
目标检测之R-CNN系列
Object Detection,在给定的图像中,找到目标图像的位置,并标注出来。 或者是,图像中有那些目标,目标的位置在那。这个目标,是限定在数据集中包含的目标种类,比如数据集中有两种目标:狗,猫。 就在图像找出来猫,狗的位置,并标注出来 是狗还是猫。
这就涉及到两个问题:
- 目标识别,识别出来目标是猫还是狗,Image Classification解决了图像的识别问题。
- 定位,找出来猫狗的位置。
R-CNN
2012年AlexNet在ImageNet举办的ILSVRC中大放异彩,R-CNN作者受此启发,尝试将AlexNet在图像分类上的能力迁移到PASCAL VOC的目标检测上。这就要解决两个问题:
- 如何利用卷积网络去目标定位
- 如何在小规模的数据集上训练出较好的网络模型。
对于问题,R-CNN利用候选区域的方法(Region Proposal),这也是该网络被称为R-CNN的原因:Regions with CNN features。对于小规模数据集的问题,R-CNN使用了微调的方法,利用AlexNet在ImageNet上预训练好的模型。
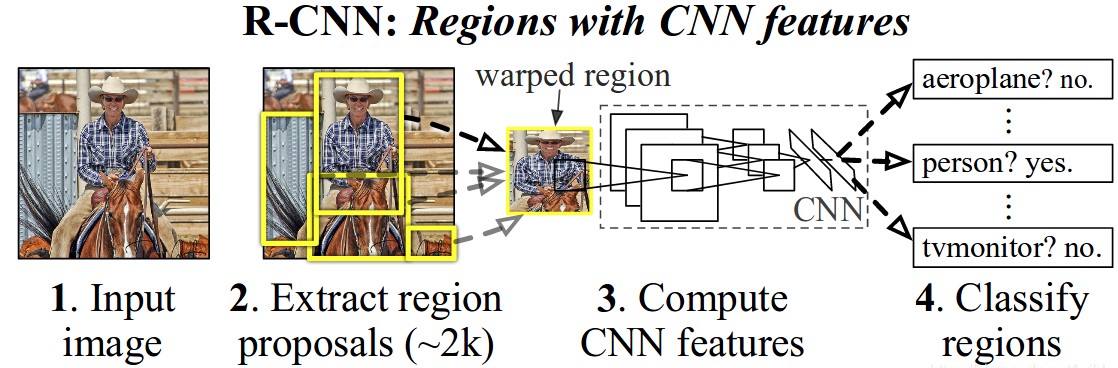
R-CNN目标检测的思路:
- 给定一张图片,从图片中选出2000个独立的候选区域(Region Proposal)
- 将每个候选区域输入到预训练好的AlexNet中,提取一个固定长度(4096)的特征向量
- 对每个目标(类别)训练一SVM分类器,识别该区域是否包含目标
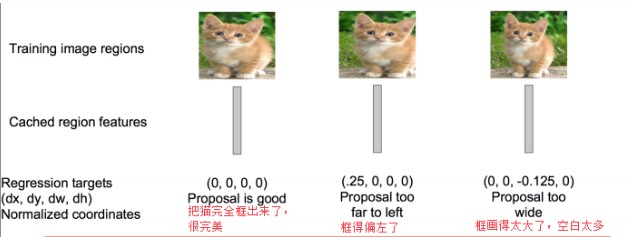
- 训练一个回归器,修正候选区域中目标的位置:对于每个类,训练一个线性回归模型判断当前框是不是很完美。
下图给出了,R-CNN的目标检测过程
训练
R-CNN进行目标检测的训练流程:
- 使用区域生成算法,生成2000个候选区域,这里使用的是Selective search.
- 对生成的2000个候选区域,使用预训练好的AlexNet网络进行特征提取。
- 将候选区域变换到网络需要的尺寸(\(227 \times 227\))。 在进行变换的时候,在每个区域的边缘添加\(p\)个像素,也就是手工的添加个边框,设置\(p = 16\)。
- 改造预训练好的AlexNet网络,将其最后的全连接层去掉,并将类别设置为21(20个类别,另外一个类别代表背景).
