perf 说明
perf 是 Linux 内核提供的性能分析工具,支持硬件性能计数器、动态追踪、静态探针等功能。
perf 安装
yum -y install perf
perf 基础用法
perf [全局选项] <子命令> [子命令选项] [参数]
核心子命令分类
性能分析与采样
| 子命令 |
功能 |
record |
记录系统或进程的性能事件到 perf.data 文件。 |
report |
解析 perf.data,生成性能分析报告(如函数级 CPU 热点)。 |
top |
实时监控系统性能,按 CPU 使用率排序(类似 top 命令的动态视图)。 |
stat |
执行命令并统计硬件事件(如 CPU 周期、缓存命中率、分支预测错误等)。 |
annotate |
对 perf.data 中的代码进行注解,显示热点代码的汇编或源码级耗时。 |
数据文件处理
| 子命令 |
功能 |
script |
将 perf.data 转换为可读的文本格式(如调用栈追踪)。 |
evlist |
列出 perf.data 中记录的性能事件类型。 |
archive |
打包记录性能数据时依赖的二进制文件(用于跨机器分析)。 |
diff |
对比两个 perf.data 文件的性能差异。 |
内核相关工具
| 子命令 |
功能 |
kmem |
分析内核内存分配事件(如 slab 分配器、页面错误)。 |
kvm |
监控虚拟化环境(KVM)的性能事件。 |
sched |
分析调度器行为(如进程切换延迟、运行队列状态)。 |
probe |
动态添加内核或用户空间的追踪点(动态追踪)。 |
trace |
类似 strace,跟踪系统调用和内核事件。 |
锁与内存分析
| 子命令 |
功能 |
lock |
分析锁事件(如争用、等待时间)。 |
c2c |
检测共享数据缓存行的争用(Cache-to-Cache/HITM 分析)。 |
mem |
分析内存访问模式(如加载/存储延迟)。 |
动态追踪与调试
| 子命令 |
功能 |
ftrace |
内核 ftrace 功能的简单封装(需 root 权限)。 |
kallsyms |
读取内核符号表,用于定位内核函数。 |
buildid-list |
列出 perf.data 中记录的构建 ID(用于符号解析)。 |
常用命令示例
perf list
perf list 用于列出当前系统支持的 硬件性能事件、软件事件和跟踪点。
# perf list
List of pre-defined events (to be used in -e):
branch-instructions OR branches [Hardware event]
branch-misses [Hardware event]
bus-cycles [Hardware event]
cache-misses [Hardware event]
cache-references [Hardware event]
cpu-cycles OR cycles [Hardware event]
instructions [Hardware event]
ref-cycles [Hardware event]
alignment-faults [Software event]
bpf-output [Software event]
context-switches OR cs [Software event]
cpu-clock [Software event]
cpu-migrations OR migrations [Software event]
dummy [Software event]
emulation-faults [Software event]
major-faults [Software event]
minor-faults [Software event]
page-faults OR faults [Software event]
task-clock [Software event]
L1-dcache-load-misses [Hardware cache event]
L1-dcache-loads [Hardware cache event]
L1-dcache-stores [Hardware cache event]
L1-icache-load-misses [Hardware cache event]
LLC-load-misses [Hardware cache event]
LLC-loads [Hardware cache event]
LLC-store-misses [Hardware cache event]
LLC-stores [Hardware cache event]
branch-load-misses [Hardware cache event]
branch-loads [Hardware cache event]
dTLB-load-misses [Hardware cache event]
dTLB-loads [Hardware cache event]
