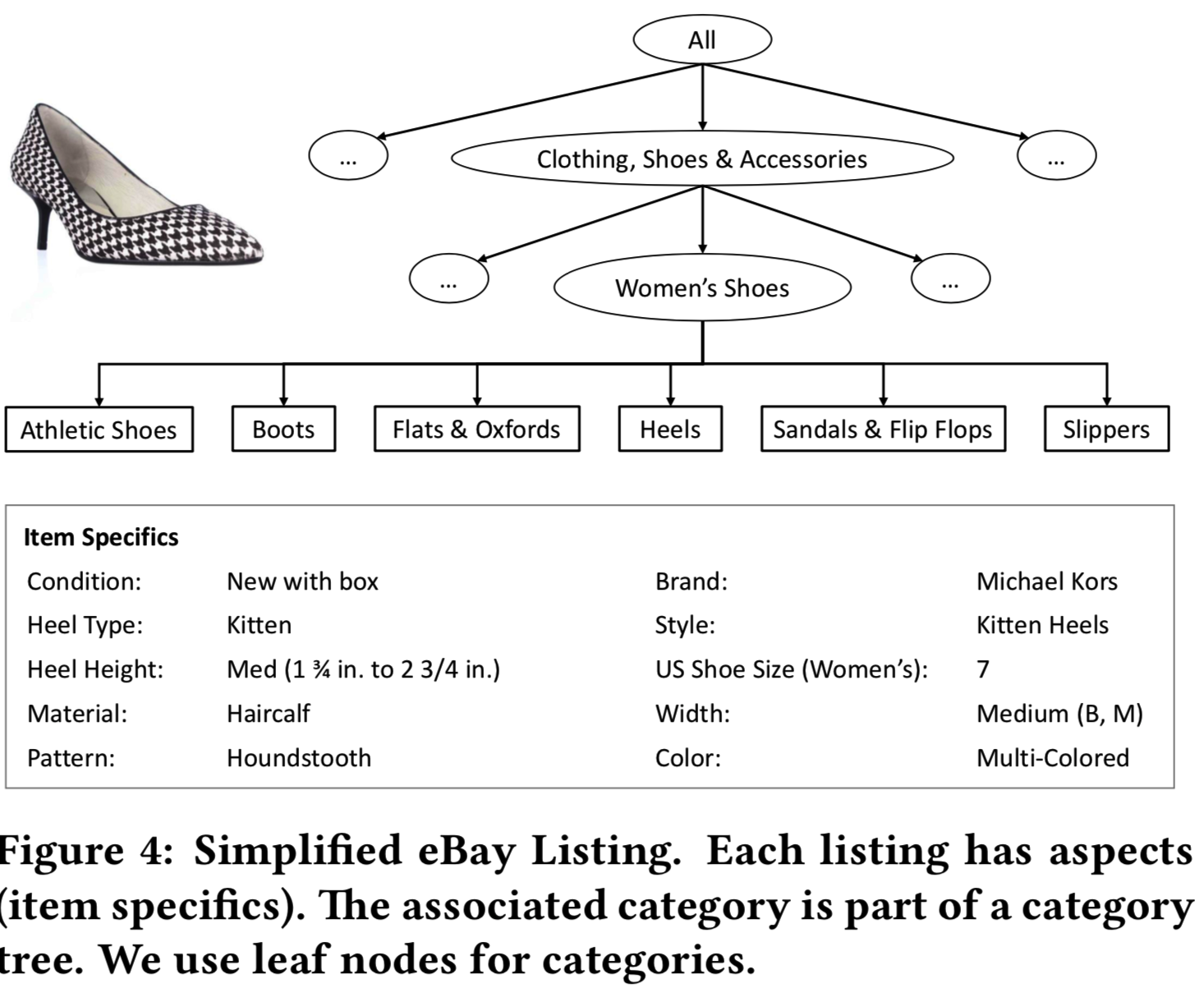
除了叶子类别标签外,产品图片还与丰富的信息相关联,如颜色、品牌、风格、材料等。这些属性称为aspect(图4),向每个产品添加语义信息。我们的aspect分类器是建立在共享的类别识别网络之上的(章节3.1)。具体来说,为了节省计算时间和存储空间,所有aspect模型都与主DNN模型共享参数到最后的pool层(即全连接层fc的前面一层,resnet50的pool层输出尾2*2*2048)。接下来,我们为每个aspect类型创建一个单独的分支。我们的aspect涵盖了广泛的视觉属性,包括颜色,品牌,风格等。请注意,虽然一些aspect(如颜色)出现在多个叶子类别下,但其他aspect是特定于某些类别的。例如,宝石与珠宝相关,而袖长与上衣相关。因此,我们将来自pool5层的图像表征嵌入一个叶子类别的one-hot编码向量表征。这将视觉外观和分类信息集成到一个表征中(即如果该表征的aspect与多个叶子类别相关,其对应的one-hot编码向量表征中就会有多个叶子类别,将两者对应起来,比如只有当输入的图像是珠宝时,该图像对应的aspect中才会有宝石这个aspect项,需要判断该aspect,否则如果是其他图像,就不需要这个aspect项。我觉得实现的方法应该是为aspect创建一个分支,假设所有aspect有30项,但是每个叶子类别的图像对应的aspect项并不是30项都满足,所以会为每个叶子类别构建一个one-hot向量对应其相应的aspect,在分类层前,将这个one-hot向量与pool层表征相乘,只得到对应的aspect的输出,不对应的aspect即为0,当然,这是我的想法)。这对于我们多类分类器的选择特别有用。我们使用梯度增强机器[6]来支持分类和非分类输入的速度和灵活性。由于boosting背后的想法是将一系列较弱的学习者结合在一起,因此我们的模型根据叶子类别创建了视觉空间的若干分割。我们使用XGBoost[3]来训练aspect模型(使用上面分类网络提取的特征向量来训练)。它允许使用最少的资源且仅使用CPU进行快速推理。我们训练一个可以从图像中推断出的各个aspect的模型。
3.3 Deep Semantic Binary Hash
在设计一个真实的大型视觉搜索系统时,可扩展性是一个关键因素。虽然我们可以直接从一些卷积层或全连接层中提取和索引特征,但它远不是最优的,扩展性也不好。存储实值特征向量既麻烦又代价昂贵。此外,两两计算欧几里得距离效率低下,这会显著增加延迟并降低用户体验。为了解决这些问题,我们将图像表示为二进制签名而不是真实值,从而大大降低存储需求和计算开销。我们将在5.2.1节中说明,从实值特征向量到二进制特征向量的准确性不会损失太多。
在[16]之后,我们将一个额外的全连接层附加到最后一个共享层(图3),并使用sigmoid函数作为激活函数。sigmoid激活函数将激活限制为0到1之间的有界值。因此,在推理期间通过简单的阈值0.5对这些激活进行二进制化是很自然的选择(即大于0.5则为1,小于0.5则为0)。虽然可以应用更复杂的二值化算法,但我们发现使用0.5作为阈值已经实现了bits的平衡,并且在我们的产品中获得了令人满意的性能。这种网络分割拓扑的底层流是独立于上层流进行训练的,固定了共享层和学习后一层的权值,使用的分类损失与我们用于类别识别的相同。这种监督方法有助于在二进制hash中编码语义信息。我们将在5.2.2节中展示,与流行的无监督方法相比,我们的方法获得了巨大的好处。因此,我们使用单一的DNN网络来预测类别和提取二值语义哈希。同时,利用该网络提取特征向量用于aspect预测。所有这些操作都在一次传递中执行。完整的模型如图3所示。