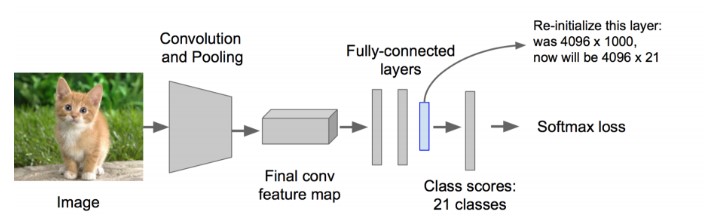
这样一个候选区域输入到网络中,最终得到一个\(4096 \times 21\)的特征。
- 利用上面提取到的候选区域的特征,对每个类别训练一个SVM分类器(而分类)来判断,候选框里物体的类别,是给类别就是positive,不是就是negative。比如,下图针对狗的SVM分类器
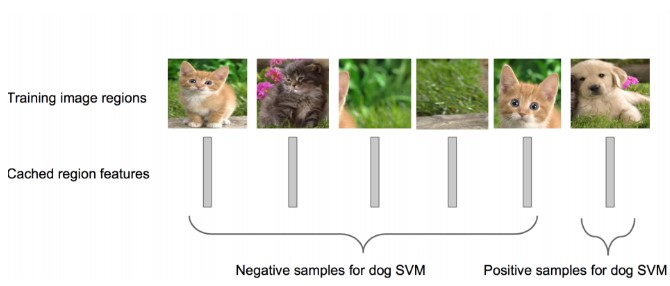
狗的SVM分类器,就要能判断出某个候选区域是不是包含狗,包含狗了那就是Positive;不包含就是Negative.这里有个问题是,假如候选区域只是框出来了某个类的一部分,那要怎么来标注这个区域呢。在R-CNN中,设定一个IOU的阈值,如果该区域与Ground truth的IOU低于该阈值,就将给区域设置为Negative。阈值设置为0.3。 - 对于面只是得到了每个候选框是不是包含某个目标,其得到的区域位置不是很准确。这里需要再训练一个线性回归模型判断,候选区域框出的目标是不是完美。对于某个类别的SVM是Positive的候选区域,来判断其框的目标区域是不是很完美。
测试
从一张图片中提取2000个候选区域,将每个区域按照训练时候的方式进行处理,输入到SVM中进行正负样本的识别,并使用候选框回归器,计算出每个候选区域的分数。
候选区域较多,有2000个,所有很多重叠的部分,就需要剔除掉重叠的部分。
针对每个类,通过计算IOU,采取非最大值抑制的方法,以最高分的区域为基础,删掉重叠的区域。
缺点
- 训练分为多个步骤,比较繁琐。 需要微调CNN网络提取特征,训练SVM进行正负样本分类,训练边框回归器得到正确的预测位置。
- 训练耗时,中间要保持候选区域的特征,5000张的图片会生成几百G的特征文件。
- 速度慢
- SVM分类器和边框回归器的训练过程,和CNN提取特征的过程是分开的,并不能进行特征的学些更新。
Fast R-CNN
R-CNN虽然取得了不错的成绩,但是其缺点也很明显。Ross Girshick在15年推出Fast RCNN,构思精巧,流程更为紧凑,大幅提升了目标检测的速度。同样使用最大规模的网络,Fast RCNN和RCNN相比,训练时间从84小时减少为9.5小时,测试时间从47秒减少为0.32秒。在PASCAL VOC 2007上的准确率相差不大约在66%-67%之间。
Fast RCNN主要是解决RCNN的问题的
- 测试训练速度慢,主要是提取候选区域的特征慢
R-CNN首先从测试图中提取2000个候选区域,然后将这2000个候选区域分别输入到预训练好的CNN中提取特征。由于候选区域有大量的重叠,这种提取特征的方法,就会重复的计算重叠区域的特征。在Fast-RCNN中,将整张图输入到CNN中提取特征,在邻接时在映射到每一个候选区域,这样只需要在末尾的少数层单独的处理每个候选框。 - 训练需要额外的空间保存提取到的特征信息
