
102302112王光诚作业4
作业①:
熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容。
使用Selenium框架+ MySQL数据库存储技术路线爬取“沪深A股”、“上证A股”、“深证A股”3个板块的股票数据信息。
点击查看代码
import time
import pymysql
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
db = pymysql.connect(
host="localhost",
user="root",
password="123456",
database="stock",
charset="utf8mb4"
)
cursor = db.cursor()
service = Service()
options = webdriver.ChromeOptions()
options.add_argument("--start-maximized")
options.add_argument("--disable-blink-features=AutomationControlled")
driver = webdriver.Chrome(service=service, options=options)
boards = {
"hs": "http://quote.eastmoney.com/center/gridlist.html#hs_a_board",
"sh": "http://quote.eastmoney.com/center/gridlist.html#sh_a_board",
"sz": "http://quote.eastmoney.com/center/gridlist.html#sz_a_board"
}
def scroll_to_bottom():
last = 0
max_scroll_attempts = 5
attempts = 0
while attempts < max_scroll_attempts:
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(1.5)
new = driver.execute_script("return document.body.scrollHeight")
if new == last:
break
last = new
attempts += 1
print("滚动完成,累计滚动次数:", attempts, "次")
def parse_and_save(board_name):
print("等待股票列表加载...")
WebDriverWait(driver, 20).until(
EC.presence_of_element_located((By.CSS_SELECTOR, "tbody tr"))
)
rows = driver.find_elements(By.CSS_SELECTOR, "tbody tr")
print(board_name, "板块已获取", len(rows), "条股票数据")
