语义分割中的度量标准
PA
pixel accuracy (像素精度)
标记正确的像素占总像素的比例
\[PA=\frac{\sum_{i=1}^kp_{ii}}{\sum_{i=0}^k\sum_{j=0}^kp_{ij}}
\]
MPA
mean pixel accuracy (均像素精度)计算每个类中被正确分类像素的比例,然后平均
\[MPA=\frac{1}{k+1}\sum_{i=0}^{k}\frac{p_{ii}}{\sum_{j=0}^kp_{ij}}
\]
Mean Intersection over Union(MIoU, 均交并比)
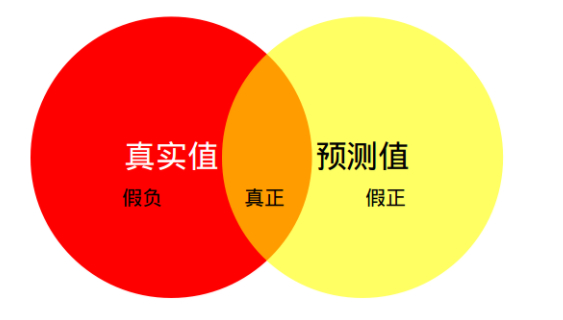
语义分割标准度量。计算两个集合的交集和并集之比。在semantic segmentation中,为真实值(ground truth)与预测值(predicted segmentation)的比值。这个比例变形为正真数(intersection)比上真正、假负、假正(并集)之和。在每个类上计算IoU,平均。
\[MIoU=\frac{1}{k+1}\sum_{i=0}^k\frac{p_{ii}}{\sum_{j=0}^k p_{ij}+\sum_{j=0}^kp_{ji}-p_{ii}}
\]
FWIoU
Frequency Weight Intersection over Union( 频权交并比)
MIoU的提升。根据每个类出现的频率设置权重
\[FWIoU=\frac{1}{\sum_{i=0}^k\sum_{j=0}^kp_{ij}}\sum_{i=0}^k\frac{p_{ii}}{\sum_{j=0}^k\sum_{j=0}^kp_{ji}-p_{ii}}
\]
#计算label_true和label_pred对应相同的就在矩阵中对应坐标加1。a和b保存着各个像素的分的类别
def _fast_hist(label_true, label_pred, n_class):
#过滤掉多余的分类
mask = (label_true >= 0) & (label_true < n_class)
#bincount用于统计在范围内出现的个数,即直方图,如果不够n^2个,
#那就填充到n^2,这样可以reshpe为n*n的矩阵,正好表示分割图和正确标记图在相同
#类别上像素出现的个数
hist = np.bincount(
n_class * label_true[mask].astype(int) +
label_pred[mask], minlength=n_class ** 2).reshape(n_class, n_class)
return hist
def label_accuracy_score(label_trues, label_preds, n_class):
"""Returns accuracy score evaluation result.
- overall accuracy
- mean accuracy
- mean IU
- fwavacc
"""
hist = np.zeros((n_class, n_class))
for lt, lp in zip(label_trues, label_preds):
hist += _fast_hist(lt.flatten(), lp.flatten(), n_class)
acc = np.diag(hist).sum() / hist.sum()
acc_cls = np.diag(hist) / hist.sum(axis=1)
acc_cls = np.nanmean(acc_cls)
iu = np.diag(hist) / (hist.sum(axis=1) + hist.sum(axis=0) - np.diag(hist))
mean_iu = np.nanmean(iu)
freq = hist.sum(axis=1) / hist.sum()
fwavacc = (freq[freq > 0] * iu[freq > 0]).sum()
return acc, acc_cls, mean_iu, fwavacc

 浙公网安备 33010602011771号
浙公网安备 33010602011771号