RCNN中需要将提取到的特征保存下来,用于为每个类训练单独的SVM分类器和边框回归器。在Fast-RCNN中,将类别判断和边框回归统一的使用CNN实现,不需要在额外的存储特征。
Fast R-CNN的结构
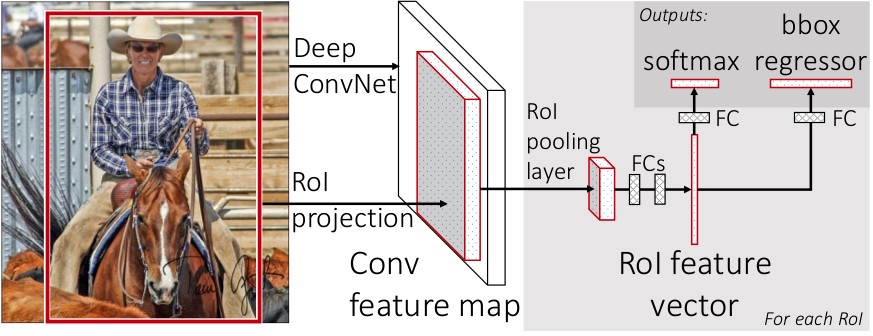
输入是整幅图像和多个感兴趣区域(ROI)的位置信息,在前面的网络层中并不会处理ROI信息,在后面的RoI pooling layer中,将每个RoI池化到固定大小的特征图中,然后通过全连接层提取特征。最后通过将提取的每个RoI特征输入到SoftMax分类器已经边框回归器中,完成目标定位的端到端的训练。
Fast R-CNN网络将整个图像和一组候选框作为输入。网络首先使用几个卷积层(conv)和最大池化层来处理整个图像,以产生卷积特征图。然后,对于每个候选框,RoI池化层从特征图中提取固定长度的特征向量。每个特征向量被送入一系列全连接(fc)层中,其最终分支成两个同级输出层 :一个输出个类别加上1个背景类别的Softmax概率估计,另一个为个类别的每一个类别输出四个实数值。每组4个值表示个类别的一个类别的检测框位置的修正。
ROI 池化层
ROI池化层前面的网络层是对整幅图像提取特征得到多个Feature Map。ROI池化层的输入就是这多个Feature Map以及多个ROI(候选区域),这里的ROI是一个矩形框,由其左上角的坐标以及宽高组成的四元组\((r,c,h,w)\)定义。
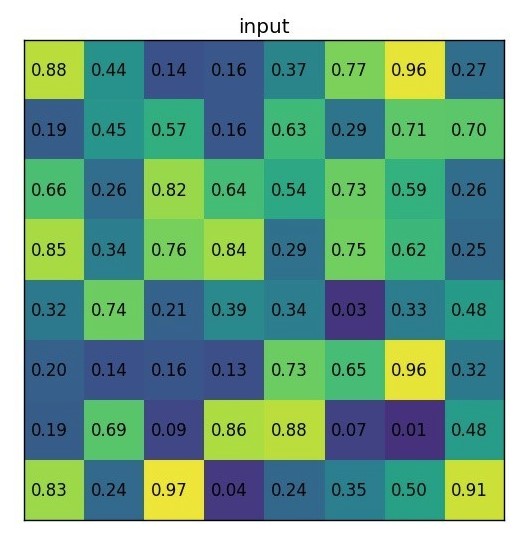
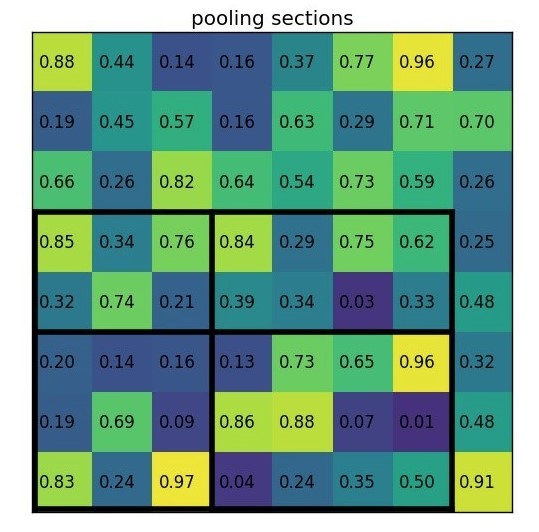
ROI池化层使用最大池化将输入的Feature Map中的任意区域(ROI对应的区域)内的特征转化为固定的\(H \times W\)的特征图,其中\(H\)和\(W\)是超参数。 对于任意输入的\(h \times w\)的ROI,将其分割为\(H \times W\)的子网格,每个子网格的大小为\(\frac{h}{H} \times \frac{w}{W}\)。如下,取得\(2\times 2\)的特征图
- 输入的Feature Map
- ROI投影到Feature Map上的左上角的坐标为\((0,3)\),宽高为\((7,5)\),在Feature Map上位置如下
- 对每个子网格做最大池化操作
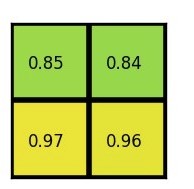
ROI池化层的池化操作同标准的池化操作是一样的,每个通道都单独执行。
预训练网络
