实验五:全连接神经网络手写数字识别实验
| 博客班级 | 班级链接 |
|---|---|
| 作业要求 | 作业链接 |
| 学号 | 181613146 |
【实验目的】
- 理解神经网络原理,掌握神经网络前向推理和后向传播方法;
- 掌握使用pytorch框架训练和推理全连接神经网络模型的编程实现方法。
【实验内容】
- 使用pytorch框架,设计一个全连接神经网络,实现Mnist手写数字字符集的训练与识别。
【实验报告要求】
- 修改神经网络结构,改变层数观察层数对训练和检测时间,准确度等参数的影响;
- 修改神经网络的学习率,观察对训练和检测效果的影响;
- 修改神经网络结构,增强或减少神经元的数量,观察对训练的检测效果的影响。
【实验过程与步骤】
1. 导包
import torch
import torch.nn as nn # nn全称为neural network,意思是神经网络,是torch中构建神经网络的模块
import torchvision # torchvision是独立于pytorch的关于图像操作的一些方便工具库
# 常用的图像操作,例如:随机切割,旋转,数据类型转换,图像到tensor ,numpy 数组到tensor , tensor 到 图像等
import torchvision.transforms as transforms
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
# 如果gpu可用
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
device
device(type='cuda')
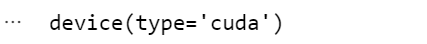
2. 设置超参数
# 设置超参数
input_size = 784 # 输入特征维数,输入节点数就为图片的大小:28×28×1
hidden_size = 500 # 隐层状态的维数
output_size = 10 # 由于数字为 0-9,因此是10分类问题,因此输出节点数为 10
num_epochs = 5 # num_epochs是模型训练迭代的总轮数(模型对训练集全部样本过一遍即为一个epoch)
batch_size = 100 # 根据数据集定义数据加载器
learning_rate = 0.001 # 定义学习率
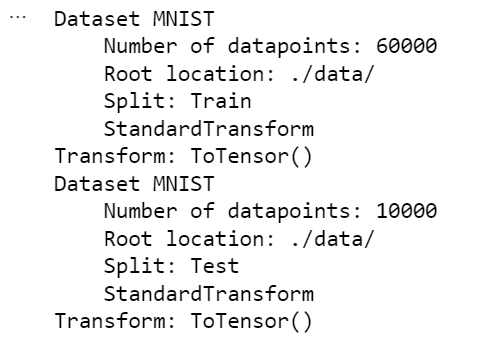
3. 下载数据集
# MNIST 下载,分为训练集和测试集共4个:训练图片,训练标签。测试图片,测试标签。即数据:图片。标签:图片对应的数字
train_dataset = torchvision.datasets.MNIST('./data/',
train=True,
transform=transforms.ToTensor(),
download=True)
print(train_dataset) # 训练集
test_dataset = torchvision.datasets.MNIST('./data/',
train=False,
transform=transforms.ToTensor())
print(test_dataset) # 测试集
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size,
shuffle=True)
test_loader = torch.utils.data.DataLoader(test_dataset,
batch_size=batch_size,
shuffle=False)
Dataset MNIST