dTLB-store-misses [Hardware cache event]
dTLB-stores [Hardware cache event]
iTLB-load-misses [Hardware cache event]
iTLB-loads [Hardware cache event]
node-load-misses [Hardware cache event]
node-loads [Hardware cache event]
node-store-misses [Hardware cache event]
node-stores [Hardware cache event]
branch-instructions OR cpu/branch-instructions/ [Kernel PMU event]
branch-misses OR cpu/branch-misses/ [Kernel PMU event]
bus-cycles OR cpu/bus-cycles/ [Kernel PMU event]
cache-misses OR cpu/cache-misses/ [Kernel PMU event]
cache-references OR cpu/cache-references/ [Kernel PMU event]
cpu-cycles OR cpu/cpu-cycles/ [Kernel PMU event]
cstate_core/c3-residency/ [Kernel PMU event]
cstate_core/c6-residency/ [Kernel PMU event]
cstate_core/c7-residency/ [Kernel PMU event]
cstate_pkg/c2-residency/ [Kernel PMU event]
cstate_pkg/c3-residency/ [Kernel PMU event]
cstate_pkg/c6-residency/ [Kernel PMU event]
cstate_pkg/c7-residency/ [Kernel PMU event]
instructions OR cpu/instructions/ [Kernel PMU event]
mem-loads OR cpu/mem-loads/ [Kernel PMU event]
mem-stores OR cpu/mem-stores/ [Kernel PMU event]
msr/aperf/ [Kernel PMU event]
msr/cpu_thermal_margin/ [Kernel PMU event]
msr/mperf/ [Kernel PMU event]
msr/smi/ [Kernel PMU event]
msr/tsc/ [Kernel PMU event]
power/energy-cores/ [Kernel PMU event]
power/energy-pkg/ [Kernel PMU event]
power/energy-ram/ [Kernel PMU event]
ref-cycles OR cpu/ref-cycles/ [Kernel PMU event]
topdown-fetch-bubbles OR cpu/topdown-fetch-bubbles/ [Kernel PMU event]
topdown-recovery-bubbles OR cpu/topdown-recovery-bubbles/ [Kernel PMU event]
topdown-slots-issued OR cpu/topdown-slots-issued/ [Kernel PMU event]
topdown-slots-retired OR cpu/topdown-slots-retired/ [Kernel PMU event]
topdown-total-slots OR cpu/topdown-total-slots/ [Kernel PMU event]
uncore_imc_0/cas_count_read/ [Kernel PMU event]
uncore_imc_0/cas_count_write/ [Kernel PMU event]
uncore_imc_0/clockticks/ [Kernel PMU event]
uncore_imc_1/cas_count_read/ [Kernel PMU event]
uncore_imc_1/cas_count_write/ [Kernel PMU event]
uncore_imc_1/clockticks/ [Kernel PMU event]
uncore_imc_2/cas_count_read/ [Kernel PMU event]
uncore_imc_2/cas_count_write/ [Kernel PMU event]
uncore_imc_2/clockticks/ [Kernel PMU event]