通过ROI池化层可以从整幅图像的特征图中得到每个ROI的特征图(固定大小),而整幅图像的特征图则使用预训练的网络提取得到。对于预训练完成的网络要做如下的修改:
- 使用ROI池化层代替预训练网络的最后的池化层,并将超参\(H,W\)设置为和网络第一个全连接兼容的值,例如VGG16,设\(H = W = 7\)。
- 原网络的最后一个全连接层替换为两个同级层:\(K + 1\)个类别的SoftMax分类层和类别的边框回归层。
- 网络的输入修改为两个:图像的列表以及相对应的ROI的列表
训练微调
R-CNN中的特征提取和检测部分是分开进行的,使用检测样本进行训练的时候无法更新特征提取部分的参数。SPPnet也不能更新金字塔层前面的卷积层权重,这是因为当批量训练的样本来自不同的图片时,,反向传播通过SPP层时十分低效。Fast R-CNN则可以使用反向传播的方法更新整个网络的参数。
Fast R-CNN提出一个高效的训练方法,可以在训练过程中发挥特征共享的优势。在Fast R-CNN训练过程中随机梯度下降(SGD)的mini-batch是分层采样的,首先取\(N\)张图像,然后从每张图片采样\(\frac{R}{N}\)个RoI。来自同一张图片的RoI在前向和后向传播中共享计算和内存。这样就可以减少mini-batch的计算量。例如\(N=2,R=128\),这个训练模式大概比从128个不同的图像采样1个RoI(这就是R-CNN和SPPnet的训练方式)要快64倍。
该策略一个问题是会导致收敛起来比较慢,因为来自同一张图片的RoI是相关的。但它在实际中并没有成为一个问题,我们的使用\(N=2,R=128\)达到了很好的成绩,只用了比R-CNN还少的SGD迭代。
Multi-task Loss
Fast R-CNN有两种输出:
- 分类的Softmax输出,对于每个RoI输出一个概率,\(p = {p_0,p_1,\dots,p_k}\),\(k + 1\)个类,包括一个背景类别。
- 边框回归:\(t^k = (t_x^k,t_y^k,t_w^k,t_h^k)\)。 其中,\(k\)类别的索引,\(t_x^k,t_y^k\)是相对于候选区域尺度不变的平移,\(t_w^k,t_h^k\)相对于候选区域对数空间的位移。
将上面的两个任务的需要色损失函数放在一起
其中,\(L_{cls}(p,u)\)是分类的损失函数,\(p_u\)是class u的真实分类的概率。这里,约定\(u = 0\)表示背景,不参与边框回归的损失计算。
\(L_{Ioc}(t^u,v)\)是边框回归的损失函数,
其中,\(u\)表示类别,\(t^u\)表示预测边框的偏移量(也就是预测边框进行\(t^u\)偏移后,能够和真实边框最接近),\(v\)表示预测边框和实际边框之间真正的偏移量
