

【Pythoin爬虫】使用网页copy xpath的坑==>tbody定位不到
1:使用浏览器XPATH获取的路径:/html/body/div[6]/div[2]/div/table[2]/tbody/tr
但是用requests库爬取的时候它是空的
解答:
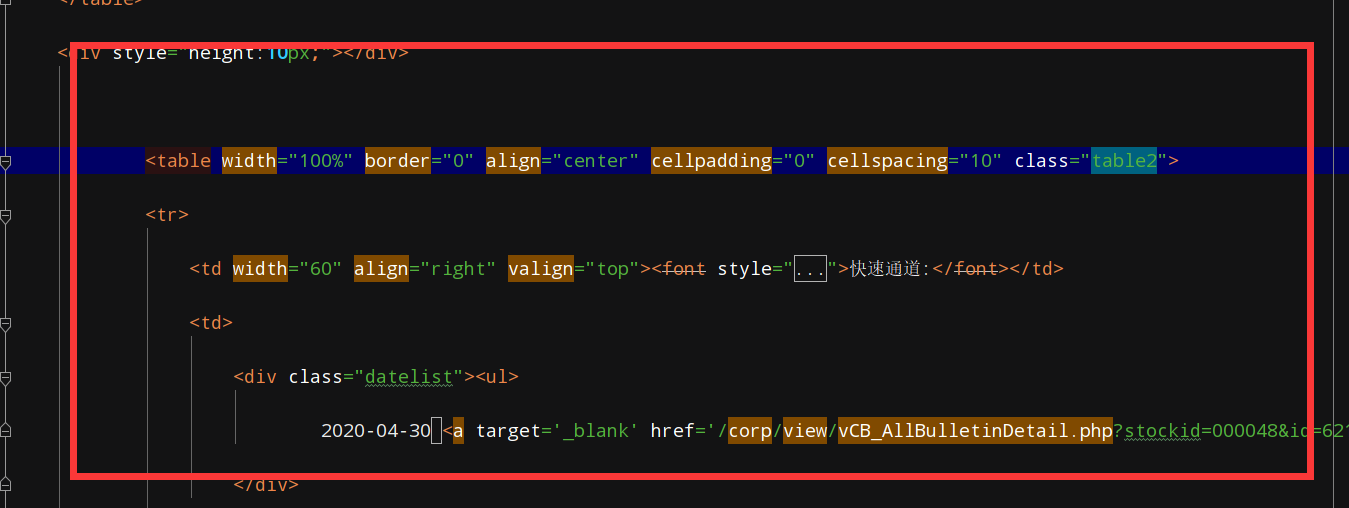
这是我打印出来的爬取源码与浏览器的源码做比较:
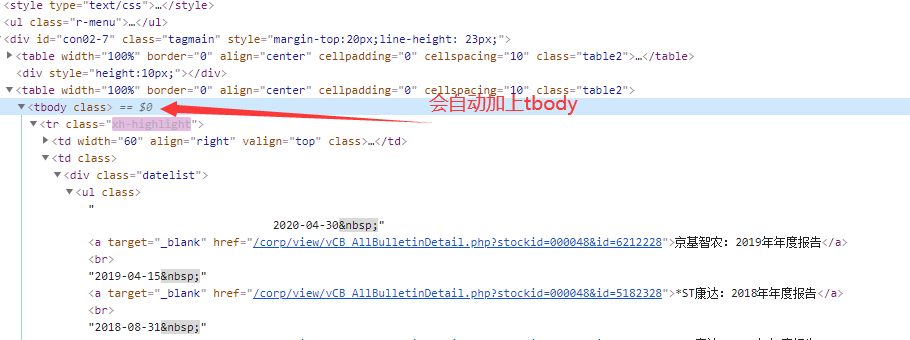
结论:在写xpath路径的时候 直接去掉tbody就可以了 : /html/body/div[6]/div[2]/div/table[2]/tr
Python全栈(后端、数据分析、脚本、爬虫、EXE客户端) / 前端(WEB,移动,H5) / Linux / SpringBoot / 机器学习

 浙公网安备 33010602011771号
浙公网安备 33010602011771号