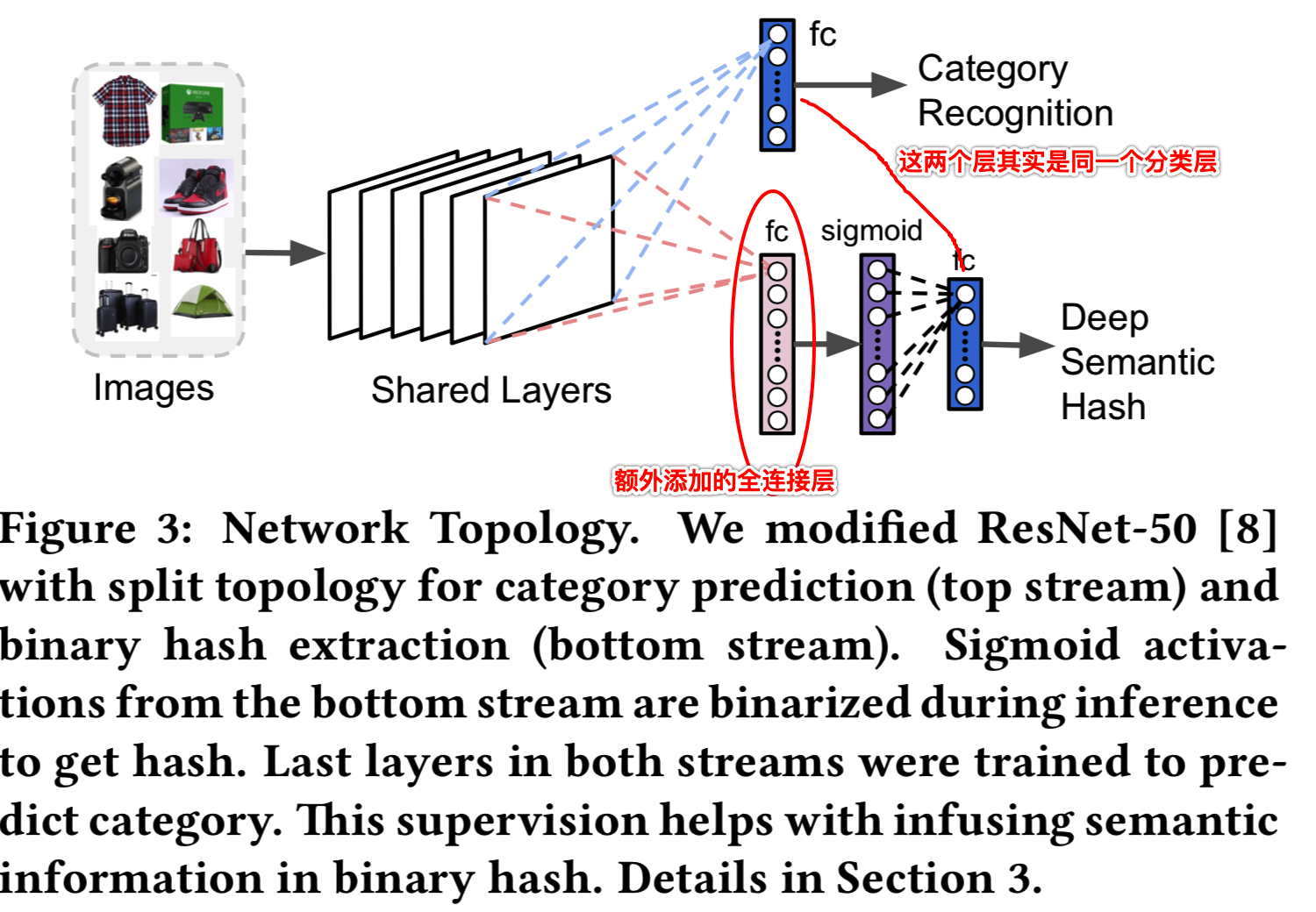
我们在二进制语义哈希中使用了4096位,它对应于图3中深度语义哈希分支新添加的全连接层的神经元数。使用4096维的二进制特征向量大大降低了存储需求。具体来说,这样一个二进制向量只占用512字节(即4096/8 = 512),使得200M图像的总存储空间小于100GB。相反,如果从最后的共享层(pool5层)提取特征,我们将获得一个8192维浮点矢量(从2×2*2048卷积过滤器)的特征图谱,这需要32KB的空间(因为每个浮点值需要使用32位,8192*32=32KB),导致存储相同数量的图像需要一个巨大的6.1TB的存储空间。这将减少90%的存储空间。此外,由于汉明距离的计算速度比欧氏距离快得多,因此使用二进制表征更为有效。(说明使用二进制特征向量的好处)
为了进一步提高速度,我们只从top预测的叶子类别中搜索最相似的图像,这样我们可以大大降低覆盖所有类别的整个数据库的穷举搜索的开销。从top类别返回的top匹配将被合并并再次排序,以生成最终的排名列表。(即输入一张图,得到其对应叶子类别的概率,从中选出top M的叶子类别,然后就只用在这M个叶子类别对应的数据中搜索相似图像,将搜索空间缩减很多,并从每个叶子类别中也分别搜索出top N个相似图像,将这M*N张图像合并在一起,再从中得到top K张相似的图像做为最后的输出)
3.4 Aspect-based Image Re-ranking
我们的初始结果是通过比较图像的二值签名(即上文得到的Semantic Binary Hash)得到的。但是,我们可以利用aspect预测的语义信息来进一步提高搜索的相关性。假设我们的模型为一个查询图像q生成n个aspect(aiq),库存中每一个匹配项都有一组m个aspect(aj)和其对应的value,这是listing期间由卖方填在网站上的信息。我们检查预测的aspect(aiq)是否与这些真实的aspect(aj)匹配,并分配一个"reward point" wi 到每个有确切匹配的预测aspect aj上(即aiq == aj)。最后的分数,定义成aspect匹配分数![]()
![]() ,通过积累所匹配aspects的分数而成(进行n*m次比较是因为n和m不一定相等,则aspect值内容不是一一对应的,要一个个对比)。这里
,通过积累所匹配aspects的分数而成(进行n*m次比较是因为n和m不一定相等,则aspect值内容不是一一对应的,要一个个对比)。这里![]() 是一个指标函数,只有在预测aspect和真实aspect相同时才等于1。为了简单起见,我们为所有aspect分配了hard-code的reward point,尽管它们可以从数据中学习。此外,我们并没有对所有aspect一视同仁,而是考虑到在电子商务场景中,有些aspect对于用户购买更为重要,所以我们给他们分配了不同的reward point。在我们的系统中,我们对尺寸size、品牌brand和价格price分配较大的分数,其他aspect则同样重要。