这里\(smooth_{L_1}(x)\)中的\(x\)为真实值和预测值坐标对应值的差值,该函数在\((-1,1)\)之间为二次函数,在其他位置为线性函数,Fast RCNN作者表示作者表示这种形式可以增强模型对异常数据的鲁棒性。其函数曲线如下图
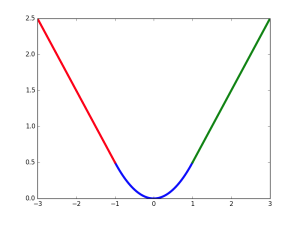
关于边框的修正后面单独详述。
Truncated SVD for faster detection
在进行目标检测时,需要处理的RoI的个数较多,几乎一半的时间花费在全连接层的计算上。就Fast R-CNN而言,RoI池化层后的全连接层需要进行约2k次,因此在Fast R-CNN中可以采用SVD分解加速全连接层计算。
设全连接层的输入为\(X\),权值矩阵为\(W_{u\times v}\),输出为\(Y\),则全连接层的实际上的计算是一个矩阵的乘法
可以将权值矩阵\(W\)进行奇异值分解(SVD分解),使用其前\(t\)个特征值近似代替该矩阵
其中,\(U\)是\(u \times t\)的左奇异矩阵,\(\Sigma_t\)是\(t \times t\)的对角矩阵,\(V\)是\(v \times t\)的右奇异矩阵。
截断SVD将参数量由原来的 \(u \times v\) 减少到 \(t \times (u + v)\),当 \(t\) 远小于 \(min(u,v)\) 的时候降低了很大的计算量。
在实现时,相当于把一个全连接层拆分为两个全连接层,第一个全连接层使用权值矩阵\(\Sigma_t V^T\)(不含偏置),第二个全连接层使用矩阵\(U\)(含偏置).当RoI的数量大时,这种简单的压缩方法有很好的加速
Summary
Fast R-CNN是对R-CNN的一种改进
- 卷积不再是对每个region proposal进行,而是直接对整张图像,这样减少了很多重复计算。原来RCNN是对每个region proposal分别做卷积,因为一张图像中有2000左右的region proposal,肯定相互之间的重叠率很高,因此产生重复计算。
- 用ROI pooling进行特征的尺寸变换,因为全连接层的输入要求尺寸大小一样,因此不能直接把region proposal作为输入
- 将regressor放进网络一起训练,每个类别对应一个regressor,同时用softmax的全连接层代替原来的SVM分类器。
Faster R-CNN
在Fast R-CNN中使用的目标检测识别网络,在速度和精度上都有了不错的结果。不足的是,其候选区域提取方法耗时较长,而且和目标检测网络是分离的,并不是end-to-end的。在Faster R-CNN中提出了区域检测网络(Region Proposal Network,RPN),将候选区域的提取和Fast R-CNN中的目标检测网络融合到一起,这样可以在同一个网络中实现目标检测。
