
pytorch torch.nn.functional实现插值和上采样
interpolate
torch.nn.functional.interpolate(input, size=None, scale_factor=None, mode='nearest', align_corners=None)
根据给定的size或scale_factor参数来对输入进行下/上采样
使用的插值算法取决于参数mode的设置
支持目前的temporal(1D, 如向量数据), spatial(2D, 如jpg、png等图像数据)和volumetric(3D, 如点云数据)类型的采样数据作为输入,输入数据的格式为minibatch x channels x [optional depth] x [optional height] x width,具体为:
- 对于一个temporal输入,期待着3D张量的输入,即minibatch x channels x width
- 对于一个空间spatial输入,期待着4D张量的输入,即minibatch x channels x height x width
- 对于体积volumetric输入,则期待着5D张量的输入,即minibatch x channels x depth x height x width
可用于重置大小的mode有:最近邻、线性(3D-only),、双线性, 双三次(bicubic,4D-only)和三线性(trilinear,5D-only)插值算法和area算法
参数:
-
input (Tensor) – 输入张量
-
size (int or Tuple[int] or Tuple[int, int] or Tuple[int, int, int]) –输出大小.
-
scale_factor (float or Tuple[float]) – 指定输出为输入的多少倍数。如果输入为tuple,其也要制定为tuple类型
-
mode (str) –
可使用的上采样算法,有'nearest','linear','bilinear','bicubic','trilinear'和'area'.默认使用'nearest' -
align_corners (bool, optional) –
几何上,我们认为输入和输出的像素是正方形,而不是点。如果设置为True,则输入和输出张量由其角像素的中心点对齐,从而保留角像素处的值。如果设置为False,则输入和输出张量由它们的角像素的角点对齐,插值使用边界外值的边值填充;当scale_factor保持不变时,使该操作独立于输入大小。仅当使用的算法为'linear','bilinear', 'bilinear'or'trilinear'时可以使用。默认设置为False
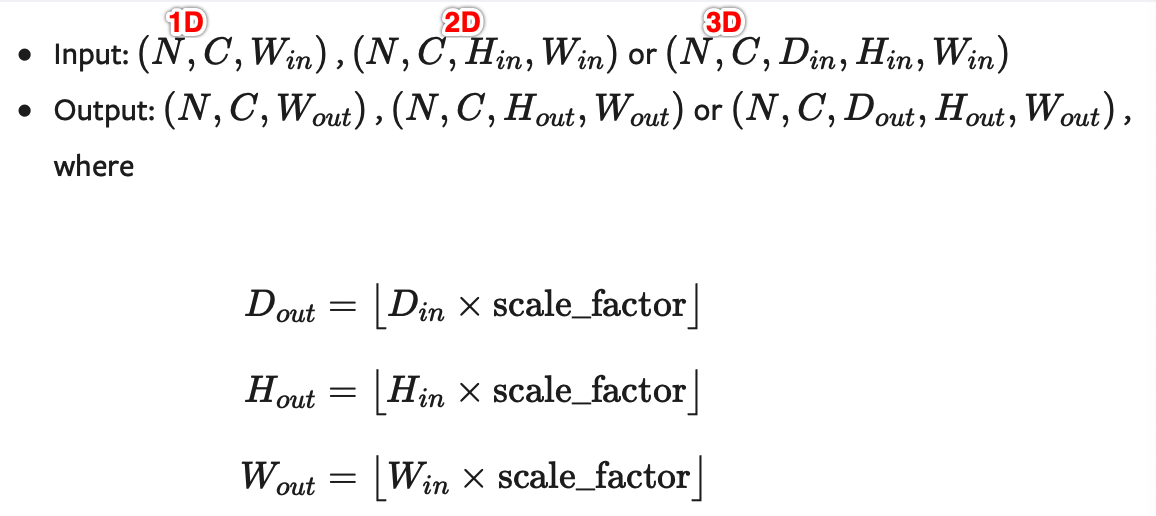
注意:
使用mode='bicubic'时,可能会导致overshoot问题,即它可以为图像生成负值或大于255的值。如果你想在显示图像时减少overshoot问题,可以显式地调用result.clamp(min=0,max=255)。
When using the CUDA backend, this operation may induce nondeterministic behaviour in be backward that is not easily switched off. Please see the notes on Reproducibility for background.
