【go语言基础】-数据操作
一. 数组
1. 特征
静态语言的数组特征:
1.大小确定
2.类型一致
只能取值,修改值
由于数组长度固定,在Go里很少直接使用
2. 定义
// 3种方式,声明,初始,省略号
// 变量arr1类型为[5]int
var arr1 [5]int
// 变量arr2类型为[3]int,同时初始化赋值
var arr2 [5]int = [5]int{1,2,3}
// 让编译器自己数,结果为[3]int
arr3 := [...]int{1,2,3}
// 错误例子,因为[3]int和[4]int是两种类型
arr3 := [4]int{1,2,3,4}- 数组长度是数组类型的一部分,
[3]int和[5]int就是两种类型。 - 数组长度必须是常量表达式,即这个表达式的值在编译阶段就可以确定。
package main
import (
"fmt"
)
func printArray(toPrint [5]string) {
//[]string这是切片类型
toPrint[0] = "bobby"
fmt.Println(toPrint)
}
func main() {
//go语言中的数组和python的list可以对应起来理解,slice和python的list更像
//静态语言中的数组: 1. 大小确定 2. 类型一致
//数组的申明
//var courses [10] string
//var courses = [5]string{"django", "scrapy", "tornado"}
course := [5]string{"django", "scrapy", "tornado"}
//静态语言要求严格, 动态语言是一门动态类型的
//1. 修改值, 取值: 删除值, 添加某一个值, 数组一开始就要指定大小
//取值, 修改值
fmt.Println(course[0])
//修改值
course[0] = "django3"
fmt.Println(course)
//数组的另一种创建方式
//var a [4] float32
var a = [4]float32{1.0}
fmt.Println(a)
var c = [5] int{'A', 'B'}
fmt.Println(c)
//首次接触到了省略号
d := [...]int{1,2,3,4,5}
fmt.Println(d)
e := [5]int{4:100}
fmt.Println(e)
f := [...]int{0:1, 4:1, 9:100}
fmt.Println(f)
//数组操作第一种场景: 求长度
fmt.Println(len(f))
//数组操作第二种场景: 遍历数组
for i, value := range course {
fmt.Println(i, value)
}
//使用for range求和
sum := 0
for _, value := range f {
sum += value
}
fmt.Println(sum)
//使用for语句也可以遍历数组
sum = 0
for i := 0; i<len(course); i++{
sum += f[i]
}
fmt.Println(sum)
//数组是值类型
courseA := [3]string{"django", "scrapy", "tornado"}
courseB := [...]string{"django1", "scrapy1", "tornado1", "python+go", "asyncio"}
//courseA和courseB应该是同一种类型, 都是数组类型
//在go语言中,courseA和courseB都是数组,但是不是同一种类型
fmt.Printf("%T\n", courseA)
fmt.Printf("%T\n", courseB)
//如果courseA和courseB是一种类型的话 为什么前面要加一个数组, 长度不一样的数组类型是不一样
//正是基于这些,在go语言中函数传递参数的时候,数组作为参数 实际调用的时候是值传递
printArray(courseB)