uncore_imc_3/cas_count_read/ [Kernel PMU event]
uncore_imc_3/cas_count_write/ [Kernel PMU event]
uncore_imc_3/clockticks/ [Kernel PMU event]
uncore_imc_4/cas_count_read/ [Kernel PMU event]
uncore_imc_4/cas_count_write/ [Kernel PMU event]
uncore_imc_4/clockticks/ [Kernel PMU event]
| 类别 |
说明 |
| Hardware events |
硬件性能计数器(如 CPU 周期、缓存命中率),依赖 CPU PMU(性能监控单元)支持。 |
| Software events |
内核模拟的软件事件(如上下文切换、缺页中断),无需硬件支持。 |
| Tracepoint events |
内核静态跟踪点(如调度、文件系统、网络事件),需内核启用 CONFIG_TRACEPOINTS。 |
| Raw PMU events |
直接访问 CPU PMU 寄存器的原始事件(格式如 r003c,需参考 CPU 手册)。 |
Hardware Cache Events
|
与 CPU 缓存和 TLB 相关的硬件事件,用于分析缓存效率。 |
Kernel PMU Events
|
与 内核性能监控单元 相关的事件,用于高级硬件行为分析。 |
示例
# 查看所有调度相关事件
perf list 'sched:*'
# 查看指定模块的事件(如网络)
perf list 'net:*'
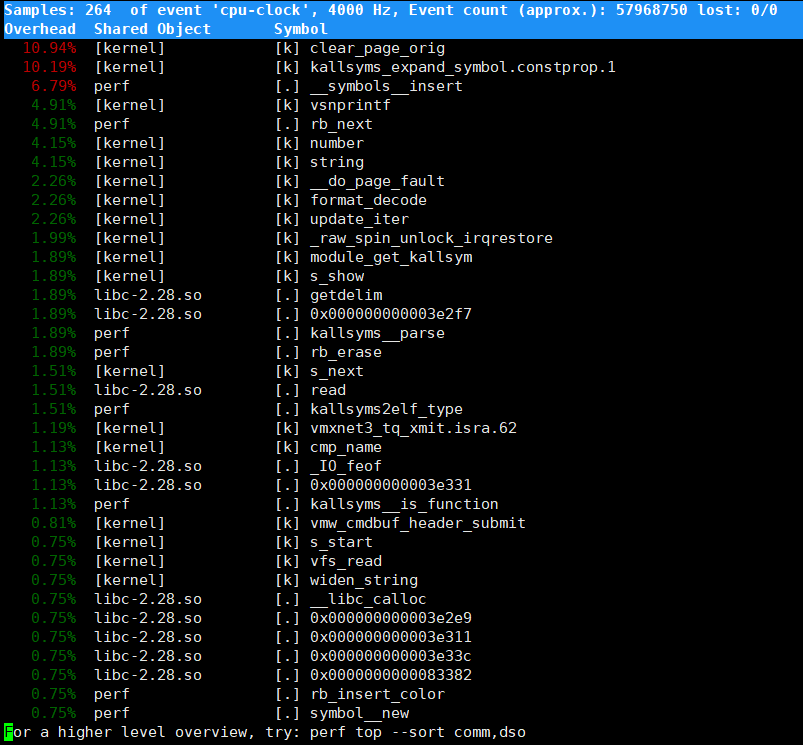
perf top
功能:实时性能监控。动态显示系统中 CPU 占用最高的函数。
| 参数 |
说明 |
-e <事件> |
指定监控的事件(默认 cycles) |
-K |
隐藏内核空间函数(仅显示用户空间函数) |
-U |
隐藏用户空间函数(仅显示内核空间函数) |
-p <PID> |
监控指定进程 |
示例
perf top
perf stat
功能:性能计数器统计。测量命令执行的硬件/软件事件(如 CPU 周期、缓存命中率)。
| 参数 |
说明 |
-a / --all-cpus |
监控所有 CPU 的性能事件(系统全局视角) |
-p <PID> |
监控指定进程的 PID |
-e <事件> |
指定监控的事件(如 cycles、cache-misses,多个事件用逗号分隔) |
-r <次数> |
重复运行命令并统计平均值(如 -r 5 运行 5 次) |
-d |
显示更详细的事件(包括 L1/L2 缓存、分支预测等) |
示例
perf stat -a -r 3 sleep 5 # 全局统计 5 秒,重复 3 次
Performance counter stats for 'system wide' (3 runs):
20,008.53 msec cpu-clock # 3.999 CPUs utilized ( +- 0.00% )
859 context-switches # 0.043 K/sec ( +- 2.85% )
9 cpu-migrations # 0.000 K/sec ( +- 10.18% )
46 page-faults # 0.002 K/sec ( +- 33.75% )
<not supported> cycles
<not supported> instructions
<not supported> branches
<not supported> branch-misses
5.002999 +- 0.000198 seconds time elapsed ( +- 0.00% )
perf stat -e L1-dcache-load-misses,L1-dcache-loads -p 1033 sleep 5 # 分析 CPU 缓存命中率
0 L1-dcache-load-misses # 0.00% of all L1-dcache hits
0 L1-dcache-loads # 在 5 秒监控期间,未发生任何 L1 数据缓存的加载操作
5.001182415 seconds time elapsed
perf record
功能:记录性能数据。将性能数据保存到 perf.data 文件(后续可用 perf report 分析)。
| 参数 |
说明 |
-g |
记录调用图(用于生成火焰图) |
-F <频率> |
设置采样频率(如 -F 99 表示每秒采样 99 次) |
-e <事件> |
指定监控的事件(默认 cycles) |
-p <PID> |
监控指定进程 |
--call-graph <方法> |
指定调用图记录方法(dwarf、fp 等) |
示例
perf record -g -F 99 -p 5678 # 记录 PID=5678 的调用图,每秒 99 次采样
[ perf record: Woken up 1 times to write data ]