Number of datapoints: 60000
Root location: ./data/
Split: Train
StandardTransform
Transform: ToTensor()
Dataset MNIST
Number of datapoints: 10000
Root location: ./data/
Split: Test
StandardTransform
Transform: ToTensor()
4. 查看样例数据
# 查看数据
examples = iter(test_loader) # iter() 函数用来生成迭代器。
# 100*1*28*28 # next() 返回迭代器的下一个项目。
example_data, example_target = next(examples)
for i in range(16):
# plt.subplot(行数,,列数,和谁共享x轴,和谁共享y轴)函数用于直接指定划分方式和位置进行绘图
plt.subplot(4, 4, i+1).set_title(example_target[i])
plt.imshow(example_data[i][0], 'gray') # 灰色显示
plt.tight_layout() # tight_layout 自动调整子批次参数,使子批次适合图形区域
plt.show()

5. 构建网络
# 带有一个隐藏层的全连接神经网络
class NeuralNet(nn.Module):
# 输入数据的维度,中间层的节点数,输出数据的维度
def __init__(self, input_size, hidden_size, output_size):
super(NeuralNet, self).__init__()
self.fc1 = nn.Linear(input_size, hidden_size)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(hidden_size, output_size)
def forward(self, x):
out = self.fc1(x)
out = self.relu(out)
out = self.fc2(out)
return out
model = NeuralNet(input_size, hidden_size, output_size).to(device) # 类的实例化
6. 定义损失函数和优化器
# 损失函数和优化算法
criterion = nn.CrossEntropyLoss() # nn.CrossEntropyLoss()函数计算交叉熵损失
# model.parameters()方法返回的是一个生成器generator,每一个元素是从开头到结尾的参数,parameters没有对应的key名称,
# 是一个由纯参数组成的generator,而state_dict是一个字典,包含了一个key
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
7. 模型的训练与测试
# 训练模型
total_step = len(train_loader) # 训练数据的大小,也就是含有多少个barch
LossList = [] # 记录每一个epoch的loss
AccuryList = [] # 每一个epoch的accury
for epoch in range(num_epochs):
totalLoss = 0
for i, (images, labels) in enumerate(train_loader): # 返回值和索引,这里索引即为标签