是一个指标函数,只有在预测aspect和真实aspect相同时才等于1。为了简单起见,我们为所有aspect分配了hard-code的reward point,尽管它们可以从数据中学习。此外,我们并没有对所有aspect一视同仁,而是考虑到在电子商务场景中,有些aspect对于用户购买更为重要,所以我们给他们分配了不同的reward point。在我们的系统中,我们对尺寸size、品牌brand和价格price分配较大的分数,其他aspect则同样重要。
在计算aspect匹配得分后,我们将其与图像排序中的视觉外观得分Sappearance(归一化汉明距离)混合,得到最终的视觉搜索得分,用来对产品图像的初始排序列表进行重新排序,即有效相似度得分为![]() 。线性组合允许快速计算而不降低性能。在我们当前的解决方案中,组合权值λ是固定的(λ=0.75),但也可以动态地配置,以适应时间的变化。我们给予外观分数更多的重要性,是为了让结果对由经验不足的卖家创建的aspect标签上可能有的噪音不敏感(即卖家可能标错一些aspect标签,不让其对最终结果有太大影响)。
。线性组合允许快速计算而不降低性能。在我们当前的解决方案中,组合权值λ是固定的(λ=0.75),但也可以动态地配置,以适应时间的变化。我们给予外观分数更多的重要性,是为了让结果对由经验不足的卖家创建的aspect标签上可能有的噪音不敏感(即卖家可能标错一些aspect标签,不让其对最终结果有太大影响)。
图5显示了通过aspect重新排序提高相关性的一些示例。对于蓝色牛仔裙,在重新排序之前,第一个和第四个检索到的图像与查询的颜色不匹配。我们观察到,经过类别分类训练的深层特征有时可能会剥夺颜色信息。使用aspect的color值进行重新排序后,实现了颜色匹配。第二个例子是一个手袋在恶劣的照明条件下。由于图像质量问题,我们无法得到准确匹配的产品。相反,我们得到了类似的袋子。没有aspect的预测,第二个图像不局限于查询中的品牌brand。使用aspect重新排序后,品牌brand在top检索中与query图像相匹配。在第三个例子中,婚纱的肩带在哈希表征中被忽略了。按照领口形状等aspect重新排序,即使我们没有检索到确切的产品,也能在保留总体相似性的同时,优化结果以匹配细粒度特性。
4 SYSTEM ARCHITECTURE
4.1 Image Ingestion and Indexing
全世界的eBay卖家每秒都会生成大量的库存图像更新。每个清单(listing)可能包含多个图像,以及多个图像的多个变体。我们的摄取管道(图6)能够近实时(near-real-time)检测图像更新,并在云存储中维护它们。为了减少存储需求,检测并交叉链接清单中的重复图像(大约三分之一,即实现去重操作)。
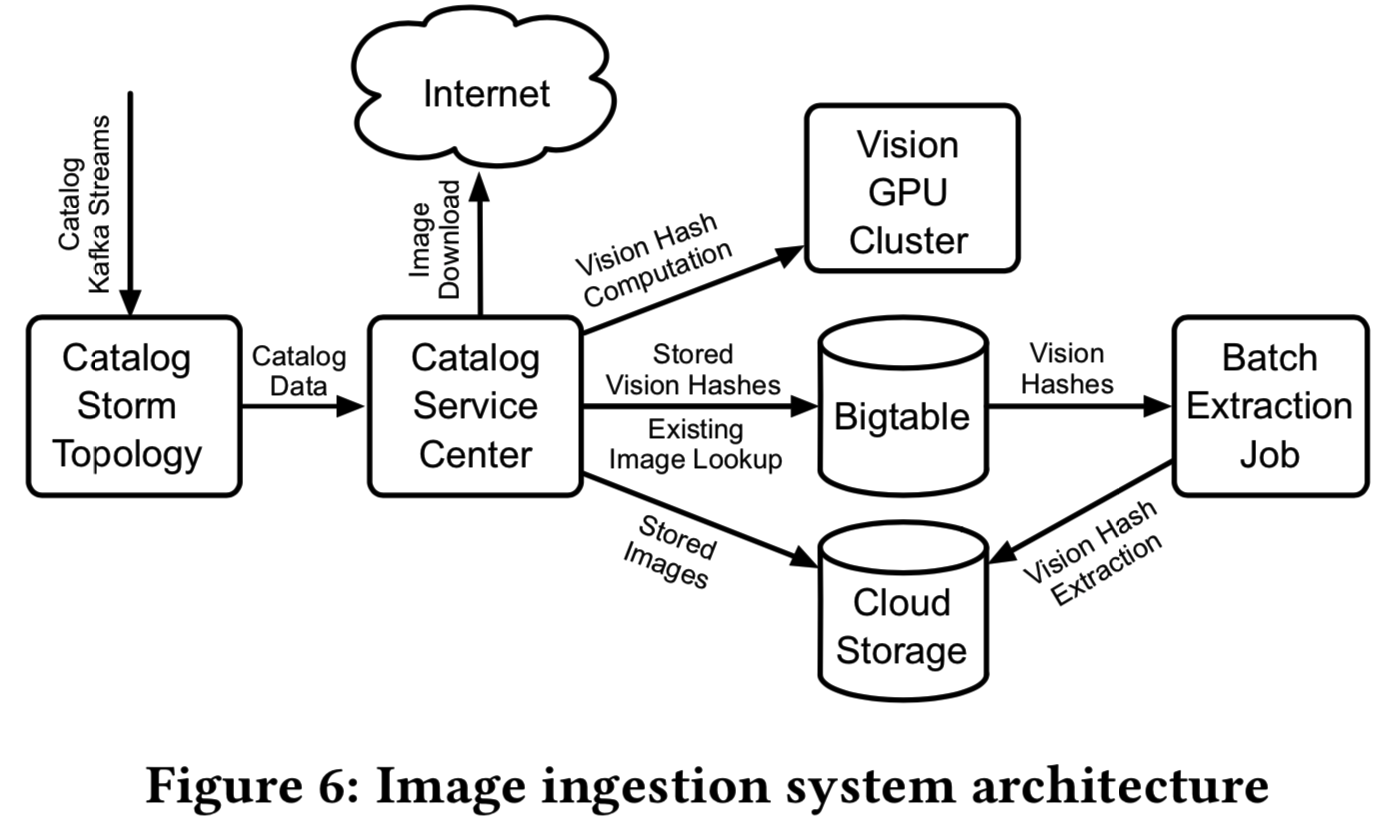
为了检测重复,我们在图像比特上比较MD5哈希。最初,我们在调整大小并将图像转换为RGB模型后,对颜色通道的位进行哈希计算,然而,后面变成了使用精确匹配方法,即直接在图像位上计算哈希而不调整大小,给出了接近的重复检测率,同时大大降低了计算成本。(即直接对图像求hash值,hash值相同的图即重复图)