fmt.Println(courseB)
}3. 操作
1. 长度
arr1 := [...]{1,2,3}
lenth := len(arr1)2. 遍历
package main
import "fmt"
func main() {
f := [...]int{0: 1, 9: 100}
for i, v := range f {
fmt.Println(i, v)
}
// 使用for range求和
sum := 0
for _, v := range f {
sum += v
}
fmt.Println(sum)
// 使用for语句也可以遍历数组
sum2 := 0
for i := 0; i < len(f); i++ {
sum2 += f[i]
}
fmt.Println(sum2)
}4. 数组类型
courseA := [3]string{"a", "b", "c"}
courseB := [...]string{"a1", "b1", "c1", "d1"}
//在go语言中,courseA和courseB都是数组,但是不是同一种类型package main
import "fmt"
func main() {
courseA := [3]string{"a", "b", "c"}
courseB := [...]string{"a1", "b1", "c1", "d1"}
// 在go语言中,courseA和courseB都是数组,但是不是同一种类型
fmt.Printf("%T\n", courseA)
fmt.Printf("%T\n", courseB)
//[3]string
//[4]string
} 5. 数组值传递
package main
import (
"fmt"
)
func printArray(toPrint [5]string) {
//[]string这是切片类型
toPrint[0] = "bobby"
fmt.Println(toPrint)
}
func main() {//数组是值类型
courseA := [3]string{"django", "scrapy", "tornado"}
courseB := [...]string{"django1", "scrapy1", "tornado1", "python+go", "asyncio"}
//courseA和courseB应该是同一种类型, 都是数组类型
//在go语言中,courseA和courseB都是数组,但是不是同一种类型
fmt.Printf("%T\n", courseA)
fmt.Printf("%T\n", courseB)
//如果courseA和courseB是一种类型的话 为什么前面要加一个数组, 长度不一样的数组类型是不一样
//正是基于这些,在go语言中函数传递参数的时候,数组作为参数 实际调用的时候是值传递
printArray(courseB)
fmt.Println(courseB)
}
二. 切片
1. 含义
Go 数组的长度不可改变,在特定场景中这样的集合就不太适用,Go中提供了一种灵活,功能强悍的内置类型切片("动态数组"),与数组相比切片的长度是不固定的,可以追加元素,在追加时可能使切片的容量增大
Go的切片类型为处理同类型数据序列提供一个方便而高效的方式。 切片有些类似于其他语言中的数组,但是有一些不同寻常的特性。
2. 定义
package main
import "fmt"
func main() {
//1切片初始化第一种
var name = []string{"a", "b", "c"}
fmt.Println(name)
fmt.Printf("%T", name) // []string
//2.切片初始化另一种 make
courses := make([]string, 5)
fmt.Printf("%T", courses) // []string
fmt.Println(len(courses)) //5
// 3. 通过数组变成一个切片
var course1 = [5]string{"a", "b", "c", "d", "f"}