# Move tensors to the configured device
# -1 是指模糊控制的意思,即固定784列,不知道多少行
images = images.reshape(-1, 28*28).to(device)
labels = labels.to(device)
# 前向传播
outputs = model(images)
loss = criterion(outputs, labels)
totalLoss = totalLoss + loss.item()
# 反向传播和优化
optimizer.zero_grad() # 梯度清空
loss.backward() # 反向传播
optimizer.step() # 权重更新
if (i+1) % 200 == 0:
print('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'
.format(epoch+1, num_epochs, i+1, total_step, totalLoss/(i+1)))
LossList.append(totalLoss/(i+1))
# 测试模型
# 在测试阶段,不用计算梯度
with torch.no_grad():
correct = 0
total = 0
for images, labels in test_loader:
images = images.reshape(-1, 28*28).to(device)
labels = labels.to(device)
outputs = model(images)
# 这里返回两组数据,最大image_data和最大值索引,可以用torch.argmax()更为直观;这里去理解其作用为返回最大索引,即预测出来的类别。
_, predicted = torch.max(outputs.data, 1)
# 这个 _ , predicted是python的一种常用的写法,表示后面的函数其实会返回两个值
# 但是我们对第一个值不感兴趣,就写个_在那里,把它赋值给_就好,我们只关心第二个值predicted
# 比如 _ ,a = 1,2 这中赋值语句在python中是可以通过的,你只关心后面的等式中的第二个位置的值是多少
total += labels.size(0) # 更新测试图片的数量 size(0),返回行数
correct += (predicted == labels).sum().item() # 更新正确分类的图片的数量
acc = 100.0 * correct / total # 在测试集上总的准确率
AccuryList.append(acc)
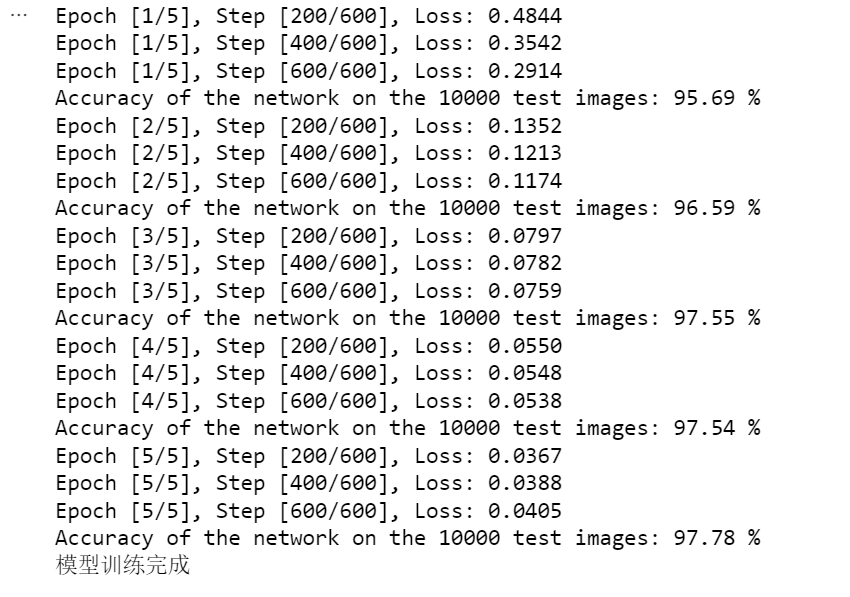
print('Accuracy of the network on the {} test images: {} %'.format(total, acc))
print("模型训练完成")
Epoch [1/5], Step [200/600], Loss: 0.4844
Epoch [1/5], Step [400/600], Loss: 0.3542
Epoch [1/5], Step [600/600], Loss: 0.2914
Accuracy of the network on the 10000 test images: 95.69 %
Epoch [2/5], Step [200/600], Loss: 0.1352
Epoch [2/5], Step [400/600], Loss: 0.1213
Epoch [2/5], Step [600/600], Loss: 0.1174