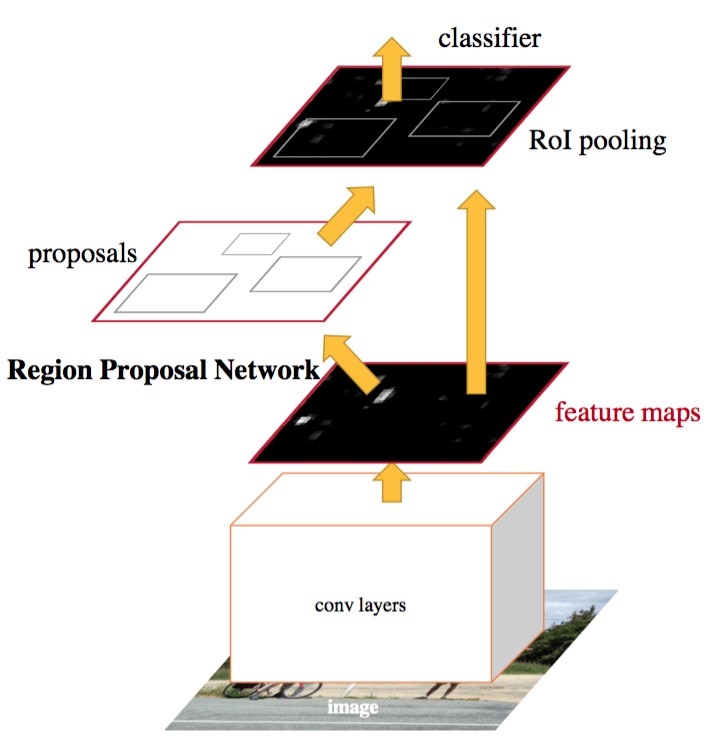
Faster R-CNN的网络有4部分组成:
- Conv Layers 一组基础的CNN层,由Conv + Relu + Pooling组成,用于提取输入图像的Feature Map。通常可以选择有5个卷积层的ZF网络或者有13个卷积层的VGG16。Conv Layers提取的Feature Map用于RNP网络生成候选区域以及用于分类和边框回归的全连接层。
- RPN,区域检测网络 输入的是前面卷积层提取的Feature Map,输出为一系列的候选区域。
- RoI池化层 输入的是卷积层提取的Feature Map 和 RPN生成的候选区域RoI,其作用是将Feature Map 中每一个RoI对应的区域转为为固定大小的\(H \times W\)的特征图,输入到后面的分类和边框回归的全连接层。
- 分类和边框回归修正 输入的是RoI池化后RoI的\(H \times W\)的特征图,通过SoftMax判断每个RoI的类别,并对边框进行修正。
其整个工作流程如下:
- 将样本图像整个输入到Conv Layers中,最后得到Feature Map。
- 将该Feature Map输入到RPN网络中,提取到一系列的候选区域
- 然后由RoI池化层提取每个候选区域的特征图
- 将候选区域的特征图输入到用于分类的Softmax层以及用于边框回归全连接层。
Faster R-CNN的4个组成部分,其中Conv Layers,RoI池化层以及分类和边框回归修正,和Fast R-CNN的区别不是很大,其重大改进就是使用RPN网络生成候选区域。
卷积层 Conv Layers
前面的卷积层用于提取输入图像的特征,生成Feature Map。这里有VGG-16为例,Conv layers部分共有13个conv层,13个relu层,4个pooling层。在VGG中,
- 所有的卷积层都使用\(3\times3\)的卷积核,步长为1,并对边缘做了填充\(padding=1\)。这样对于输入\(W \times W\)的图像,通过卷积后,其输出尺寸为\((W - 3 + 2 * padding) / 1 + 1 = W\),也就是通过卷积层图像的尺寸并不会变小。
- 池化层都是用\(2 \times 2\)的池化单元,步长为2。对于\(W \times W\)的图像,通过池化层后,其输出的尺寸为\((W - 2) / 2 + 1 = W / 2\),也就是通过一个池化层图像的尺寸会变为输入前的$1 /2 $。