subCourse := course1[1:4] //切片
fmt.Printf("%T", subCourse) // []string
//python中的用法叫切片,go语言中的切片是一种数据结构
// 4. 使用new
subCourse1 := *new([]int)
fmt.Println(subCourse1)
}
//数组的传递是值传递,切片是引用传递,会改变原值
// slice对标的是python 的lIst3. 操作
package main
import "fmt"
func main() {
// slice的操作
// 1.对数据进行取值
var course1 = [5]string{ "a" , "b" , "c" , "d" , "f" }
subCourse := course1[1:4] //切片
subCourse2 := subCourse[1:2]
fmt.Printf( "%T, %v\n" , subCourse, subCourse) // []string, [b c d]
fmt.Printf( "%T, %v\n" , subCourse2, subCourse2) // []string, [b c d]
//2.增加值append
var name = []string{ "a" , "b" , "c" }
name = append(name, "e" )
fmt.Printf( "%T, %v\n" , name, name) // []string, [b c d]
//3.append增加多个参数
name = append(name, "g" , "i" , "p" )
fmt.Printf( "%T, %v\n" , name, name) // []string, [b c d]
//4.拷贝copy
var subCourse3 = []string{ "a" , "b" , "c" }
subCourse3 = append(subCourse3, "e" )
fmt.Printf( "%T, %v\n" , subCourse3, subCourse3) // []string, [b c d]
//拷贝的时候,目标对象长度需要设置好,要不然可能拷贝的不完整
//subCourse4 := make([]string, 2)
subCourse4 := make([]string, len(subCourse3))
copy(subCourse4, subCourse3)
fmt.Println(subCourse4)
//5.合并
appendCourse := []string{ "a" , "b" , "c" }
var subCourse10 = []string{ "e" , "f" , "g" }
subCourse10 = append(subCourse10, appendCourse...) //使用...是函数传递规则决定的
fmt.Println(subCourse10)
//6.删除
deleteCourse := [5]string{ "a" , "b" , "c" , "d" , "f" }
courseSlice := deleteCourse[:] //变成切片
courseSlice = append(courseSlice[:1], courseSlice[2:]...) //取巧做法,但是实际就是这么做
fmt.Println(courseSlice)
// 这样可以把B删除
}
//数组的传递是值传递,切片是引用传递,会改变原值
// slice对标的是python 的lIst4. 扩容机制
append 函数的参数长度可变,因此可以追加多个值到 slice 中,还可以用 ... 传入 slice,直接追加一个切片。
append函数返回值是一个新的slice,Go编译器不允许调用了 append 函数后不使用返回值。
使用 append 可以向 slice 追加元素,实际上是往底层数组添加元素。但是底层数组的长度是固定的,如果索引 len-1 所指向的元素已经是底层数组的最后一个元素,就没法再添加了。