当来自新listings的图像到达时,我们根据批处理哈希提取服务(batch hash extraction service,图2)以micro-batch的方式为主listing图像计算图像哈希,该服务是运行我们预先训练好的DNN模型的GPU服务器集群(这里的哈希提取服务就不是上面用于去重的hash计算了,而是图3中的semantic hash计算)。图像hashes存储在一个分布式数据库中(我们使用谷歌Bigtable),由图像标识符键入。
为了建立索引indexing(其实就是将图像标识符和图像的semantic hash一一对应,这样之后就能够使用标识符得到图像的semantic hash了),我们每天从Bigtable为所有可用listings在支持的类别中生成图像hash extracts。批处理提取(extraction)过程使用HBase Bigtable API作为并行Spark作业在cloud Dataproc中运行。提取(extraction)过程是通过扫描带有当前可用listing标识符及其类别id的表,并在支持类别中过滤listings来驱动的。然后,过滤后的标识符用于在micro-batch中查询编目表中的listings(这前面的操作感觉像是为图像hash选取合适的图像标识符)。对于每个返回的listing,我们提取图像标识符,然后在micro-batch中查找相应的图像散列hashes。前面有listing标识符的图像散列hashes被附加到二进制文件中(这里就是图像标识符选好后,再将其和图像hash一一对应即完成了indexing)。listing标识符和图像哈希都以固定长度写入文件中(listing标识符为8字节,图像哈希为512字节)。我们为每个作业分区的每个类别编写一个单独的文件,并将这些中间extracts存储在云存储中。完成所有作业分区之后,我们下载每个类别的中间extracts,并跨所有作业分区连接它们。拼接的片段被上传回云存储(这就是当想要得到某个叶子类别对应的所有图像时的操作,因为数据被分区存储,即每个分区分别提取后再集中在一起返回)。
我们经常更新我们的DNN模型。为了处理频繁的更新,我们有一个独立的并行作业,它批量扫描所有活动listings,并从存储的图像重新计算图像hashes。我们在Bigtable中为每幅图像保留了2个哈希值,对应于旧的和新的DNN模型版本,所以在哈希重新计算运行时,旧的哈希版本仍然可以用于提取。
4.2 Image Ranking
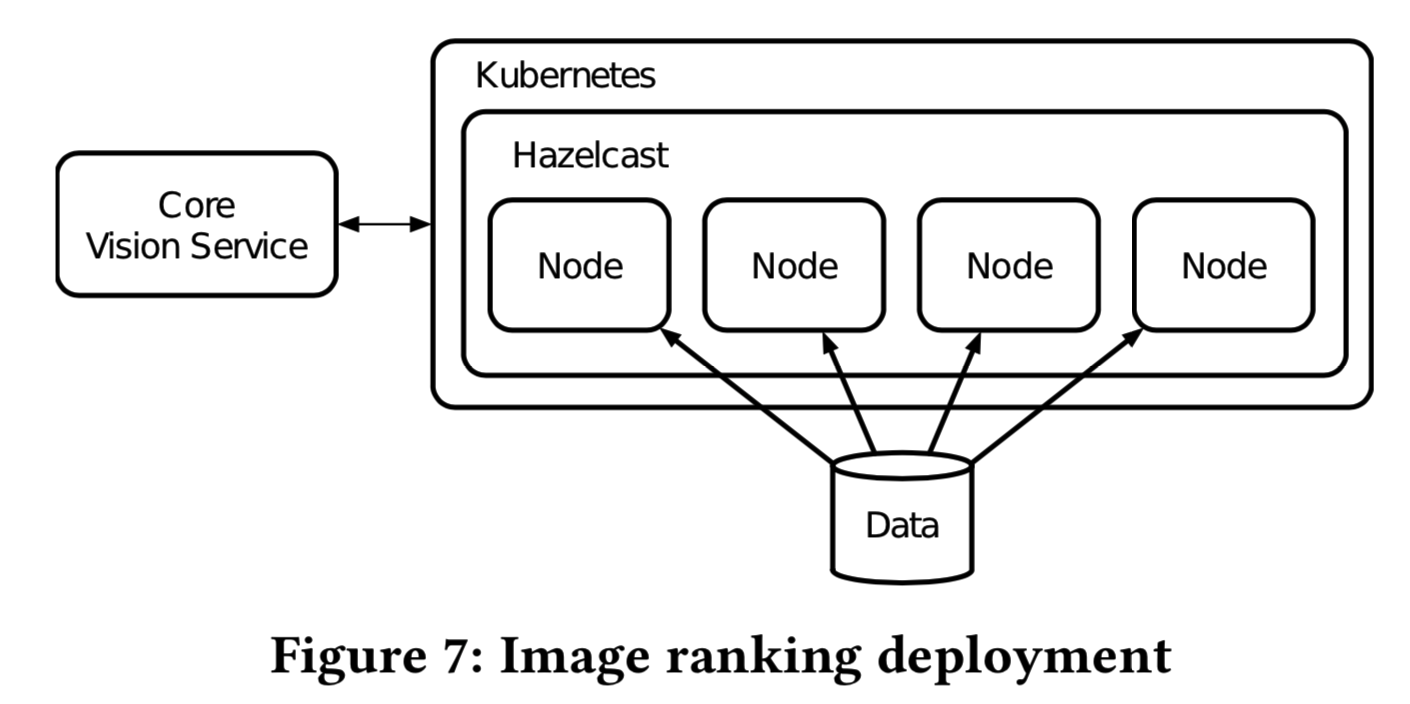
为了构建一个健壮且可扩展的解决方案,以便在受支持类别的所有项中查找类似项,我们创建了一个图像排序服务,并将其部署到Kubernetes集群中。由于数据量巨大,我们必须在包含多个节点的集群中分割所有图像的图像hashes,而不是将它们存储在一台机器上。这允许我们在任何单个节点不可用的情况下提供容错,并使根据用户流量轻松扩展成为可能。在这个场景中,应用程序的每个实例将负责数据的一个子集,但是集群将在所有数据之间共同执行搜索。由于我们的目标是提供接近线性的可扩展性,集群中的每个节点都应该了解其他节点,以便决定为哪个部分的数据提供服务。我们使用Hazelcast(一个开放源码的内存数据网格)来识别集群。