for row in rows:
cols = row.find_elements(By.TAG_NAME, "td")
if len(cols) < 14:
continue
try:
data = {
"bStockNo": cols[1].text,
"bName": cols[2].text,
"bPrice": cols[4].text,
"bChangePercent": cols[5].text,
"bChangeAmount": cols[6].text,
"bVolume": cols[7].text,
"bTurnover": cols[8].text,
"bAmplitude": cols[9].text,
"bHigh": cols[10].text,
"bLow": cols[11].text,
"bOpen": cols[12].text,
"bPrevClose": cols[13].text,
"board": board_name
}
except IndexError:
print("索引异常,跳过当前行")
continue
sql = """
INSERT INTO stock_info(
bStockNo, bName, bPrice, bChangePercent, bChangeAmount,
bVolume, bTurnover, bAmplitude, bHigh, bLow, bOpen,
bPrevClose, board
)
VALUES (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)
"""
try:
cursor.execute(sql, list(data.values()))
db.commit()
except Exception as e:
print("MySQL写入失败")
print("错误信息:", e)
print("异常数据:", data)
print("----------------")
db.rollback()
try:
print("股票数据爬取程序启动")
print("----------------")
for board, url in boards.items():
print("\n开始爬取", board.upper(), "板块")
driver.get(url)
print("当前页面:", driver.title)
print("访问地址:", driver.current_url)
time.sleep(3)
scroll_to_bottom()
parse_and_save(board)
finally:
driver.quit()
db.close()
print("\n爬取任务全部完成")
print("数据已写入MySQL数据库")
print("数据库:stock,数据表:stock_info")
作业②:
熟练掌握 Selenium 查找HTML元素、实现用户模拟登录、爬取Ajax网页数据、等待HTML元素等内容。