[ perf record: Captured and wrote 0.023 MB perf.data (3 samples) ]
perf report
功能:分析记录的数据。交互式查看 perf.data 的分析结果。
| 参数 |
说明 |
-n |
显示样本数量(而不仅是百分比) |
--stdio |
以非交互式文本模式输出(适合脚本处理) |
-g <类型> |
设置调用图显示方式(如 graph、fractal) |
-s <字段> |
按指定字段排序(如 pid、comm、symbol) |
示例
perf report -n --stdio # 文本模式显示样本数量
# To display the perf.data header info, please use --header/--header-only options.
#
#
# Total Lost Samples: 0
#
# Samples: 3 of event 'cpu-clock'
# Event count (approx.): 30303030
#
# Children Self Samples Command Shared Object Symbol
# ........ ........ ............ ............. ................. ........................................
#
66.67% 0.00% 0 vmselect-prod vmselect-prod [.] runtime.goexit.abi0
|
---runtime.goexit.abi0
|
|--33.33%--net.(*netFD).connect.func2
| runtime.selectgo
| runtime.gopark
| runtime.mcall
| runtime.park_m
| runtime.schedule
| runtime.findRunnable
| runtime.netpollBreak
| runtime.write1.abi0
| entry_SYSCALL_64_after_hwframe
| do_syscall_64
| ksys_write
| vfs_write
| __vfs_write
| eventfd_write
|
--33.33%--runtime.gcBgMarkStartWorkers.gowrap1
runtime.gcBgMarkWorker
runtime.systemstack.abi0
runtime.gcBgMarkWorker.func2
runtime.gcDrain
runtime.scanobject
perf report -s symbol # 按函数名排序
Samples: 3 of event 'cpu-clock', Event count (approx.): 30303030
Children Self Symbol
+ 66.67% 0.00% [.] runtime.goexit.abi0
+ 66.67% 0.00% [k] entry_SYSCALL_64_after_hwframe
+ 66.67% 0.00% [k] do_syscall_64
+ 33.33% 33.33% [k] _raw_spin_lock
+ 33.33% 33.33% [k] eventfd_write
+ 33.33% 33.33% [.] runtime.scanobject
+ 33.33% 0.00% [.] net.(*netFD).connect.func2
+ 33.33% 0.00% [.] runtime.selectgo
+ 33.33% 0.00% [.] runtime.gopark
+ 33.33% 0.00% [.] runtime.mcall
+ 33.33% 0.00% [.] runtime.park_m
+ 33.33% 0.00% [.] runtime.schedule
+ 33.33% 0.00% [.] runtime.findRunnable
+ 33.33% 0.00% [.] runtime.netpollBreak
+ 33.33% 0.00% [.] runtime.write1.abi0
+ 33.33% 0.00% [k] __vfs_write
+ 33.33% 0.00% [.] runtime.notetsleep
+ 33.33% 0.00% [.] runtime.notetsleep_internal
+ 33.33% 0.00% [k] __x64_sys_futex
+ 33.33% 0.00% [k] do_futex
+ 33.33% 0.00% [k] futex_wait
+ 33.33% 0.00% [k] ksys_write
+ 33.33% 0.00% [.] runtime.futex.abi0
+ 33.33% 0.00% [.] runtime.gcBgMarkStartWorkers.gowrap1
