

自动化测试-6.unittest实战
上篇文章讲了unittest的四大组件,以及组件的日常使用,这篇主要是在四大组件上的扩充,丰富自动化的方法
1.ddt的使用:data-driver-tests
在实际的测试中,有些地方无论是接口还是ui知识参数数据的输入不一样,操作是一样的,比如登录,只是切换了账号,但是登录这个操作是一样的,如果重复编写,无疑是大大增加了工作量,对此,我们可以通过使用ddt来解决这个问题。
ddt属于第三方扩展库,使用之前需要下载: pip install ddt
使用前需要先导入模块:from ddt import 需要的方法
ddt:在类名上面加ddt的装饰器@ddt,表示要使用ddt,然后在用例上面加装饰器@data(),括号里面写需要的参数,写几个就循环几次
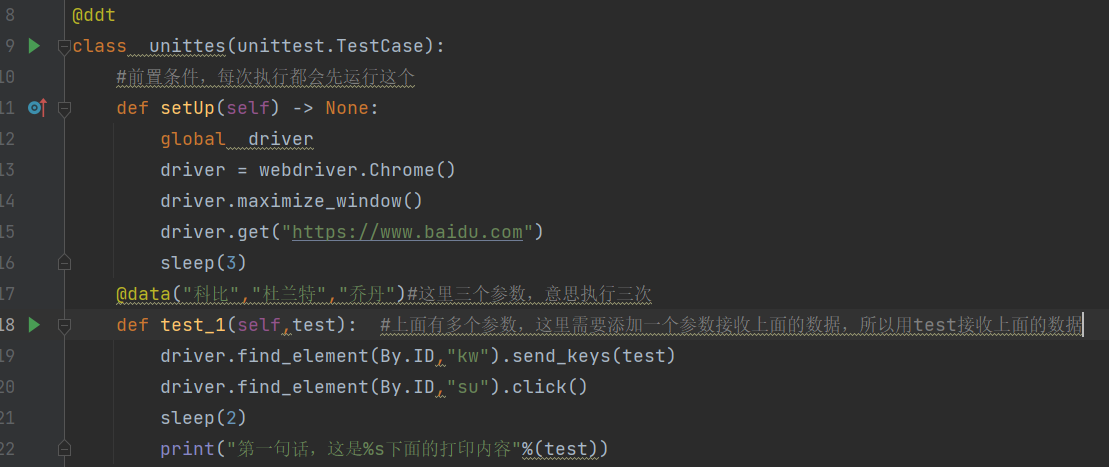
上面讲了ddt里面的data()装饰器,这里再讲一下unpack装饰器,unpack:方法装饰器,可以接报,如果需要添加多个参数,这样data(),就没办法实现了,这时候就需要unpack这个装饰器了
import unittest
from ddt import ddt,data,unpack
@ddt
class unittes(unittest.TestCase):
#前置条件,每次执行都会先运行这个
def setUp(self) -> None:
pass
@unpack
@data(("sheng123","123456","1111"),("赵","王","李"))
def test_1(self, test1,test2,test3): # 上面一个参数里面有多个参数,这里需要根据参数添加对应的参数
print(test1)
print(test2)
print(test3)
def tearDown(self) -> None:
pass
if __name__=="__main__":
unittes.main()
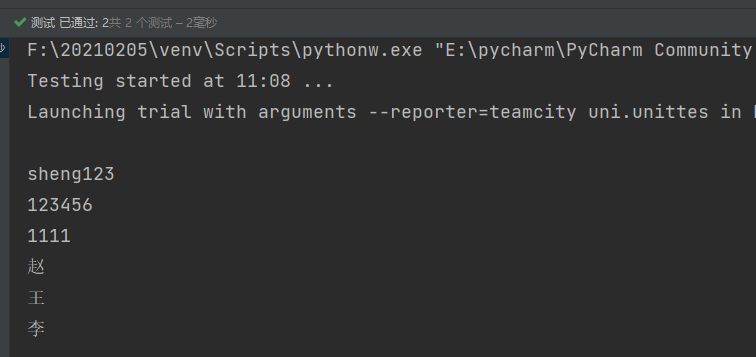
data:用于设定参数
unpack:用于解析参数
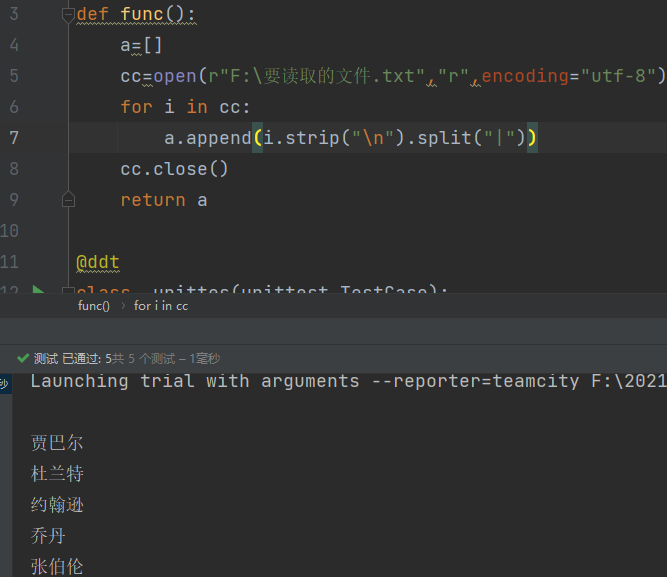
也可以用于读取文件中的内容,来实现批量运算,如下图
1.先定义一个函数,函数里面去读取我们需要的文件,把文件里的数据保存到列表里面,再返回这个列表
import unittest
from ddt import ddt,data,unpack
def func():
a=[]
cc=open(r"F:\要读取的文件.txt","r",encoding="utf-8")
for i in cc:
#这里必须要加上.split("|"),不加上的话解析包解析出来就是 贾巴尔 杜兰特 约翰逊 乔丹 张伯伦,data无法识别,运行后会报add_test() argument after ** must be a mapping, not str的错误
#当加上分隔符后,解析出来就是['贾巴尔'] ['杜兰特'] ['约翰逊'] ['乔丹'] ['张伯伦']这样就能正常使用了
a.append(i.strip("\n").split("|"))
cc.close()
return a
@ddt
class unittes(unittest.TestCase):
#前置条件,每次执行都会先运行这个
def setUp(self) -> None:
pass
@data(*func())
@unpack
def test_1(self,name):
print(name)
def tearDown(self) -> None:
pass
if __name__=="__main__":
unittes.main()
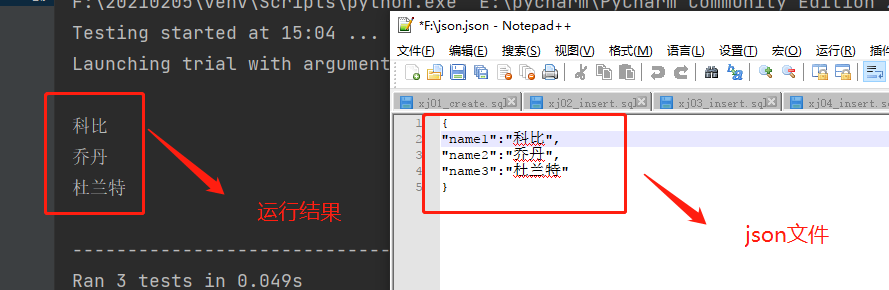
file_data:装饰测试方法,参数是文件名。文件可以是 json 或者 yaml 类型,这里用json文件举例
import unittest
from ddt import ddt, data, unpack, file_data
@ddt
class unittes(unittest.TestCase):
#前置条件,每次执行都会先运行这个