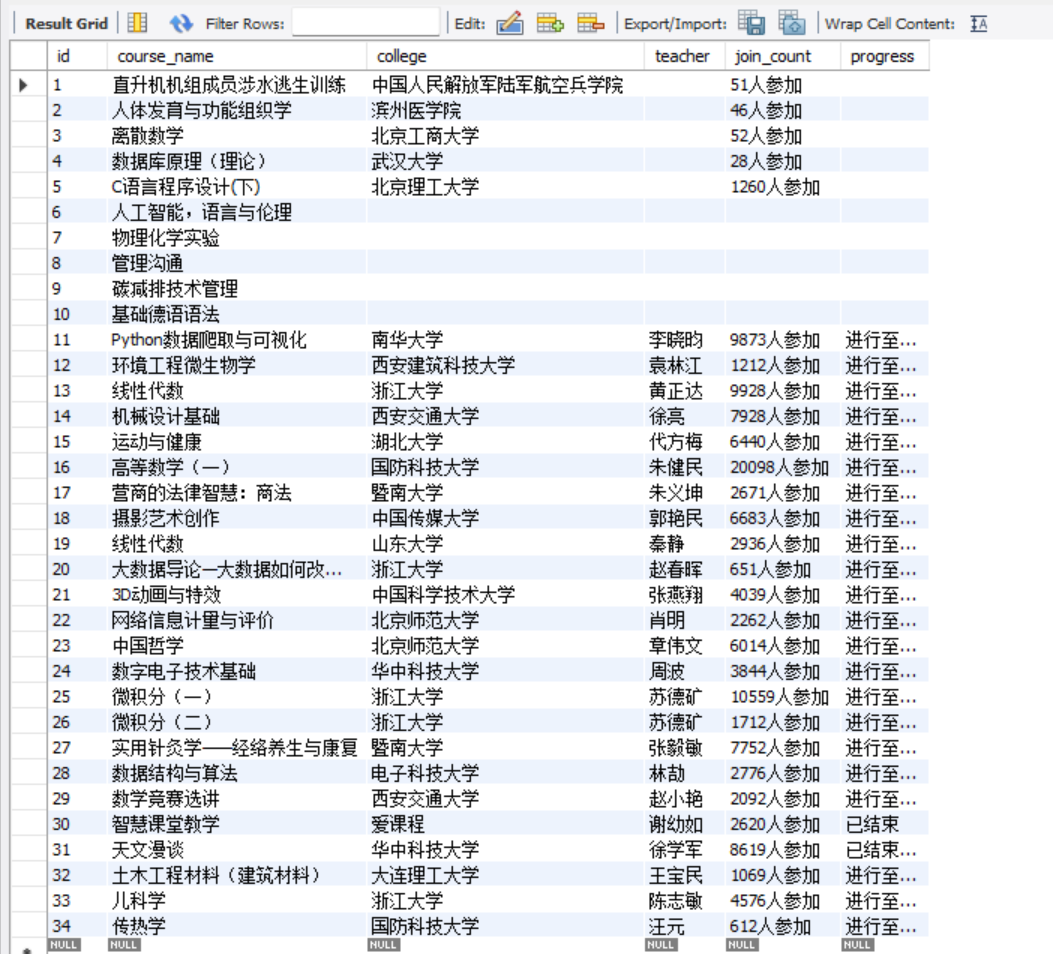
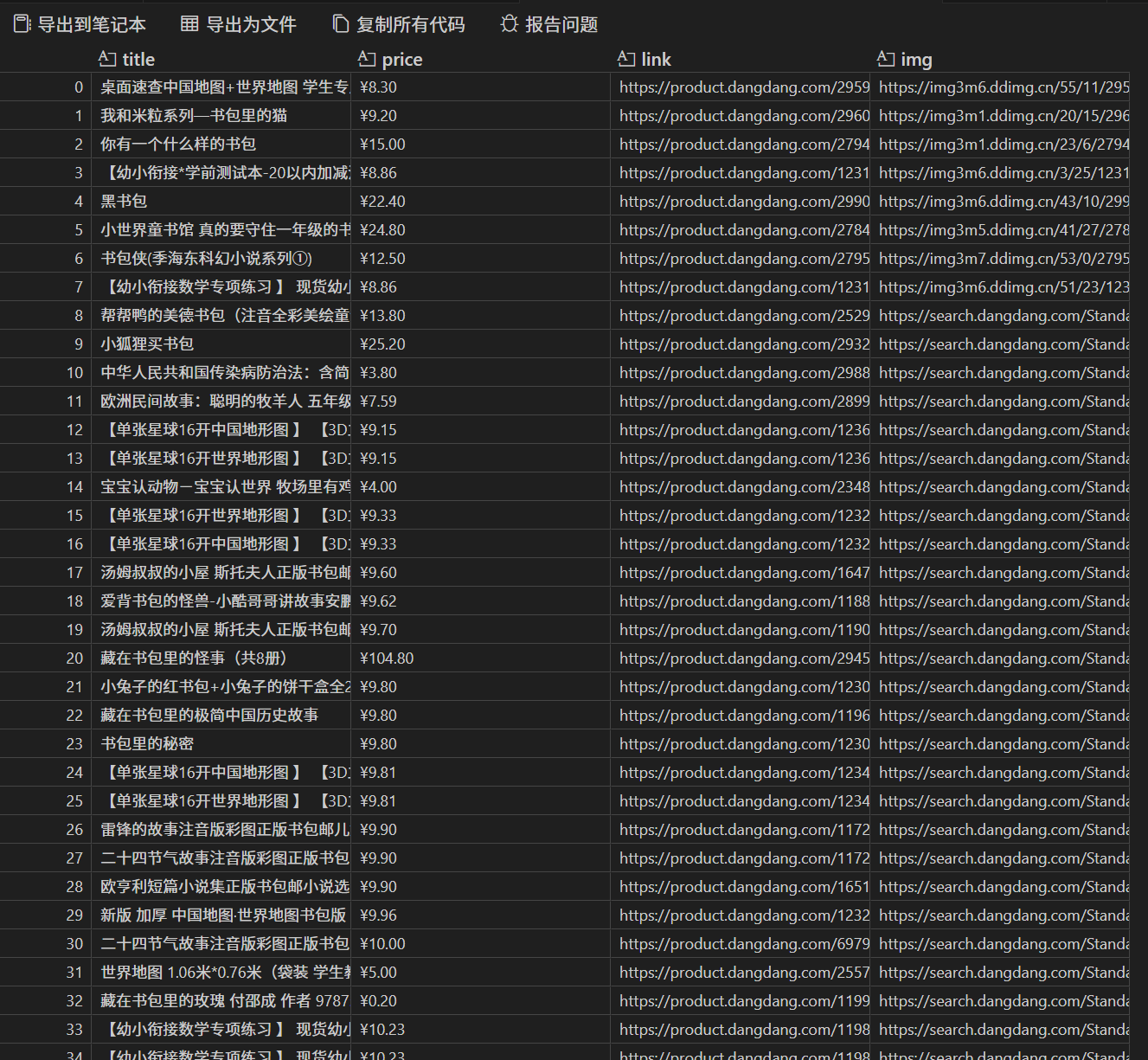
使用Selenium框架+MySQL爬取中国mooc网课程资源信息(课程号、课程名称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介)
点击查看代码
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.expected_conditions import any_of
import time
import pymysql
import json
import os
COOKIES_FILE = "cookies_icourse163.json"
def try_load_cookies(driver, cookies_file=COOKIES_FILE):
if not os.path.exists(cookies_file):
print("本地未找到 cookies 文件,跳过自动登录")
return False
try:
with open(cookies_file, "r", encoding="utf-8") as f:
cookies = json.load(f)
driver.get("https://www.icourse163.org/")
time.sleep(2)
for c in cookies:
if "expiry" in c:
c["expiry"] = int(c["expiry"])
c.pop("sameSite", None)
driver.add_cookie(c)
driver.refresh()
time.sleep(2)
print("已注入 cookies,尝试自动登录态复用")
return True
except Exception as e:
print("cookies 注入失败:", e)
return False
def save_cookies(driver, cookies_file=COOKIES_FILE):
try:
cookies = driver.get_cookies()
with open(cookies_file, "w", encoding="utf-8") as f:
json.dump(cookies, f, ensure_ascii=False, indent=2)
print(f"cookies 已保存到 {cookies_file},下次可自动复用登录态")
except Exception as e:
print("保存 cookies 失败:", e)
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument("--window-size=1200,800")
driver = webdriver.Chrome(options=chrome_options)
driver.get("https://www.icourse163.org/")
print("正在加载首页...")