Accuracy of the network on the 10000 test images: 96.59 %
Epoch [3/5], Step [200/600], Loss: 0.0797
Epoch [3/5], Step [400/600], Loss: 0.0782
Epoch [3/5], Step [600/600], Loss: 0.0759
Accuracy of the network on the 10000 test images: 97.55 %
Epoch [4/5], Step [200/600], Loss: 0.0550
Epoch [4/5], Step [400/600], Loss: 0.0548
Epoch [4/5], Step [600/600], Loss: 0.0538
Accuracy of the network on the 10000 test images: 97.54 %
Epoch [5/5], Step [200/600], Loss: 0.0367
Epoch [5/5], Step [400/600], Loss: 0.0388
Epoch [5/5], Step [600/600], Loss: 0.0405
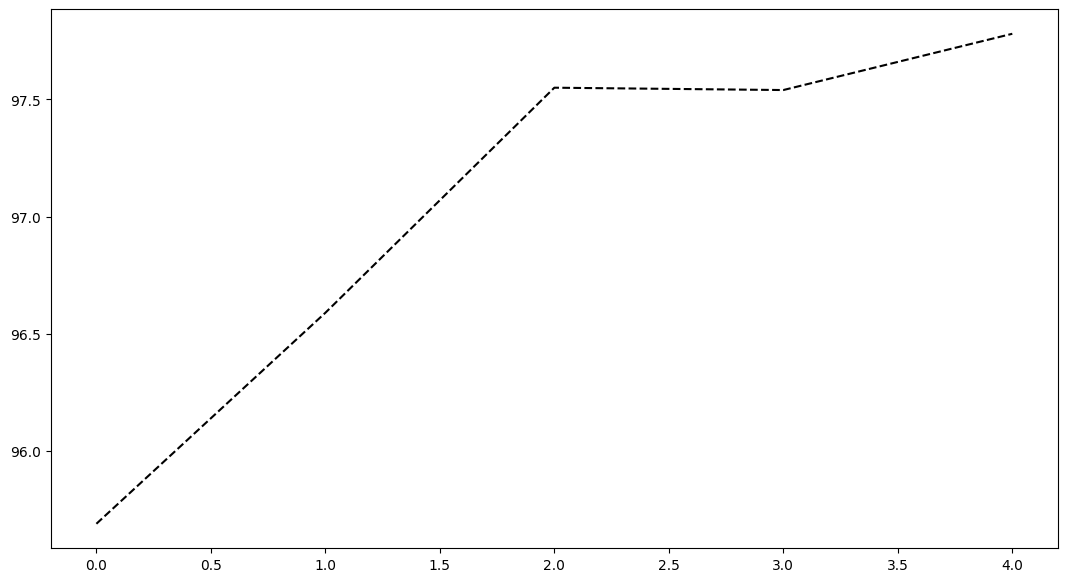
Accuracy of the network on the 10000 test images: 97.78 %
模型训练完成
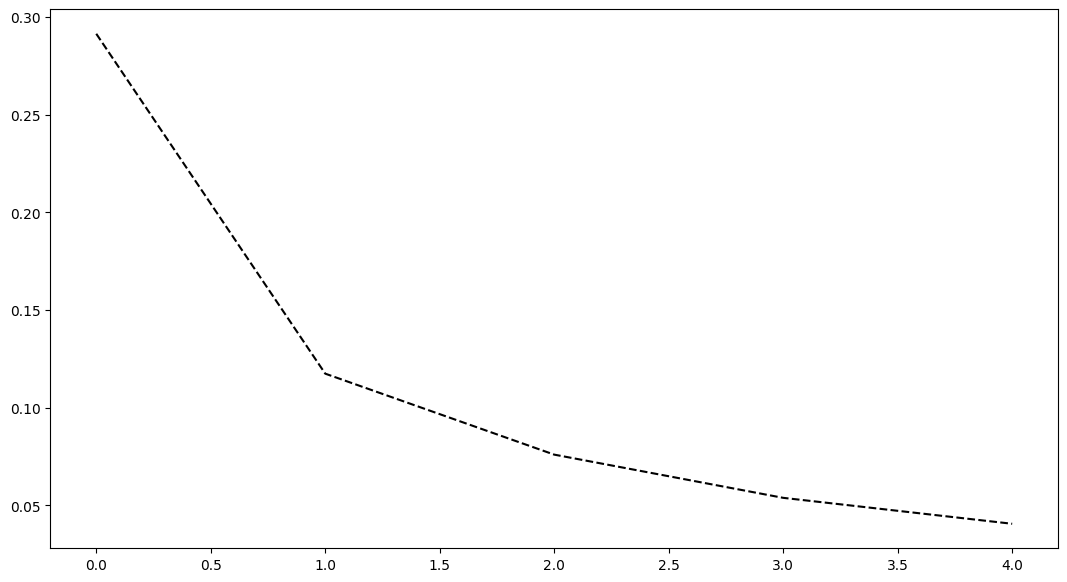
8. 绘制 loss 的变化
fig, axes = plt.subplots(nrows=1, ncols=1, figsize=(13, 7))
axes.plot(LossList, 'k--')
fig, axes = plt.subplots(nrows=1, ncols=1, figsize=(13, 7))
axes.plot(AccuryList, 'k--')
9. 使用实际例子进行验证
# 测试样例
examples = iter(test_loader)
example_data, example_targets = next(examples)
# 实际图片
for i in range(9):
plt.subplot(3, 3, i+1)
plt.imshow(example_data[i][0], cmap='gray')
plt.show()
# 结果的预测
images = example_data.reshape(-1, 28*28).to(device)
labels = example_targets.to(device)
# 正向传播以及损失的求取
outputs = model(images)
# 将 Tensor 类型的变量 example_targets 转为 numpy 类型的,方便展示
print("上面三张图片的真实结果:", example_targets[0:9].detach().numpy())
# 将得到预测结果
# 由于预测结果是 N×10 的矩阵,因此利用 np.argmax 函数取每行最大的那个值,最为预测值
print("上面三张图片的预测结果:", np.argmax(outputs[0:9].cpu().detach().numpy(), axis=1))

上面三张图片的真实结果: [7 2 1 0 4 1 4 9 5]
上面三张图片的预测结果: [7 2 1 0 4 1 4 9 5]


 浙公网安备 33010602011771号
浙公网安备 33010602011771号