Java HashMap 源码阅读

# HashMap
-
内部类
static class Node<K,V> implements Map.Entry<K,V> final class KeySet extends AbstractSet<K> final class Values extends AbstractCollection<V> final class EntrySet extends AbstractSet<Map.Entry<K,V>> abstract class HashIterator final class KeyIterator extends HashIterator final class ValueIterator extends HashIterator final class EntryIterator extends HashIterator static class HashMapSpliterator<K,V> static final class KeySpliterator<K,V> static final class ValueSpliterator<K,V> static final class EntrySpliterator<K,V> static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V>-
详细
Nodestatic class Node<K,V> implements Map.Entry<K,V>{ final int hash; final K key; V value; Node<K,V> next; Node(int hash, K key, V value, Node<K,V> next) public final K getKey() public final V getValue() public final String toString() public final int hashCode() public final V setValue(V newValue) public final boolean equals(Object o) }- 一个 Node 节点包含一个 hash,key,value 和下一个 Node,即是一个单向链表结构
- hash 是当前节点的 key 的 hashcode 经过 HashMap 的 hash 函数的 hash 值
- table 的同一位置的链表,Node 的 hash 和 数组长度减 1 与的结果相等,但数组长度的高位为 0 的位 不同 Node 的 hash 值可能不等
-
详细
TreeNodestatic final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> { TreeNode<K,V> parent; // red-black tree links TreeNode<K,V> left; TreeNode<K,V> right; TreeNode<K,V> prev; // needed to unlink next upon deletion boolean red; TreeNode(int hash, K key, V val, Node<K,V> next) final TreeNode<K,V> root() static <K,V> void moveRootToFront(Node<K,V>[] tab, TreeNode<K,V> root) final TreeNode<K,V> find(int h, Object k, Class<?> kc) final TreeNode<K,V> getTreeNode(int h, Object k) static int tieBreakOrder(Object a, Object b) final void treeify(Node<K,V>[] tab) final Node<K,V> untreeify(HashMap<K,V> map) final TreeNode<K,V> putTreeVal(HashMap<K,V> map, Node<K,V>[] tab, int h, K k, V v) final void removeTreeNode(HashMap<K,V> map, Node<K,V>[] tab, boolean movable) final void split(HashMap<K,V> map, Node<K,V>[] tab, int index, int bit) static <K,V> TreeNode<K,V> rotateLeft(TreeNode<K,V> root, TreeNode<K,V> p) static <K,V> TreeNode<K,V> rotateRight(TreeNode<K,V> root, TreeNode<K,V> p) static <K,V> TreeNode<K,V> balanceInsertion(TreeNode<K,V> root, TreeNode<K,V> x) static <K,V> TreeNode<K,V> balanceDeletion(TreeNode<K,V> root, TreeNode<K,V> x) static <K,V> boolean checkInvariants(TreeNode<K,V> t) }-
TreeNode 继承自 LinkedHashMap.Entry<K,V>,而 LinkedHashMap.Entry<K,V> 继承自 HashMap.Node<K,V>,因此 TreeNode 是 Node 的子类,Node 的 next 指针可以指向 TreeNode