WebDriverWait(driver, 20).until(
EC.presence_of_element_located((By.CLASS_NAME, "_1AFcD"))
)
time.sleep(2)
auto_logged_in = try_load_cookies(driver)
try:
close_popup = WebDriverWait(driver, 5).until(
EC.element_to_be_clickable((By.XPATH, "//i[contains(@class, 'icon-close')]"))
)
close_popup.click()
except:
pass
if not auto_logged_in:
login_btn = WebDriverWait(driver, 20).until(
EC.element_to_be_clickable(
(By.XPATH, "//div[contains(@class, '_1AFcD') and contains(@class, 'navLoginBtn')]//div[text()='登录 | 注册']")
)
)
driver.execute_script("arguments[0].click();", login_btn)
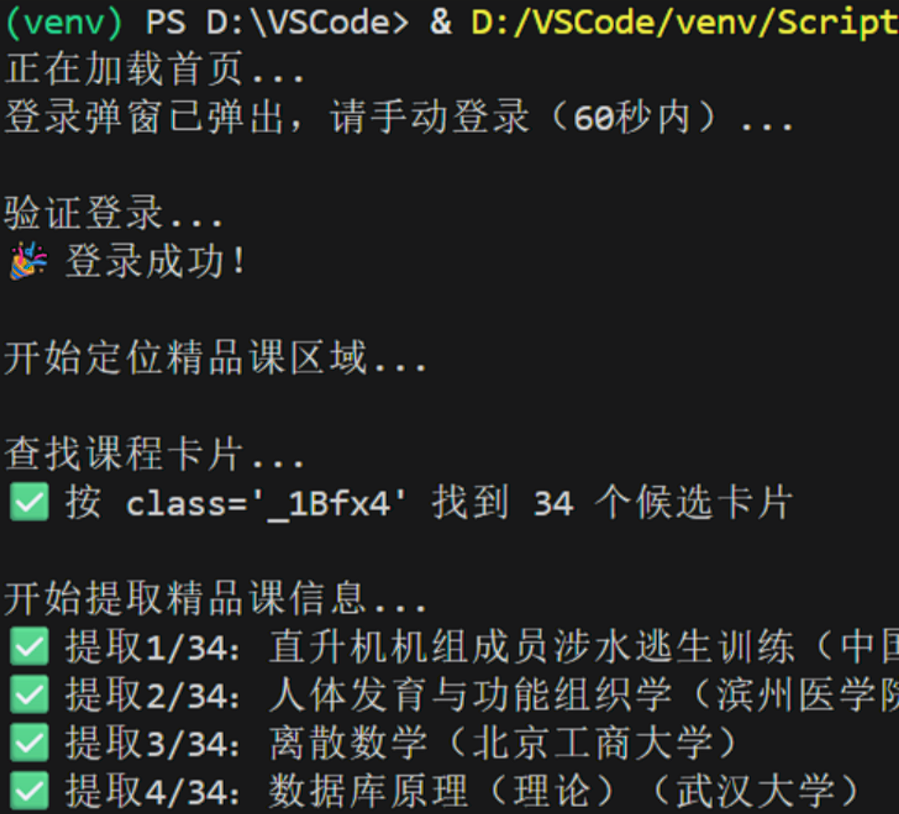
print("登录弹窗已弹出,请手动登录(60秒内)...")
time.sleep(60)
print("\n验证登录...")
try:
WebDriverWait(driver, 15).until(
any_of(
EC.presence_of_element_located((By.XPATH, "//a[contains(@class, '_32H7d')]")),
EC.presence_of_element_located((By.XPATH, "//span[text()='Hi,']")),
EC.invisibility_of_element_located((By.XPATH, "//div[text()='登录 | 注册']"))
)
)
print("登录成功!")
save_cookies(driver)
except:
print("已强制继续爬取精品课...")
print("\n开始定位精品课区域...")
try:
try:
title_elem = driver.find_element(By.XPATH, "//*[contains(text(),'国家精品课') or contains(text(),'精品课') or contains(text(),'精品')]")
driver.execute_script("arguments[0].scrollIntoView({block: 'center'});", title_elem)
except:
driver.execute_script("window.scrollTo(0, 500);")
time.sleep(2)
for _ in range(3):
driver.execute_script("window.scrollBy(0, 600);")
time.sleep(1.0)
except Exception as e:
print("滚动触发懒加载时出错(但继续):", e)
print("\n查找课程卡片...")
course_cards = []
try:
course_cards = WebDriverWait(driver, 15).until(
EC.presence_of_all_elements_located((By.CLASS_NAME, "_1Bfx4"))
)
print(f"按 class='_1Bfx4' 找到 {len(course_cards)} 个候选卡片")
except Exception as e:
print("未通过 class='_1Bfx4' 找到卡片,尝试备用定位...")