警告:
当align_corners = True时,线性插值模式(线性、双线性、双三线性和三线性)不按比例对齐输出和输入像素,因此输出值可以依赖于输入的大小。这是0.3.1版本之前这些模式的默认行为。从那时起,默认行为是align_corners = False,如下图:
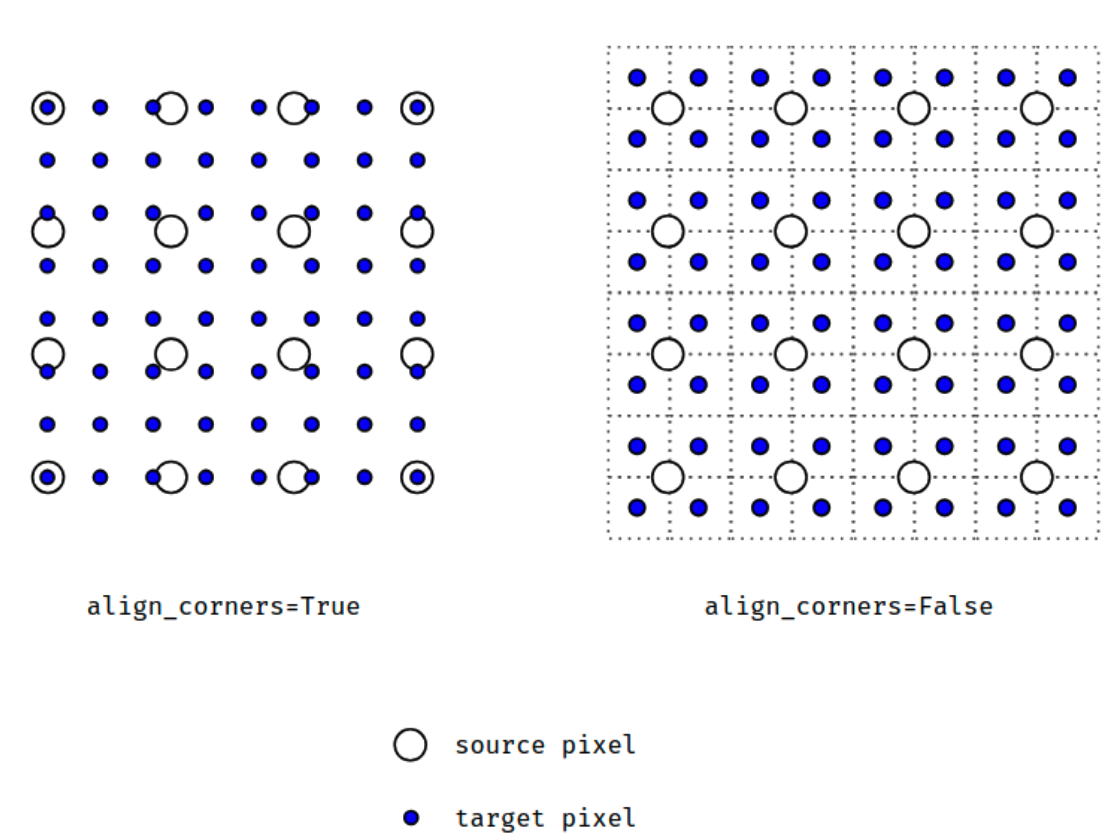
上面的图是source pixel为4*4上采样为target pixel为8*8的两种情况,这就是对齐和不对齐的差别,会对齐左上角元素,即设置为align_corners = True时输入的左上角元素是一定等于输出的左上角元素。但是有时align_corners = False时左上角元素也会相等,官网上给的例子就不太能说明两者的不同(也没有试出不同的例子,大家理解这个概念就行了)
举例:
import torch from torch import nn import torch.nn.functional as F input = torch.arange(1, 5, dtype=torch.float32).view(1, 1, 2, 2) input
返回:
tensor([[[[1., 2.], [3., 4.]]]])
x = F.interpolate(input, scale_factor=2, mode='nearest') x
返回:
tensor([[[[1., 1., 2., 2.], [1., 1., 2., 2.], [3., 3., 4., 4.], [3., 3., 4., 4.]]]])
x = F.interpolate(input, scale_factor=2, mode='bilinear', align_corners=True) x
返回:
tensor([[[[1.0000, 1.3333, 1.6667, 2.0000], [1.6667, 2.0000, 2.3333, 2.6667], [2.3333, 2.6667, 3.0000, 3.3333], [3.0000, 3.3333, 3.6667, 4.0000]]]])
也提供了一些Upsample的方法:
upsample
torch.nn.functional.upsample(input, size=None, scale_factor=None, mode='nearest', align_corners=None)
torch.nn.functional.upsample_nearest(input, size=None, scale_factor=None)
torch.nn.functional.upsample_bilinear(input, size=None, scale_factor=None)
因为这些现在都建议使用上面的interpolate方法实现,所以就不解释了
更加复杂的例子可见:pytorch 不使用转置卷积来实现上采样

 浙公网安备 33010602011771号
浙公网安备 33010602011771号