当一个节点参与Hazelcast集群时,它会收到其他节点离开或加入集群的通知。一旦应用程序启动,每个节点都会收到一个“集群更改”事件。然后,每个节点检查当前节点集。如果发生了变化,则启动数据重新分配过程。在这个过程中,我们将每个类别的数据分割成与集群中的节点数相同的分区(即每个集群都存储所有的数据,但是处理时分别处理不同分区的数据)。使用根据Hazelcast分配的ID排序的节点列表,以循环方式将每个分区分配给一个节点。开始节点由Ketama consistency hash根据节点ID确定,这样每个节点可以在整个集群中生成相同的数据分布,并识别出自己负责的部分。为了确保所有节点拥有相同的数据,我们利用Kubernetes以只读模式跨多个pods共享单个磁盘。
对于初始发现,在集群启动期间,我们使用类型为“cluster IP”的Kubernetes服务。当node执行服务的DNS解析时,它将接收关于Hazelcast集群中已经存在的所有节点的信息。每个节点还定期从DNS记录中提取关于其他节点的信息,以防止集群分离。
这种设计允许我们向外扩展到任意数量的节点,以满足不同的需求,比如支持不断增加的用户流量,通过缩小每个分区来减少搜索延迟,以及提供容错性,等等。如果在用户发送请求的确切时刻,任何单个节点变得不可用,搜索将在活动节点上执行。由于每个叶子类别的数据分布在集群中,因此可以保证服务的可用性。
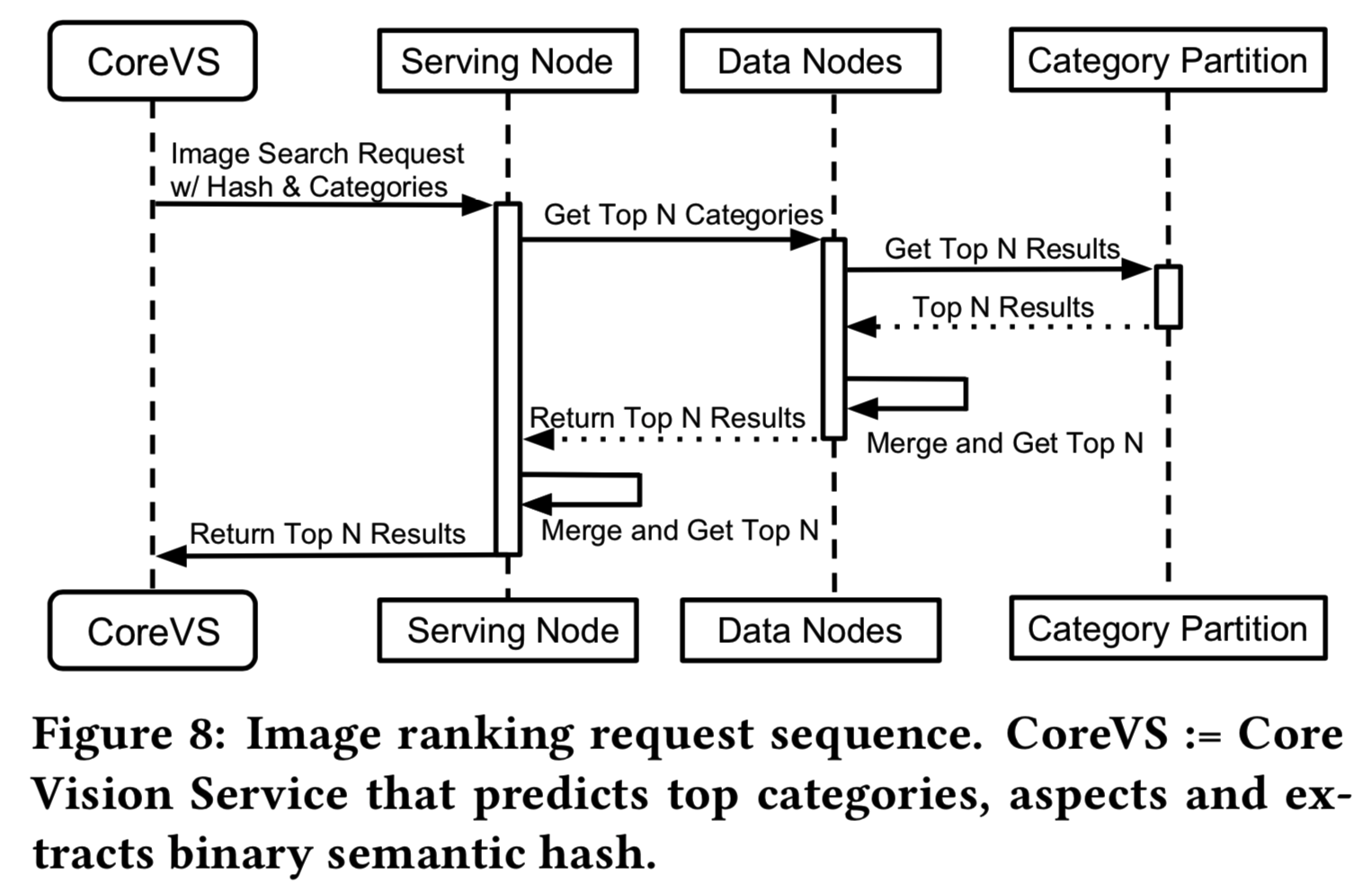
当我们的核心视觉服务(图7)向图像排序服务发送传入搜索请求时,请求可以被集群中的任何节点提供服务,称为“服务节点”。由于每个节点都知道集群的状态,所以它将传入的请求代理给包括自己在内的所有其他节点。每个节点进一步查看分配给它的分区,如果请求中有提到类别,则为该给定的图像哈希找到最近的N个listings(图8)。我们使用汉明距离作为距离度量来发现最相似的清单。每个类别的数据都表示为连续的IDs列表数组和相应的图像散列。每个节点将类别分区划分为一组具有相同数量可用CPU内核的子分区,并且并行执行搜索以查找最近的N个项。一旦请求中的搜索在每个叶子类别的每个子分区中完成,就会将结果合并,并返回最近的总N个listings结果。当所有数据节点上的搜索完成后,服务节点将执行类似的合并过程并返回结果。
5 EXPERIMENTS ON IMAGENET
在本节中,我们在ImageNet[5]数据集上进行了广泛的实验,以重复证明概念。我们采用ResNet-50[8]模型进行类别预测,并遵循3.3节中相同的学习协议,对ImageNet上新添加的散列分支进行微调。我们的分类分支(图3)的top-1验证错误为25.7%,top-5验证错误为7.9%,仅略高于哈希分支的24.7%和7.8%,这表明学习到的哈希函数和捕获到的语义内容都具有辨别能力。我们将在接下来的一系列实验中定量地确认这一点。图9演示了对来自ImageNet的5个synset的基于4096位二进制语义哈希的embedding。这从定性上加强了我们的主张,即二进制哈希保留了语义信息和局部邻域。在哈希中编码语义信息以减轻冲突的不良影响是很重要的,因为冲突中的项在语义上是相似的。

5.1 Bit Distribution
