用pt-stalk定位MySQL短暂的性能问题
背景】
MySQL出现短暂的3-30秒的性能问题,一般的监控工具较难抓到现场,很难准确定位问题原因。
对于这类需求,我们日常的MySQL分析工具都有些不足的地方:
1、 性能监控工具,目前粒度是分钟级,无法反应秒级的性能波动;
2、 MySQL Performance_schema工具采集是3秒落地10000行记录,对于QPS大于3000以上的服务器采集会丢失数据;
Performance_schema数据通常用来分析语句级的性能问题,比如CPU高消耗,扫描行数等语句问题,对于系统内部mutex,lock,thread等资源竞争的问题无法定位。
3、 Table DML工具(5分钟粒度)
4、 Slow Log记录大于1秒的慢查询,反应的可能是果,而不是因
5、 MySQL Guard工具实现是依赖报警系统触发,一般对于持续在1分钟以上的问题可以抓取到现场
前面扩展过一个功能,对高CPU的监控,粒度可以到10秒左右
pt-stalk工具可以解决更细粒度的故障现场采集,守护进程的方式试用了一下,可以帮助我们解决一些问题。
【pt-stalk工具的使用】
尝试用pt-stalk工具做故障现场的快照采集
1、自定义脚本,定义CPU作为触发条件
function trg_plugin(){
a=$(sar 1 1 | grep -i "Average:"| awk '{print $8}');echo 100 - $a |bc
}
2、用pt-stalk开启守护进程,下面命令实现了用自定义的pt_cpu.sh脚本做为判断条件,当CPU的值(100-%idle)大于50,判断的间隔时间为1秒,连续3次满足条件时触发快照采集,触发后会sleep 60秒
pt-stalk --daemonize --dest=/tmp/log/pt-stalk --user= --password= --port= --function=/tmp/pt_cpu.sh --variable highcpu --cycles=3 --interval=1 --threshold 50 --sleep=60 --log=/var/log/pt-stalk.log
具体的参数可参考man pt-stalk。
【案例分析】
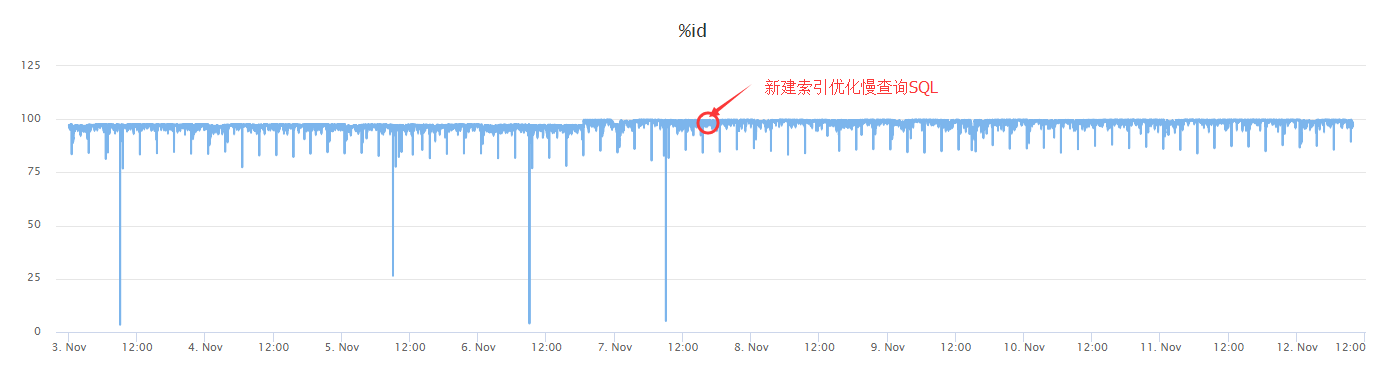
有台服务器出现短暂的线程和CPU告警的问题,现在每天在9点多都有CPU的告警,但持续时间较短,MySQL Guard工具很难采集到现场。
按照之前性能计数器反应的指标,猜测是由于binlog备份导致的IO上升,又导致了线程积压,但实际不是这个原因,binlog备份时间重合只是巧合。
在这台服务器开启pt-stalk守护进程后,今天早上CPU告警时触发了采集