if not course_cards:
try:
course_cards = driver.find_elements(By.XPATH, "//div[.//h3]")
if course_cards:
print(f"备用定位找到 {len(course_cards)} 个候选卡片(包含 h3)")
except Exception as e:
print("备用定位也失败:", e)
if not course_cards:
print("未找到任何课程卡片,可能页面未加载或选择器失效。退出。")
driver.quit()
exit()
course_data_list = []
print("\n开始提取精品课信息...")
for idx, card in enumerate(course_cards, 1):
try:
course_name = ""
try:
h3 = card.find_element(By.XPATH, ".//h3")
course_name = (h3.get_attribute("title") or h3.text or "").strip()
except:
try:
course_name = card.find_element(By.CLASS_NAME, "_3EwZv").text.strip()
except:
try:
course_name = card.find_element(By.XPATH, ".//h3").text.strip()
except:
course_name = ""
college = ""
try:
college = card.find_element(By.XPATH, ".//p").text.strip()
except:
try:
college = card.find_element(By.CLASS_NAME, "_2lZi3").text.strip()
except:
college = ""
teacher = ""
try:
teacher = card.find_element(By.CLASS_NAME, "_1Zkj9").text.strip()
except:
try:
teacher = card.find_element(By.XPATH, ".//div[contains(@class,'WFpCn')]//div[normalize-space() and not(contains(@class,'jvxcQ'))]").text.strip()
except:
teacher = ""
join_count = ""
try:
join_count = card.find_element(By.CLASS_NAME, "_3DcLu").text.strip()
except:
try:
elem = card.find_element(By.XPATH, ".//*[contains(text(),'参加') or contains(text(),'人参加') or contains(text(),'人已参加')]")
join_count = elem.text.strip()
except:
try:
span = card.find_element(By.XPATH, ".//span")
join_count = span.text.strip()
except:
join_count = ""
progress = ""
try:
progress = card.find_element(By.XPATH, ".//div[contains(@class,'B3fm9') or contains(@class,'_162md')]").text.strip()
except:
try:
prog_elem = card.find_element(By.XPATH, ".//div[contains(text(),'进行') or contains(text(),'第') or contains(text(),'已开') or contains(text(),'周')]")
progress = prog_elem.text.strip()
except:
progress = ""
price = ""
try:
price = card.find_element(By.CLASS_NAME, "_2IAKt").text.strip()
except:
try:
price_elem = card.find_element(By.XPATH, ".//*[contains(text(),'¥') or contains(text(),'¥')]")
price = price_elem.text.strip()
except:
price = ""
if not price:
price = "免费"
course_name = course_name.replace("\n", " ").strip()
college = college.replace("\n", " ").strip()
teacher = teacher.replace("\n", " ").strip()
join_count = join_count.replace("\n", " ").strip()
progress = progress.replace("\n", " ").strip()
price = price.replace("\n", " ").strip()
if not course_name:
print(f"第{idx}条记录缺少课程名,已跳过")
continue
course_data_list.append({
"course_name": course_name,
"college": college,
"teacher": teacher,
"join_count": join_count,
"progress": progress,
"price": price
})
print(f"提取{idx}/{len(course_cards)}:{course_name}({college}) 价格:{price}")
except Exception as e:
print(f"第{idx}门课提取失败:{str(e)}")
continue
print(f"\n开始存入数据库...共{len(course_data_list)}门精品课")
try:
db = pymysql.connect(
host="localhost",
user="root",
password="123456",
database="mooc_course_db"
)
cursor = db.cursor()
cursor.execute("""
SELECT COUNT(*)
FROM INFORMATION_SCHEMA.COLUMNS
WHERE TABLE_SCHEMA=%s AND TABLE_NAME='course_info' AND COLUMN_NAME='price'
""", ("mooc_course_db",))
has_price_col = cursor.fetchone()[0] > 0
if has_price_col:
insert_sql = """
INSERT INTO course_info (course_name, college, teacher, join_count, progress, price)
VALUES (%s, %s, %s, %s, %s, %s)
"""
values = [
(c["course_name"], c["college"], c["teacher"], c["join_count"], c["progress"], c["price"])
for c in course_data_list
]
else:
insert_sql = """
INSERT INTO course_info (course_name, college, teacher, join_count, progress)
VALUES (%s, %s, %s, %s, %s)
"""
values = [
(c["course_name"], c["college"], c["teacher"], c["join_count"], c["progress"])
for c in course_data_list
]
if values:
cursor.executemany(insert_sql, values)
db.commit()
print(f"成功存入{len(values)}门精品课到数据库!")