这时,slice 会迁移到新的内存位置,新底层数组的长度也会增加,这样就可以放置新增的元素。同时,为了应对未来可能再次发生的 append 操作,新的底层数组的长度,也就是新 slice 的容量是留了一定的 buffer 的。否则,每次添加元素的时候,都会发生迁移,成本太高。
5. 原理
1. 扩容策略
首先判断,如果新申请容量(cap)大于2倍的旧容量(old.cap),最终容量(newcap)就是新申请的容量(cap)否则判断,如果旧切片的长度小于1024,则最终容量(newcap)就是旧容量(old.cap)的两倍,即(newcap=doublecap)
否则判断,如果旧切片长度大于等于1024,则最终容量(newcap)从旧容量(old.cap)开始循环增加原来的 1/4,即(newcap=old.cap,for {newcap += newcap/4})直到最终容量(newcap)大于等于新申请的容量(cap),即(newcap >= cap)
如果最终容量(cap)计算值溢出,则最终容量(cap)就是新申请容量(cap)
也就是说
如果小于1024 扩容的速度是2倍 如果大于了1024 扩容的速度就是1.25
规则如下:
// 预估规则:
if oldCap * 2 < newCap
直接分配内存
else
if oldLen < 1024 newCap = oldCap * 2
if oldLen > 1024 newCap = oldCap *1.25扩容后, 内存地址会指向新的内存地址,所以当append后之后, 修改原来的切片就没有关系了
a := make([]int, 0)
b := []int{1, 2, 3}
c := b[:]
c = append(c, 9)
fmt.Println(b) //append函数没有影响到原来的数组
fmt.Println(c)
//这就是因为产生了扩容机制,扩容机制一旦产生 这个时候切片就会指向新的内存地址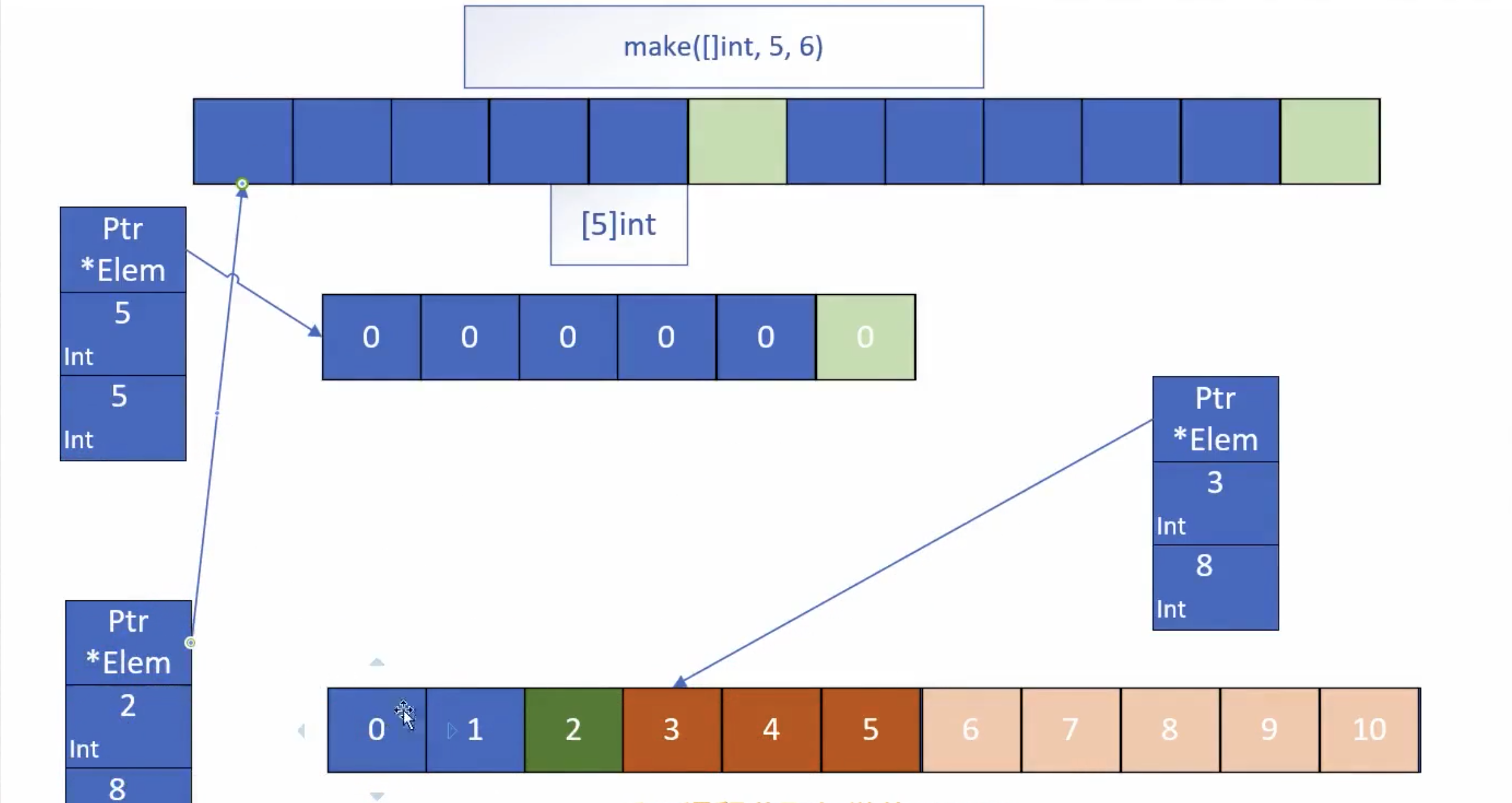
2. len和cap分配规则
make:
使用make方法初始化 len和cap是多少. 不会有多余的预留空间,两个值一致
通过数组切片:
data := [10]int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
slice := data[2:4]
for index, value := range slice {
fmt.Println(index, value)
}len为2, cap为8,会把2后面所有的值都归为cap, cap会将能拿到的数据,都归纳进来

通过此方式
slice2 := []int{1, 2, 3}
fmt.Printf("len=%d, cap=%d\n", len(slice2), cap(slice2))
// 输出cap:3, len:3代码测试
package main
import "fmt"
func replace(mySlice []string) {
mySlice[0] = "bobby"
}
func main() {
//1. 使用make方法初始化 len和cap是多少. 不会有多余的预留空间
d := make([]int, 0)
fmt.Printf("len=%d, cap=%d\n", len(d), cap(d))
//2. 通过数组取切片
data := [10]int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
slice := data[2:4]
newSlice := data[3:6]
for index, value := range slice {
fmt.Println(index, value)
}
fmt.Printf("len=%d, cap=%d\n", len(slice), cap(slice))
fmt.Printf("len=%d, cap=%d\n", len(newSlice), cap(newSlice))
//3.