学习好的二进制哈希函数的一个关键特性是拥有平衡的bits,也就是说,强制bits平均分布在完整的数据上。给定二进制哈希的特定bits,理想情况下,它在训练集中的一半图像上激活,而在剩下的一半图像上为0。这种均衡的分布产生了有区别的bits,减少了碰撞,同时保持了信息论角度最大的熵,从而使得视觉搜索的匹配更加准确。
在图10中,我们显示了训练集中每个4096位中某个比特被激活的图像的百分比。虽然曲线不像理想情况一样完全平坦于50%,但它大多在50%左右,在45%到55%的范围内,这表明从我们的模型中获得的bits大致是均匀分布的。具体来说,4096位中的3445位(84.1%)对训练集中45%到55%的图像激活。这验证了我们的二进制语义哈希的编码效率。

5.2 Quantitative Comparison
我们进行了进一步的实验来评估我们的方法对一个流行的无监督视觉搜索的性能,并表明我们的方法在不同的评价指标方面取得了更好的检索结果。我们使用ImageNet[5]的验证组做为query集去从训练集中搜索相似图像。作为基线,我们在训练集图像的二进制hashes中执行k-means聚类(k'= 2n, n = 4, 6, 8, 10)。我们首先找到top N个最近的聚类中心,然后在每个集群内寻找M个最相似的图像,而不是直接为每个query图像预测N个类标签。这样,我们得到N×M幅初始检索图像,并返回K幅图像作为最终的搜索结果(即再重排序得到top K张)。
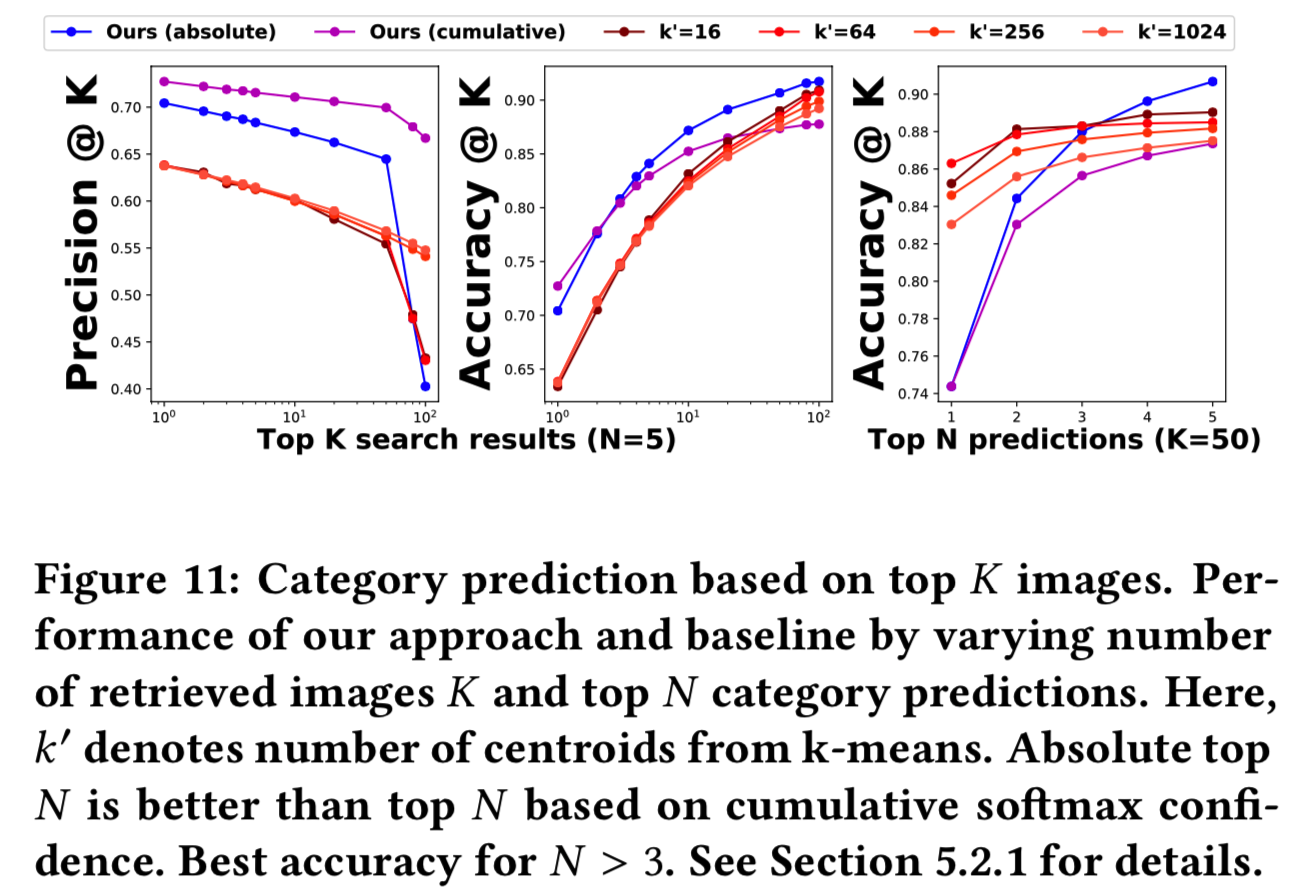
5.2.1 Category prediction.在搜索过程中使用预测类别,我们的监督方法会产生更准确的结果。我们使用precision@K和accuracy@K,通过改变top K返回结果的数量来评估基线和我们的方法的性能。这些度量测量的是相关结果的数量,即与查询图像属于同一类的结果,以及分类准确度accuracy,即如果在前K个检索结果中至少有一个返回的图像与query图像属于同一类,则认为该查询被正确分类。对于所有的实验,我们设置M = 50,这样我们在每个预测的类别中只搜索50幅相似的图像。我们有两种方法。首先是看绝对的top N个类别(即N值固定)。第二种方法是使用最大值为N的预测(即N只要不大于最大值即可,是可变动的),直到我们得到累积的softmax置信度为0.95。结果表明,前者较好。在图11中,我们的方法在K≤100时,随着K的增加,准确率accuracy迅速提高,而精度prediction只是略有下降,这清楚地表明我们的方法并没有在top搜索结果中引入很多不相关的图像。与基线的不同变体相比,仅检索20张图像时,我们能够获得更好的性能。另一方面,当我们在更多的预测类别中搜索时,准确性会显著提高,因为我们包含了更多的候选项,并且表现优于所有的基线变体。
5.2.2 Similarity search. 在相似性搜索方面,我们进一步比较了我们的方法和基线的性能,其中我们考虑了一个查询图像的确切的K个最近邻居的结果作为ground-truth,并评估比较的方法如何接近ground-truth。因此,我们使用normalized discounted cumulative gain (NDCG)来衡量排名列表的质量(相关性),并再次使用precision@K。通过考虑图像的类别信息,我们就有了另一种来评估这些方法的ground-truth,即在类别级别上查看相关性。在这两种情况下,我们的方法再次优于基线变量(参见图12)。