Conv Layers的13个conv层并不会改变图像的尺寸,而有4个池化层,每个池化层将输入缩小为原来的\(1/2\),则对于\(W \times W\)的输入,Conv Layers输出的Feature Map的宽和高为\(W / 16 \times W /16\),也就是输入尺寸的\(1/16\)。 有了这个Feature Map相对于原始输入图像的宽高比例,就可以计算出Feature Map中的每个点对应于原图的区域。
由于池化层的降采样,Feature Map中的点映射回原图上,对应的不是某个像素点,而是矩形区域。
区域检测网络 RPN
区域提议网络(RPN)以任意大小的图像作为输入,输出一组矩形的候选区域,并且给每个候选区域打上一个分数。如下图
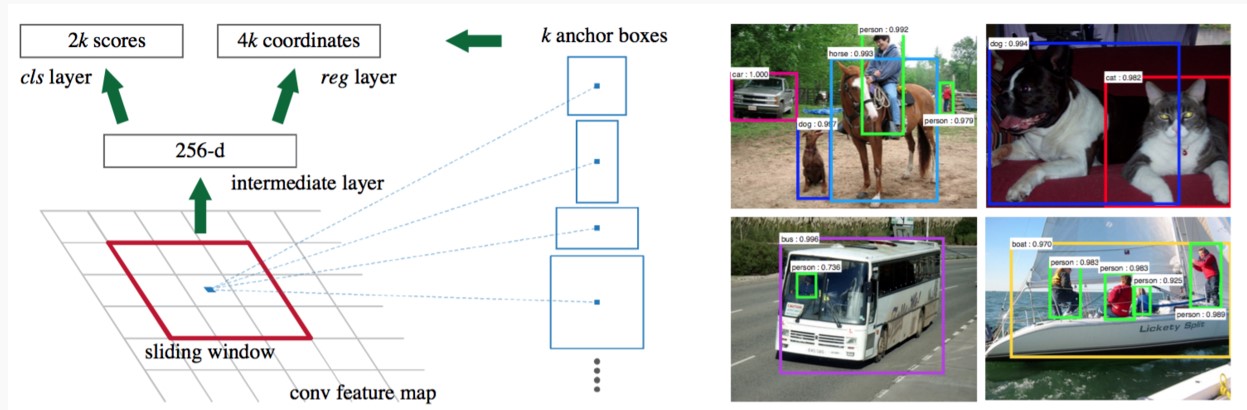
RPN输入的是前面Conv Layers提取图像的Feature Map,输出有两部分:
- 候选区域的位置信息(一个4维元组)
- 候选区域对应的类别(二分类,背景还是前景)。
为了得到上述的两种输出,要从输入的Feature Map上得到两种信息:
- 候选区域在原始输入图像的位置信息
- 每个候选区域对应的Feature Map,用于分类。
Anchor
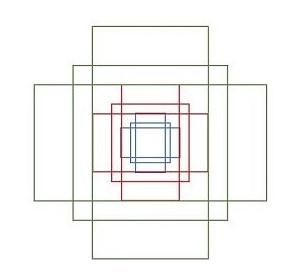
前面提到由于池化层的降采样,Feature Map中的点映射回原图上,对应的不是某个像素点,而是矩形区域。很简单的,可以将Feature Map中的每个点映射回原始图像,就可以得到一个候选区域,但是这样得到的区域太过于粗糙,显然是不行的。Faster R-CNN使用的是将每个Feature Map中的点映射到原图上,并以映射后的位置为中心,在原图取不同形状和不同面积的矩形区域,作为候选区域。 论文中提出了Anchor的概念来表示这种取候选区域的方法:一个Anchor就是Feature Map中的一个点,并有一个相关的尺度和纵横比。说白了,Anchor就是一个候选区域的参数化表示,有了中心点坐标,知道尺寸信息以及纵横比,很容易通过缩放比例在原图上找到对应的区域。
在论文中为每个Anchor设计了3种不同的尺度\({128\times 128,256 \times 256,512 \times 512}\),3种形状,也就是不同的长宽比\(W:H = {1:1,1:2,2:1}\),这样Feature Map中的点就可以组合出来9个不同形状不同尺度的Anchor。下图展示的是这9个Anchor对应的候选区域:
现假设输入到Conv Layers的图像尺寸为\(800 \times 600\),通过VGG16的下采样缩小了16倍,则最终生成的Feature Map的尺寸为
有Feature Map的一个点\((5,5)\),以该点为Anchro,生成不同的候选区域
- 首先将该点映射回原图的坐标为\((5 \times 16,5 \times 16) = (90,90)\)
