



Key-Value Memory Network
首先,基本的Memorry Network中是使用sentence(passage)来构造memory,然后计算和query的匹配程度,再根据匹配程度计算输出,用于下游任务。而Key-Value Memory Network则是使用(K,V)对来构造memory,这种构造方式是为了解决文档阅读QA任务里面对外部知识(或者称先验知识)的应用。Key-Value Memory的哈希,寻址,读取等步骤是论文的核心,也是闪光点。
Prerequisite
Deep Memory Network 深度记忆网络
Deep Memory Network在Aspect Based Sentiment方向上的应用(optional)
Key-Value Memory Networks for Directly Reading Documents
Key-Value Memory Network由facebook在2016年的一篇论文提出,它主要是为了解决QA应用知识库时,知识库可能过于受限,其储存知识的模式(schema)可能不支持某些类型的回答,而且知识库可能过于稀疏等问题。论文提出的模型不仅适用于基于KB的QA,而且适用于基于WIKI文章的QA和基于信息抽取的QA。
作者在论文中也提出了一个新的数据集Movie QA,它包含了覆盖电影领域的十万+QA,而且能进行KB,wiki文档以及IE三种知识来源为背景的QA。
KV-MemNNs的模型结构如下:

由模型图可以看出,Key-Value Memory来源于Question和Knowledge Source。
Key-Value Memory
KV-MemNNs中,memory slots定义为二元组向量 ( k 1 , v 1 , . . . , k M , v M ) (k_1,v_1,...,k_M,v_M) (k1,v1,...,kM,vM)。Memory的寻址和读取分为以下三个步骤:
- Key Hashing
- Key Addressing
- Value Reading
Key Hashing
使用一个大小为N的逆索引来寻找一个Memory的子集 ( k h 1 , v h 1 ) , . . . , ( k h N , v h N ) (k_{h_1},v_{h_1}),...,(k_{h_N},v_{h_N}) (kh1,vh1),...,(khN,vhN),其中的key以频率小于1000的程度共享至少一个word (共享word是为了保证子集的整体有效性,作者给出了这种实现思路的来源)。
Key Addressing
在寻址过程中,每一个候选memory都会使用softmax函数来分配一个相关概率:
p
h
i
=
S
o
f
t
m
a
x
(
A
Φ
X
(
x
)
⋅
A
Φ
K
(
k
h
i
)
)
p_{h_i}=Softmax(A\Phi_X(x)\cdot A\Phi_K(k_{h_i}))
phi=Softmax(AΦX(x)⋅AΦK(khi))
其中 Φ \Phi Φ是一个维度为 D D D的特征映射,A是 d × D d\times D d×D的矩阵,特征映射会在稍后详细说明。 x x x是输入的sentence。
Value Reading
最后一步使用寻址得到的概率对Memories做加权求和,得到向量
o
o
o。
o
=
∑
i
p
h
i
A
Φ
V
(
v
h
i
)
o=\sum_ip_h{_i}A\Phi_V(v_{h_i})
o=i∑phiAΦV(vhi)
记忆读取过程由控制器网络来执行,它使用 q = A Φ X ( x ) q=A\Phi_X(x) q=AΦX(x)作为query。多跳情况下,会以 q 2 = R 1 ( q + o ) q_2=R_1(q+o) q2=R1(q+o)的形式生成下一跳query, R R R是 d × d d\times d d×d的矩阵。多跳情况下会使用不同的矩阵 R j R_j Rj重复进行以上过程,但Key Hasing只做一次。上面提到的Key Addressing方程现在转化到了 p h i = S o f t m a x ( q j + 1 ⊤ A Φ K ( k h i ) ) p_{h_i}=Softmax(q_{j+1}^\top A\Phi_K(k_{h_i})) phi=Softmax(qj+1⊤AΦK(khi))。
这样做的目的是不断将新的证据组合进查询中,以聚焦于新证据并抽取更恰当的内容。
在
H
H
H跳之后,使用argmax来计算出一个可能输出的最终预测:
a
^
=
a
r
g
m
a
x
i
=
1
,
.
.
.
,
C
S
o
f
t
m
a
x
(
q
H
+
1
⊤
B
Φ
Y
(
y
i
)
)
\hat{a}=argmax_{i=1,...,C}Softmax(q_{H+1}^\top B\Phi_Y(y_i))
a^=argmaxi=1,...,CSoftmax(qH+1⊤BΦY(yi))
其中
y
i
y_i
yi是可能的输出候选,比如KB里面的所有实体。矩阵
B
B
B可以限制为与矩阵
A
A
A相同。整个网络以端到端的形式训练,以最小化交叉熵的形式迭代存取以输出想要地
a
a
a。
注意:如果把key和value设置成对所有的memory都相同,模型就退化到了标准的端到端Memory Network。标准的端到端Memory Network也不会使用哈希,但是memory size非常的大时候使用哈希能降低计算复杂度,证明见这里。
Feature Map
作者在论文中列举了5种feature map的实现方式,这也算是5种Key-Value Memory的实现方式。这些实现方式对于模型的整体效果还是有重大影响的。因为编码先验知识的能力是KV-MemNNs的重要组成部分。
Φ X \Phi_X ΦX(query)和 Φ Y \Phi_Y ΦY(answer)简单定义为bag-of-words表示。 Φ K \Phi_K ΦK和 Φ V \Phi_V ΦV有以下五种定义方式:
-
KB Triple
在知识库的结构化三元组(subject, relation, object)中,将subject和relation作为key,object作为value。作者也将三元组中的subject和object取反,这样得到了两倍大小的知识库。 -
Sentence Level
将整个文档拆分成句子,每一个memory slot编码一个句子,key和value都以bag-of-words的形式编码整个句子。因为key和value相同,所以这与标准的MemNN相同。 -
Window Level
将整个文档拆分成大小为 W W W个word的窗口,对每个窗口使用bag-of-words表示。这种表示在MemNN表现良好。但是在这里,作者将key定义为整个窗口,而value仅仅是窗口的中心词。作者认为整个窗口和问题(key)更为匹配,而中心词和答案(value)更为匹配。 -
Window + Center Encoding
和上面不同,该种方式混合了中心词的表示。将整个字典大小翻倍,用第二个字典编码窗口的中心词和value。这种方式将可以帮助模型分辨更与中心词(answer)相关还是更与其他词(question)相关。 -
Window + Title
一个文档的title通常和其包含文本中的一个问题相关。基于这个理由,作者设计了这种表示。Word Window和之前一样,但value定义为文本的title。作者也保留了windows-level的(window,center)key-value对表示
。注意,这样的话memory slot的大小就加倍了。为了分辨不同values来源的keys,作者在key前面加上了额外特征"_window_“和”_title_"。
五种表示的实验区别如下:

扩展
Key Value Memory Network并没有得到广泛应用,我认为可能是整体模型的计算复杂度还是太高了。为了应用外部知识而将整个KB或者WIKI文档库放到memory中,即使采用哈希来降低计算复杂度但代价仍然很高,在实际中可能不是很好的实现方法。如果能解决这个问题,我想也是一个非常大改进。
DBLP上一共可以搜到12篇与Key-Value Memory Network相关的内容。它的另外一个主要应用方向是Knowledge tracing。
在主要应用方向上,NAACL-HLT (1) 2019有一篇题为Enhancing Key-Value Memory Neural Networks for Knowledge Based Question Answering的论文(腾讯与清华联合)。该论文将KV-MemNNs由基于知识库的浅层推理推广到针对复杂问题的可打断推理,即KBQA。论文提出了mask和一种Stop机制来避免重复阅读memory引入错误的标记信号,以实现多跳推理。作者在实验中证明了这些机制可以使得传统的KV-MemNNs在复杂问题上获得更好的推理能力,并能够达到stat-of-the-art。
Enhancing Key-Value Memory Neural Networks for Knowledge Based Question Answering
模型的基本架构和前面的介绍相同,但计算步骤有些区别,下面会详细介绍不同的地方。作者在论文里给出一个较为简洁的模型图描述KV-MemNNs:

作者在论文中提出的模型如下:

Stop机制
Stop机制非常简单,就是在key加入一个特殊的符号表示全零向量。Stop key被设计用于告诉模型已经积累了足够的事实来回答问题,不需要再增加跳数去memory中寻找更多事实了。
Query 更新
使用以下方式更新query:
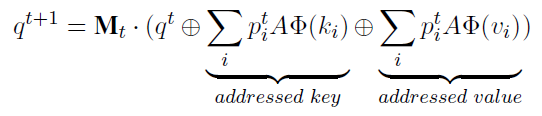
其中
⊕
\oplus
⊕表示concatenate,
M
t
M_t
Mt在第t跳的参数矩阵,参数矩阵被应用于学习一个合适的方式组合公式中的三项。
Mask机制
论文提出的训练模型的loss为:
L
(
θ
)
=
∑
x
∑
h
=
1
H
t
x
l
o
g
a
x
h
+
λ
∥
θ
∥
2
L(\theta)=\sum_x\sum_{h=1}^Ht_xloga_x^h+\lambda \| \theta \|^2
L(θ)=x∑h=1∑Htxlogaxh+λ∥θ∥2
其中 t x t_x tx表示目标分布, a x h a_x^h axh表示a跳之后的分布,即cross entropy + 正则项。loss函数能鼓励模型生成更短地到达answers的路径,并且鼓励query更新方法mask掉先前跳数已经寻址到的信息。这样设计的loss函数在加上stop key和query update的方式,实现了作者所称的STOP策略。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号