def setUp(self) -> None:
pass
@file_data("F:\json.json")
def test_1(self,name):
print(name)
def tearDown(self) -> None:
pass
if __name__=="__main__":
unittes.main()
根据下图得知,json文件指挥读取value的数据,当value的数据有两个的时候,如"name1":{"username":"科比","password":123456}这种写法,用例只需要传入两个参数即可
如果使用yaml文件要先导入yaml:import yaml 这里我就不演示了,因为暂时没有对应的文件,和json一样的操作
@unittest.skip(reason):强制跳转。reason是跳转原因
@unittest.skipIf(condition, reason):condition为True的时候跳转
@unittest.skipUnless(condition, reason):condition为False的时候跳转
@unittest.expectedFailure:如果test失败了,这个test不计入失败的case数目
import unittest
from ddt import ddt, data, unpack, file_data
class unittes(unittest.TestCase):
def setUp(self) -> None:
pass
#无条件的跳过这条用例,括号里面可以写说明
@unittest.skip("不会执行这条")
def test_1(self):
print(1)
#如果条件为真,则跳过这条用例,括号里面两个字段,第一个字段是条件,第二个是说明
@unittest.skipIf(1<3,'这个条件为真,不会执行')
def test_2(self):
print(2)
#跳过测试,除非条件为真才执行,第一个字段是条件,第二个是说明
@unittest.skipUnless(1<3,"这个条件为真,要执行")
def test_3(self):
print(3)
#如果test失败了,这个test不计入失败的case数目
@unittest.expectedFailure
def test_111(self):
print(1)
def tearDown(self) -> None:
pass
if __name__=="__main__":
unittes.main()
#把uni页面导入进来
import uni
from uni import unittes
#导入htmltestrunner包
from HTMLTestRunner import HTMLTestRunner
report_name="测试报告名称"
report_title="测试报告标题"
report_desc="测试报告描述"
#首先生成一个报告的文件路径
report_path="./report/"
#把生成的html文件保存在这个路径下面
report_file=report_path+"report.html"
#导入os方法,去判断这个路径里面存在,存在就说明这个文件存在,如果不存在,我们就生成一个这个文件存在就跳过
if not os.path.exists(report_path):
os.mkdir(report_path)
else:
pass
#‘wb’:表示以二进制写方式打开,只能写文件, 如果文件不存在,创建该文件;如果文件已存在,则覆盖写。
with open(report_file,"wb") as report:
suite = unittest.TestSuite()
suite.addTests(unittest.TestLoader().loadTestsFromName("uni.unittes"))
#套件通过testtestrunner对象进行运行
runner=HTMLTestRunner(stream=report,title=report_title,description=report_desc)
runner.run(suite)

打开如下


 浙公网安备 33010602011771号
浙公网安备 33010602011771号