- 选择一个形状和面积的组合,例如尺度为\(128 \times 128\),形状为\(W:H = 1:1\)
- 在原图上以\((90,90)\)为中心,计算符合上述形状的区域的坐标\((x_1,y_1,x_2,y_2)=(36,36,154,154)\):
上面就得到了位置为\((5,5)\),尺度为\(128 \times 128\),形状为\(W:H = 1:1\)的Anchor在原图上取得的候选区域。
只有区域信息也不行啊,这些区域有可能是前景也有可能是背景,这就需要提取这些区域对应的特征信息,用于分类。对于VGG16,其最终生成的特征图有512个通道,也就是每个点都可以得到一个512维的特征,将这个特征作为该点为Anchor生成的区域特征,用于分类。 论文中,是在特征图上做一个\(3 \times 3\)的卷积,融合了周围的信息。
设Feature Map的尺度为\(W \times H\),每个点上生成k个Anchor(\(k = 9\)),则总共可以得到\(WHk\)个Anchors。而每个Anchor即可能是前景也可能是背景,则需要Softmax层\(cls = 2k\) scores;并且每个anchor对应的候选区域相对于真实的边框有$(x,y,w,y)\(4个偏移量,这就需要边框回归层\)reg = 4k$ coordinates。
训练
每个anchor即可能包含目标区域,也可能没有目标。 对于包含目标区域的anchor分为positive label,论文中规定,符合下面条件之一的即为positive样本:
- 与任意GT区域的IoU大于0.7
- 与GT(Groud Truth)区域的IoU最大的anchor(也许不到0.7)
和任意GT的区域的IoU都小于0.3的anchor设为negative样本,对于既不是正标签也不是负标签的anchor,以及跨越图像边界的anchor就直接舍弃掉。
由于一张图像能够得到\(WHk\)个Anchors,显然不能将所有的anchor都用于训练。在训练的时候从一幅图像中随机的选择256个anchor用于训练,其中positive样本128个,negative样本128个。
关于边框回归的具体内容,由于本文内容过多,这里不再说明,单独另写。
summary
本文就R-CNN的系列文章进行了一个大致的梳理,从R-CNN初次将CNN应用于目标检测,到最终的Faster R-CNN通过一个CNN网络完成整个目标检测的演变过程。下图总结下三个网络
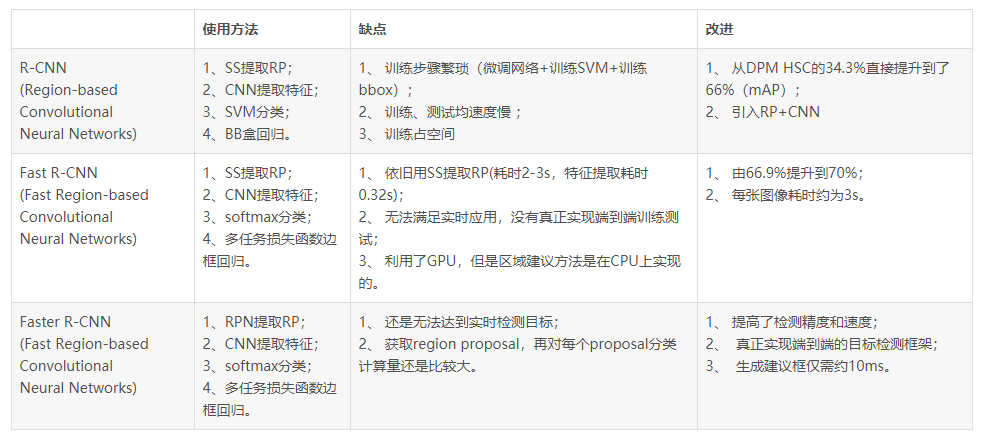
上表格引用自 Faster R-CNN论文笔记——FR

 浙公网安备 33010602011771号
浙公网安备 33010602011771号