上面的ground-truth得到的方法是在整个数据集上查找query图像真正最近的K个邻居得到的结果;下面则是在查找的query图像相同的类别中去查找真正的最近的K个邻居得到的结果。然后用我们的方法得到的K个预测邻居结果和得到的ground-truth进行比较得到的上面的结果
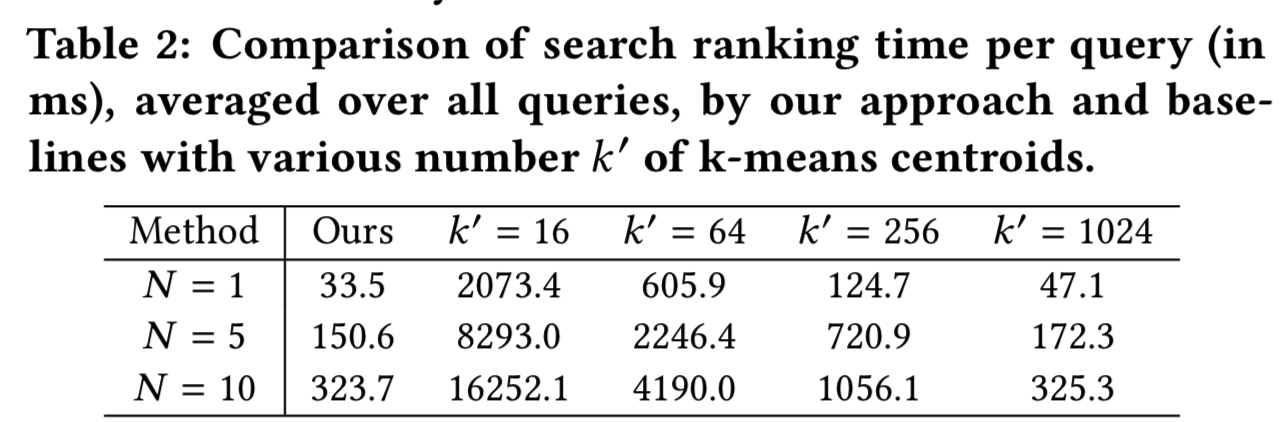
5.2.3 Timing. 我们还和基线的几种变体比较了我们的方法的速度(不包括网络转发)。我们用不同的N进行实验,即top prediction或nearest k-means centroids,结果如表2所示。我们的方法比基线方法更有效,因为我们通过只搜索前N个预测类别显著减少了搜索空间。具体地说,当N = 5时,我们的方法比大k' = 1024的基线快1.14倍,而且更准确。注意,所有实验都是在desktop上使用单线程处理的Python进行的,而生产环境(针对实时eBay库存)已经经过了广泛优化(章节4.2),以极大地减少延迟(章节6.4)。
6 APPLICATION: EBAY SHOPBOT
我们的视觉搜索最近部署在eBay ShopBot上。从那时起,视觉搜索就成为了用户购物过程中不可缺少的一部分,服务于众多的客户。人们只要上传一张照片,就能从eBay的10多亿在线交易列表中找到最划算的交易。来自ShopBot的早期用户数据显示,自推出eBay ShopBot测试版以来,以图片搜索开始的购物任务数量增加了一倍。下面,我们总结了在ShopBot中使用可视化搜索的两个主要场景。
6.1 User query
eBay ShopBot允许用户免费拍照(从相机或相册),并在eBay的大量库存中找到类似的产品。这是十分有用的,特别是当很难准确地单独使用文字描述一个产品时。我们没有对照片是如何拍摄的设置任何限制的,并支持可以进行广泛的查询,从专业的高质量图像到低质量的用户照片。图1显示了ShopBot上的用户界面示例。尽管使用的是带有背景噪声且质量低的查询图像,我们的视觉搜索页能成功地找到了准确匹配的产品。
6.2 Anchor search
eBay ShopBot中视觉搜索的第二个用例是Anchor search。每当用户看到产品列表时(即使她使用文本去初始化搜索),她可以单击任何返回产品上的“more like this”按钮,以细化或扩大初始搜索,并查找视觉上类似的项目。在这里,来自所选项目的照片作为anchor来初始化一个新的视觉搜索。由于anchor是listed的(即这个anchor不是用户上传的图片,而是网站上有的图片),我们可以利用它的元信息,比如类别和aspect,来进一步引导视觉搜索。通过这种方式,我们为用户提供了非线性的搜索和浏览体验,允许更多的灵活性和自由度。这个特性非常受用户欢迎,自从可用以来,用户参与度增加了65%。图13显示了一个示例,用户通过寻找视觉上相似的手袋来寻找灵感。

6.3 Qualitative results
由于专有信息的存在,我们不能共享eBay数据集,因此在图14中我们只给出了定性结果。我们的视觉搜索引擎成功地从eBay庞大的动态库存中发现了视觉上相似的图片,尽管类别不同,组成和照明也不同。注意,在撰写本文时,所有检索到的图像都来自eBay的active listings(即是该网站内部的图像)。