slice2 := []int{1, 2, 3}
fmt.Printf("len=%d, cap=%d\n", len(slice2), cap(slice2))
//切片扩容问题, 扩容阶段会影响速度, python的list中底层实际上也是数组,也会面临动态扩容的问题,python的list中数据类型可以不一致
oldSlice := make([]int, 0)
fmt.Printf("len=%d, cap=%d\n", len(oldSlice), cap(oldSlice))
oldSlice = append(oldSlice, 1)
fmt.Printf("len=%d, cap=%d\n", len(oldSlice), cap(oldSlice))
oldSlice = append(oldSlice, 2)
fmt.Printf("len=%d, cap=%d\n", len(oldSlice), cap(oldSlice))
oldSlice = append(oldSlice, 3)
fmt.Printf("len=%d, cap=%d\n", len(oldSlice), cap(oldSlice))
oldSlice = append(oldSlice, 4)
oldSlice = append(oldSlice, 5)
oldSlice = append(oldSlice, 4)
oldSlice = append(oldSlice, 5)
oldSlice = append(oldSlice, 4)
oldSlice = append(oldSlice, 5)
fmt.Printf("len=%d, cap=%d\n", len(oldSlice), cap(oldSlice))
/*
Go 中切片扩容的策略是这样的:
首先判断,如果新申请容量(cap)大于2倍的旧容量(old.cap),最终容量(newcap)就是新申请的容量(cap)
否则判断,如果旧切片的长度小于1024,则最终容量(newcap)就是旧容量(old.cap)的两倍,即(newcap=doublecap)
否则判断,如果旧切片长度大于等于1024,则最终容量(newcap)从旧容量(old.cap)开始循环增加原来的 1/4,即(newcap=old.cap,for {newcap += newcap/4})直到最终容量(newcap)大于等于新申请的容量(cap),即(newcap >= cap)
如果最终容量(cap)计算值溢出,则最终容量(cap)就是新申请容量(cap)
*/
//如果小于1024 扩容的速度是2倍 如果大于了1024 扩容的速度就是1.25
//切片来说 1. 底层是数组,如果是基于数组产生的 会有一个问题就是会影响原来的数组。
//2. 切片的扩容机制
//3. 切片的传递是引用传递
oldArr := [3]int{1, 2, 3}
newArr := oldArr
newArr[0] = 5
fmt.Println(newArr, oldArr)
oldSlice = []int{1, 2, 3}
newSlice = oldSlice
newSlice[0] = 5
fmt.Println(oldSlice)
//go语言中slice的原理讲解很重要,这个有坑(对于初学者),有经验的程序员觉得这个不是坑
//程序员也是消费者-java c++ go -静态语言是站在对处理器的角度考虑, python - 才会站在使用者的角度上去考虑,对于处理器就不友好
//当make遇到了append容易出现的坑
s1 := make([]int, 0)
s1 = append(s1, 6)
//对于很多初学者来说我们期望的是只有一个数字就是6
fmt.Println(s1)
//很多人对make函数产生了一个假象 ,s1 := make([]int, 5) 好比是python的 s1 = []
}
三. Map
1. 操作及声明
package main
import "fmt"
func main() {
//go中的map ->python中的dict
//go语言中的map的key和value类型申明的就要指明
//1. 字面值
m1 := map[string]string{
"m1": "v1",
}
fmt.Printf("%v\n", m1)
//2. make函数 make函数可以创建slice 可以创建map
m2 := make(map[string]string) //创建时,里面不添加元素
m2["m2"] = "v2"
fmt.Printf("%v\n", m2)
//3. 定义一个空的map
m3 := map[string]string{}
fmt.Printf("%v\n", m3)
//map中的key 不是所有的类型都支持,改类型需要支持 == 或者 != 操作
//int rune
//a := []int{1,2,3}
//b := []int{1,2,3}
//var m1 map[[]int]string
//a := [3]int{1,2,3}
//b := [3]int{1,2,3}
//if a == b {
//
//}
//map的基本
m := map[string]string{
"a": "va",
"b": "vb",
"d":"",
}
//1. 进行增加,修改
m["c"] = "vc"
m["b"] = "vb1"
fmt.Printf("%v\n", m)
//查询,你返回空的字符串到底是没有获取到还是值本身就是这样空字符串呢
v, ok := m["d"]
if ok {
fmt.Println("找到了", v)
}else{
fmt.Println("没找到")
}
fmt.Println(v, ok)
//删除
//delete(m, "a")
//delete(m, "e")
//delete(m, "a")
//fmt.Printf("%v", m)
//遍历
for k, v := range m {
fmt.Println(k, v)
}
//go语言中也有一个list 就是数据结构中提到的链表
//指针 //为什么指针在java python等很多语言中不存在
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号