-
详细
final TreeNode<K,V> getTreeNode(int h, Object k)final TreeNode<K,V> getTreeNode(int h, Object k) { return ((parent != null) ? root() : this).find(h, k, null); }- 要根据 hash 和 key 找到指定的 TreeNode
- 如果当前节点的 parent 不为空,表示该节点不是根节点,则调用 root() 遍历到根节点,然后调用根节点的 find
- 如果当前节点的 parent 为空,表示该节点是根节点,调用该节点的 find
-
详细
final TreeNode<K,V> find(int h, Object k, Class<?> kc)final TreeNode<K,V> find(int h, Object k, Class<?> kc) { TreeNode<K,V> p = this; do { int ph, dir; K pk; TreeNode<K,V> pl = p.left, pr = p.right, q; if ((ph = p.hash) > h) p = pl; else if (ph < h) p = pr; else if ((pk = p.key) == k || (k != null && k.equals(pk))) return p; else if (pl == null) p = pr; else if (pr == null) p = pl; else if ((kc != null || (kc = comparableClassFor(k)) != null) && (dir = compareComparables(kc, k, pk)) != 0) p = (dir < 0) ? pl : pr; else if ((q = pr.find(h, k, kc)) != null) return q; else p = pl; } while (p != null); return null; }- 红黑树的排序是根据 hash 值的大小排序的
- 如果当前节点的 hash 大于要查找节点的 hash,找左节点
- 如果当前节点的 hash 小于要查找节点的 hash,找右节点
- 如果等于
- 利用 == 和 equals 判断当前节点是否是要找的节点,如果是,返回
- 如果左节点为空,找右节点
- 如果右节点为空,找左节点
- 如果定义了比较器,根据比较结果判断下一步走左节点还是右节点
- 右节点调用 find 找到的节点不会空,说明找到了,返回
- 否则一定在左节点上
-
-
-
属性
private static final long serialVersionUID static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16 默认初始化容量 static final int MAXIMUM_CAPACITY = 1 << 30; // 最大容量 static final float DEFAULT_LOAD_FACTOR = 0.75f; // 默认加载因子 static final int TREEIFY_THRESHOLD = 8; // 树化阈值 static final int UNTREEIFY_THRESHOLD = 6; // 树退化阈值 static final int MIN_TREEIFY_CAPACITY = 64; // 最小树化容量 transient Node<K,V>[] table; // 底层节点数组 transient Set<Map.Entry<K,V>> entrySet; transient int size; // map 中键值对的数量 transient int modCount; // 修改次数 int threshold; // final float loadFactor; // hashtable 的加载因子 -
方法
public HashMap(int initialCapacity, float loadFactor) public HashMap(int initialCapacity) public HashMap() public HashMap(Map<? extends K, ? extends V> m) static final int hash(Object key) static final int tableSizeFor(int cap):将容量变成2的幂次 public int size() public boolean isEmpty() public V get(Object key):调用 getNode final Node<K,V> getNode(int hash, Object key) public boolean containsKey(Object key):调用 getNode,也需要对所有节点进行查找 public V put(K key, V value):调用 putVal final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) final Node<K,V>[] resize() final void treeifyBin(Node<K,V>[] tab, int hash)-
详细
static final int hash(Object key)static final int hash(Object key) { int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); }- 扰动算法,为了降低 hash 冲突的概率