else:
print("无有效课程可存入")
cursor.close()
db.close()
except Exception as e:
print(f"数据库错误:{str(e)}")
driver.quit()
print("\n操作完成!已爬取并存储你需要的精品课信息")
作业③:
掌握大数据相关服务,熟悉Xshell的使用
完成文档 华为云_大数据实时分析处理实验手册-Flume日志采集实验(部分)v2.docx 中的任务,即为下面5个任务,具体操作见文档。
成功创建集群
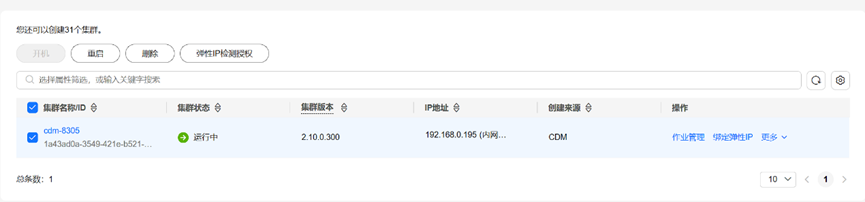
脚本成功生成测试数据
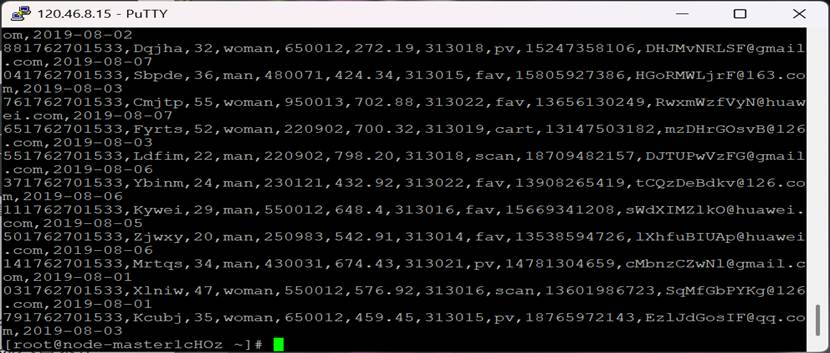
Flume 服务重启成功
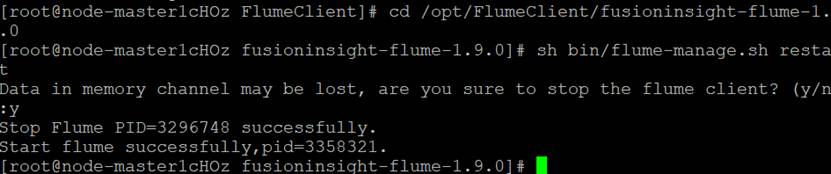
成功生成数据
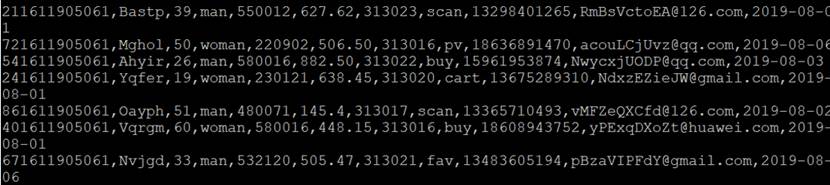
成功创建kfaka

心得体会:爬股票数据时,我遇到部分字段抓取错位的问题,排查发现是元素定位未匹配动态加载顺序,改用显式等待并按表格行遍历后解决
中国 mooc 网爬取中,模拟登录后无法加载课程列表,经查是未切换 iframe,调整定位方式后成功获取数据
大数据实验里,Flume 采集不到 Kafka 数据,核对好几次配置文件后发现端口号写错,修正后才终于数据采集
gitee文件链接:https://gitee.com/wangguangcheng/data-harvesting/tree/master/作业4

 浙公网安备 33010602011771号
浙公网安备 33010602011771号