+ 33.33% 0.00% [.] runtime.gcBgMarkWorker
+ 33.33% 0.00% [.] runtime.systemstack.abi0
+ 33.33% 0.00% [.] runtime.gcBgMarkWorker.func2
+ 33.33% 0.00% [.] runtime.gcDrain
+ 33.33% 0.00% [k] 0xcccccccccccccccc
+ 33.33% 0.00% [.] runtime.mstart.abi0
+ 33.33% 0.00% [.] runtime.mstart0
+ 33.33% 0.00% [.] runtime.mstart1
+ 33.33% 0.00% [.] runtime.sysmon
+ 33.33% 0.00% [k] vfs_write
Tip: System-wide collection from all CPUs: perf record -a
perf script
功能:导出原始数据。将 perf.data 转换为文本格式(适用于生成火焰图或自定义分析)。
| 参数 |
说明 |
-G |
生成调用图数据(与 perf script -g 配合使用) |
--fields |
指定输出字段(如 pid,tid,time,event) |
示例
perf script > out.stack # 导出调用栈数据
perf script --fields comm,pid,tid,time,event # 自定义输出字段
vmselect-prod 1033/1509 758.603214: cpu-clock:
vmselect-prod 1033/1042 786.601098: cpu-clock:
vmselect-prod 1033/1043 818.590253: cpu-clock:
perf probe
功能:动态跟踪点管理。动态添加内核或用户空间的跟踪点。
| 参数 |
说明 |
--add <函数> |
添加跟踪点(如 --add tcp_sendmsg) |
--del <函数> |
删除跟踪点 |
-x <二进制> |
指定用户空间二进制文件(用于跟踪用户态函数) |
示例
perf probe --add 'vfs_read file=+0(%dx):string' # 跟踪 vfs_read 的文件名参数
perf probe --add libc:malloc # 跟踪 libc 库的 malloc 函数
perf trace
功能:系统调用跟踪。类似 strace,跟踪进程的系统调用和信号。
| 参数 |
说明 |
-p <PID> |
跟踪指定进程 |
-e <事件> |
过滤特定系统调用(如 -e open,read) |
-s |
显示系统调用的堆栈跟踪 |
示例
perf trace -e open,read -p 1033 # 跟踪 PID=1033 的 open 和 read 调用
0.000 ( 0.021 ms): vmselect-prod/1803 read(fd: 4<anon_inode:[eventfd]>, buf: 0x7f3e9c7b67f8, count: 8 ) = 8
856.081 ( 0.020 ms): vmselect-prod/1803 read(fd: 4<anon_inode:[eventfd]>, buf: 0x7f3e9c7b67f8, count: 8 ) = 8
1001.796 ( 0.019 ms): vmselect-prod/1803 read(fd: 4<anon_inode:[eventfd]>, buf: 0x7f3e9c7b67f8, count: 8 ) = 8
1268.412 ( 0.018 ms): vmselect-prod/1803 read(fd: 4<anon_inode:[eventfd]>, buf: 0x7f3e9c7b67f8, count: 8 ) = 8
1534.355 ( 0.018 ms): vmselect-prod/1803 read(fd: 4<anon_inode:[eventfd]>, buf: 0x7f3e9c7b6840, count: 8 ) = 8
1856.247 ( 0.018 ms): vmselect-prod/1803 read(fd: 4<anon_inode:[eventfd]>, buf: 0x7f3e9c7b67f8, count: 8 ) = 8
2720.391 ( 0.018 ms): vmselect-prod/1803 read(fd: 4<anon_inode:[eventfd]>, buf: 0x7f3e9c7b67f8, count: 8 ) = 8
2856.190 ( 0.019 ms): vmselect-prod/1803 read(fd: 4<anon_inode:[eventfd]>, buf: 0x7f3e9c7b67f8, count: 8 ) = 8

 浙公网安备 33010602011771号
浙公网安备 33010602011771号