- key 的 hashcode的高16位和低16位异或,因为数组长度默认为16,保证所有的位都参与的索引的计算,减少只计算后 16 位导致 hash 冲突的概率
-
详细
static final int tableSizeFor(int cap)static final int tableSizeFor(int cap) { int n = cap - 1; n |= n >>> 1; n |= n >>> 2; n |= n >>> 4; n |= n >>> 8; n |= n >>> 16; return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1; }- 对已经是2的幂次的容量,减1之后最高位右移了一位,通过不断的右移位或、将最高位之后的所有为都变成1,相当于都和最高位的1或了一次。最好再加1,相当于保持原来的值没有变
- 对不是2的幂次的容量,减1之后最高位没有变,将最高位之后的位全变成1后再加1,将容量变成了2的幂次
- 这种方法效率非常高
-
详细
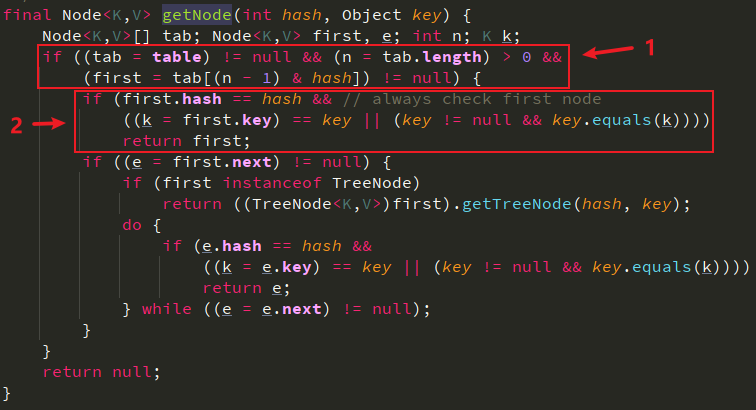
final Node<K,V> getNode(int hash, Object key)![]()
- 先判断当前的数组是否被初始化,是否有值,以及 key 对应的数组位置是否有值
- key 对应的索引位置是对 key 的 hashcode 进行 hash 之后的值和数组长度-1进行与操作得到的
tab[(n - 1) & hash]
- key 对应的索引位置是对 key 的 hashcode 进行 hash 之后的值和数组长度-1进行与操作得到的
- 判断数组该位置的链表的头结点是否是要找的节点,先比较 hash,再比较 key 的地址,地址不等再用 equals 比较
- 如果头结点不是,再判断后面的节点
- 如果头结点之后的节点是树节点,即已经变成红黑树了,调用 getTreeNode,在红黑树中寻找指定节点
- 否则遍历挨个比较,hash、地址、equals
- 先判断当前的数组是否被初始化,是否有值,以及 key 对应的数组位置是否有值
-
详细
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict)@param onlyIfAbsentif true, 不改变已存在的值@param evictif false,table 在创建模式
- 如果底层数组还没有初始化,就先调用 resize 函数进行初始化,是在第一次 put 的时候进行的初始化
- 如果数组的当前位置还没有节点,就将当前的键值对封装成头结点
- 如果已经有头结点了
- 如果头结点就是和要 put 的节点的 key 一样,记录为 e
- 如果头结点是树节点,调用 putTreeVal 向红黑树中添加该节点,如果红黑树中已经存在 key 相同的节点,返回该节点,记录为 e
- 如果头结点是链表节点
- 如果遍历到链表的尾部,在尾部新建一个节点,用当前键值对初始化,如果此时达到了树化阈值,执行 treeifyBin 将链表转化成红黑树
- 如果遍历链表找到了 key 值相同的节点,该节点为 e,停止遍历
- 如果 e 不为空,即链表或红黑树中存在与 key 相同的节点,用新值更新旧值,函数 return
- 如果 e 为空,说明在原来的基础上添加了新的节点
- 如果没有加新的节点,而是在原有的节点上修改了 value,就已经返回了,走不到这一步。如果添加了新的节点, modCount 修改次数 +1,size 键值对数+1,如果键值对数达到了阈值,进行 resize 扩容
-
详细
final Node<K,V>[] resize()- 如果原数组的容量已经 ≥ 最大容量,则将阈值设置为 Integer.MAX_VALUE,否则新容量等于旧容量的 2 倍,新阈值等于旧阈值的 2 倍。
- 如果旧容量为 0,即未初始化,新容量设为初始化容量
- 新建一个新的容量的数组,将所有元素重新计算hash值再重新分配到新数组中
- 新计算的hash值要么和原hash值相等,要么是原hash值加上原来的数组长度。设原数组长为a,新数组长度b=2a,那么table[i]中的元素要么在table[i]上要么在table[i+a]上
-
详细
final void treeifyBin(Node<K,V>[] tab, int hash)final void treeifyBin(Node<K,V>[] tab, int hash) { int n, index; Node<K,V> e; if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY) resize(); else if ((e = tab[index = (n - 1) & hash]) != null) { TreeNode<K,V> hd = null, tl = null; do { TreeNode<K,V> p = replacementTreeNode(e, null); if (tl == null) hd = p; else { p.prev = tl; tl.next = p; } tl = p; } while ((e = e.next) != null); if ((tab[index] = hd) != null) hd.treeify(tab); } }- 如果数组长度没有达到最小树化阈值,去进行扩容
- 否则,将数组节点替换成树节点,插入树中
-

 浙公网安备 33010602011771号
浙公网安备 33010602011771号