抓取的快照信息如下:
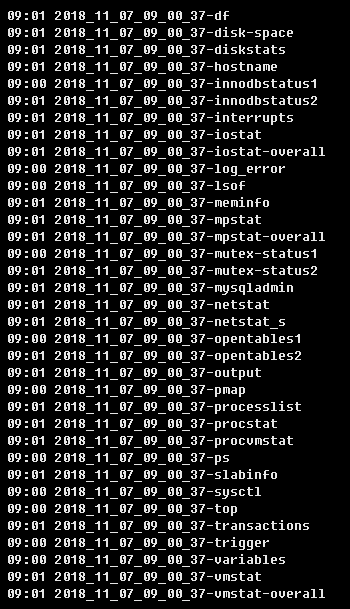
依据故障快照信息,再结合slow log和performance_schema语句明细,有足够的信息可以定位出问题原因。
1、在9:01分CPU出现上升
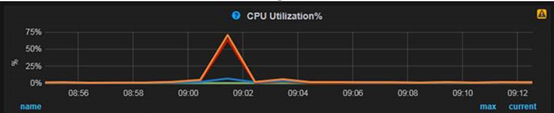
2、pt-stalk采集的CPU信息记录了更细粒度,连续30秒的信息,其中连续30秒CPU sys占比都在80%以上,通常是并发线程较高,context switch过高导致的sys消耗

3、连续30秒的Threads_running确实比较高
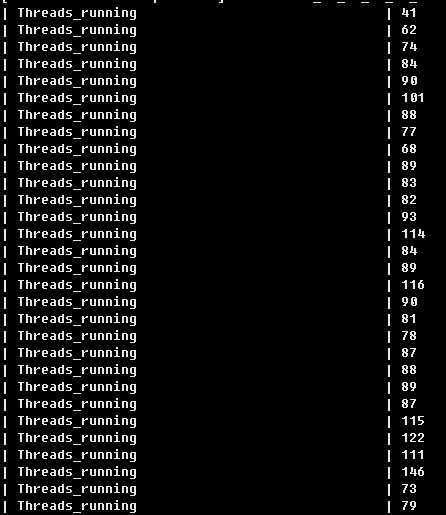
4、进一步分析,容易找到问题原因是由于每天9:00定时job运行,有一句高并发的慢查询SQL导致了线程积压
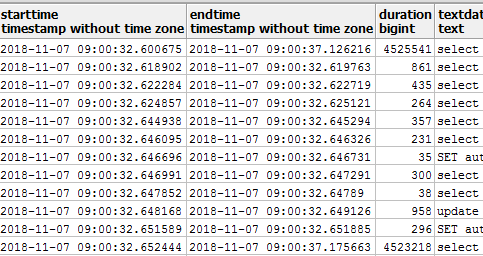
6、 慢查询SQL是由于缺失索引导致,补建索引后观察,CPU的问题解决了
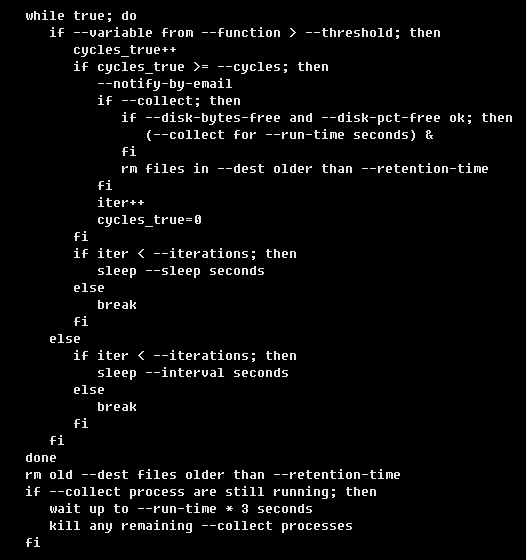
【pt-stalk的性能】
正常情况下守护进程的性能开销并不大,建议可以在有需要排障时再定制开启。下面是它的处理逻辑

 浙公网安备 33010602011771号
浙公网安备 33010602011771号