6.4 Latency
我们报告了几个主要组件的延迟。通过大量的优化和利用云计算能力,批处理哈希生成服务(batch hash generation servic)在单个GPU (Tesla K80)上每幅图像需要34ms。在ShopBot场景中,给定一个用户查询,深度网络平均花费125ms来预测类别、识别aspect和生成图像哈希。根据每个类别的大小,图像排名服务只需要25ms和70ms分别返回50和1000个条目。aspect重新排序只需要10ms就可以对多达1000个结果重新排序。因此,总的延迟只有几百毫秒,加上各种开销,这为用户提供了快速而愉快的购物体验。
7 APPLICATION: CLOSE5
Close5是ebay旗下的本地买卖平台。用户可以免费拍照,并对自己想要销售的产品进行描述,从而在Close5上创建一个列表,供附近的用户查看。我们的视觉搜索解决方案已经部署并集成了Close5本地应用程序以支持大量的Close5用户。它在以下两个场景中被广泛使用。
7.1 Auto categorization
虽然大多数listings都有用户创建的描述,但有些只有用户拍摄的照片作为标题,而描述并不是强制性的。因此,这些没有描述的listings是不能通过文本搜索的,导致比有描述的产品少200倍的销售机会。在本例中,我们的视觉搜索预测基于图像的产品的类别,以填充与类别相关的文本信息,以便用户可以使用文本搜索这些清单。早期的统计数据显示,与那些没有描述和没有自动分类listing相比,有的listing的平均浏览次数增加了21%。
7.2 Similar items on eBay
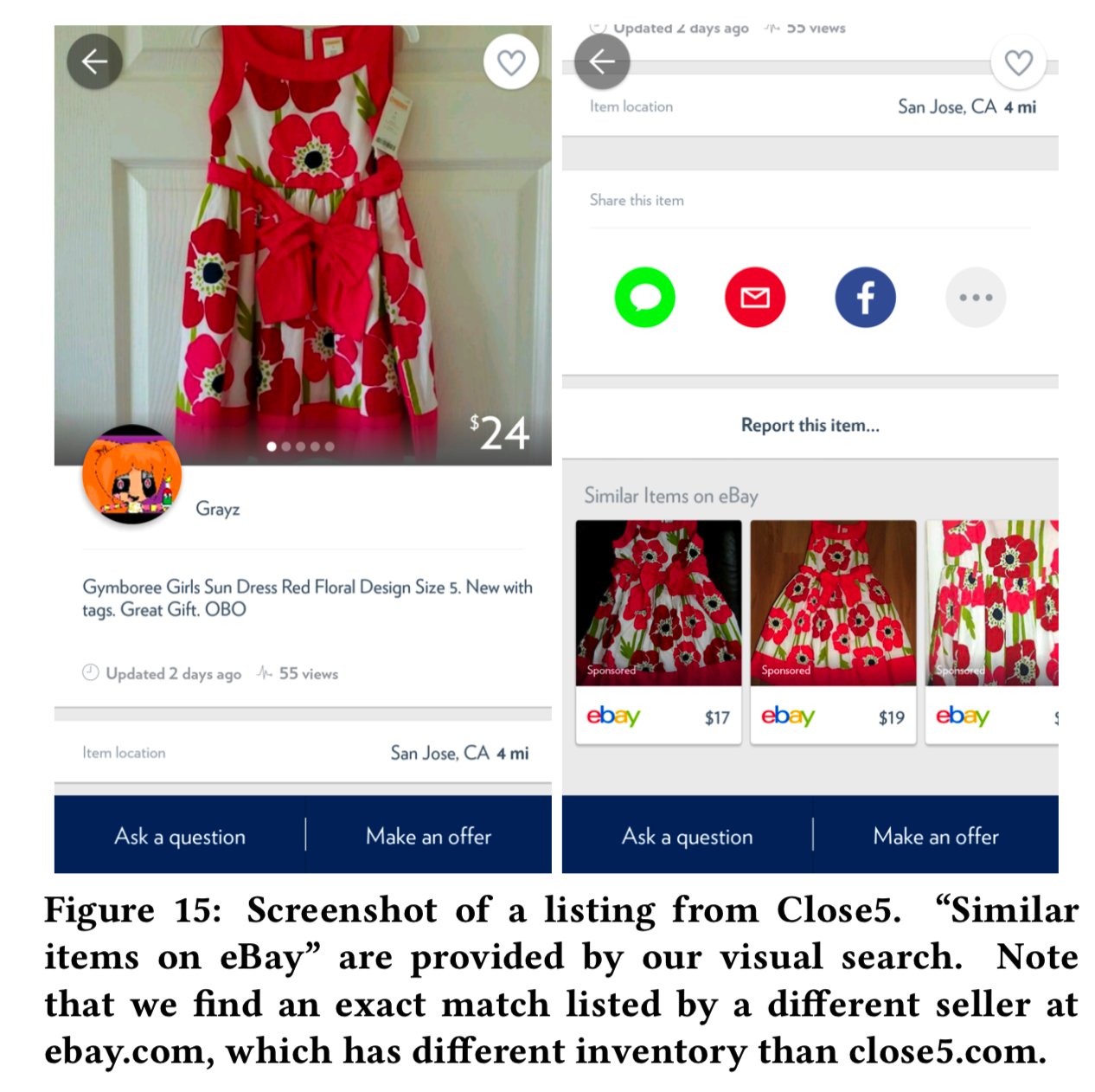
为了让Close5用户能够从eBay库存中发现产品,我们将可视化功能集成为“Similar items on ebay”功能。当用户浏览一个listing时,可视化搜索将自动触发,将来自这个Close5 listing的第一个图像作为查询。结果显示在listing页面的底部,带有指向eBay网站的链接。如图15所示,我们的视觉搜索成功地找到了同一件印花连衣裙,以及其他类似的连衣裙。有了这个特性,eBay的库存将暴露给数百万的Close5用户,这为Close5用户和eBay卖家提供了改进的购买和销售体验。自从我们推出这个用户视觉搜索后,点击率翻倍。
8 CONCLUSION
我们展示了一个可扩展的可视化搜索基础设施,它利用了深度神经网络和基于云的平台的力量来高效地发现像eBay这样庞大且不稳定的库存。重点包括仅搜索来自top预测类别的图像、带有分割拓扑的单一DNN网络去预测类别并提取紧凑且高效的二值语义哈希、基于aspect的重新排序以加强语义相似度。我们还介绍了系统架构,并讨论了几种在搜索相关性和延迟之间权衡的优化方法。在大型公共数据集上的大量实验验证了我们的学习模型的识别能力。此外,我们还展示了可视化搜索解决方案已成功部署到最近推出的eBay ShopBot中,并集成到eBay拥有的Close5本地应用程序中。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号