hive的分桶原理
套话之分桶的定义:
分桶表是对列值取哈希值的方式,将不同数据放到不同文件中存储。对于 hive 中每一个表、分区都可以进一步进行分桶。
列的哈希值除以桶的个数来决定每条数据划分在哪个桶中。(网上其它定义更详细,有点绕,结合后面实例)
适用场景:数据抽样( sampling )、map-join
干货之分桶怎么分:
1.开启支持分桶
set hive.enforce.bucketing=true;
默认:false;设置为 true 之后,mr 运行时会根据 bucket 的个数自动分配 reduce task 个数。
(用户也可以通过 mapred.reduce.tasks 自己设置 reduce 任务个数,但分桶时不推荐使用)
注意:一次作业产生的桶(文件数量)和 reduce task 个数一致。
2.往分桶表中加载数据
insert into table bucket_table select columns from tbl;
insert overwrite table bucket_table select columns from tbl;
3.桶表 抽样
select * from bucket_table tablesample(bucket 1 out of 4 on columns);
TABLESAMPLE 语法:
TABLESAMPLE(BUCKET x OUT OF y)
x:表示从哪个 bucket 开始抽取数据
y:必须为该表总 bucket 数的倍数或因子
4.分桶实例(详解)
具体如下:
1.启动hive(远程一体化模式):①service iptables stop // ② service mysqld start // ③hive ---service metastore //④ hive(老套路)
2.准备:在node03节点的root/hivedata目录下 创建一个数据文件ft
①vim ft

1 zhang 12 2 lisi 34 3 wange 23 4 zhouyu 15 5 guoji 45 6 xiafen 48 7 yanggu 78 8 liuwu 41 9 zhuto 66 10 madan 71 11 sichua 89
注意:这里的数据间是用制表符'\t'来分隔的,后面在建表的时候要注意 terminated by '\t'; 不然导入表中的数据因为格式不符出现'null'
②在数据库heh.db中建表:
hive> CREATE TABLE ft( id INT, name STRING, age INT)
> ROW FORMAT DELIMITED FIELDS TERMINATED BY'\t';
OK
Time taken: 0.216 seconds
hive> load data local inpath'/root/hivedata/ft' into table ft;
Loading data to table hehe.ft
Table hehe.ft stats: [numFiles=1, totalSize=127]
OK
Time taken: 1.105 seconds
hive> select *from ft;
OK
1 zhang 12
2 lisi 34
3 wange 23
4 zhouyu 15
5 guoji 45
6 xiafen 48
7 yanggu 78
8 liuwu 41
9 zhuto 66
10 madan 71
11 sichua 89
NULL NULL NULL
Time taken: 0.229 seconds, Fetched: 12 row(s)
再创建一张分桶表fentong并把ft的数据插入到fentong:
hive> create table fentong(
> id int,
> name string,
> age int,)clustered by(age) into 4 buckets
> row format delimited fields terminated by ',';
创建一张表:它以字段age来划分成4个桶
插入数据:
hive> insert into table fentong select name,age from ft;
ok! 现在分桶表中出现之前创建的数据:select * from fentong
③执行抽样: select id, name, age from fentong tablesample(bucket 1 out of 4 on age);
网上很多案例教程说的非常绕,一时很难离清楚,现分享如下通俗 易懂的教程:
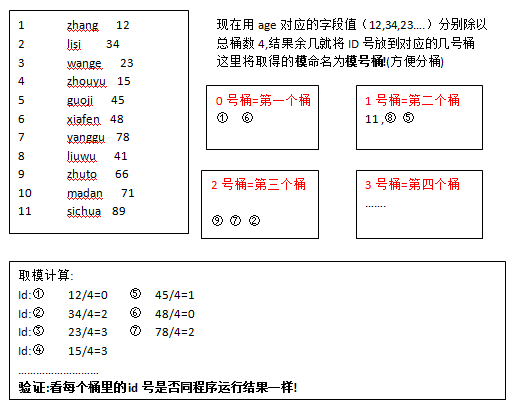
怎么分:①在前面创建分桶表的时候有这样语句:age int,)clustered by(age) into 4 buckets 说明本案例是以年龄age来划分成4个桶;
分桶的数据怎么分到四个桶:它是将表中对应的字段值(比如age)分别来除以桶的个数4,结果取余数(也就是取模),若余数为0就放到1号桶,余数为1就放到2号桶
余数为2就放到3号桶,余数为3就放到4号桶
②这句话怎么理解:select id, name, age from psnbucket tablesample(bucket 2 out of 4 on age);
它是说:将你的数据划分成4个桶,取四个桶中的第一个桶的数据
③运行程序
hive> select id, name, age from fentong tablesample(bucket 1 out of 4 on age); OK NULL NULL NULL 6 xiafen 48 1 zhang 12 hive> select id, name, age from fentong tablesample(bucket 2 out of 4 on age); OK 11 sichua 89 8 liuwu 41 5 guoji 45 hive> select id, name, age from fentong tablesample(bucket 3 out of 4 on age); OK 9 zhuto 66 7 yanggu 78 2 lisi 34
④推算过程:
作者:少帅
出处:少帅的博客--http://www.cnblogs.com/wang3680
您的支持是对博主最大的鼓励,感谢您的认真阅读。
本文版权归作者所有,欢迎转载,但请保留该声明。
 支付宝
支付宝  微信
微信

 浙公网安备 33010602011771号
浙公网安备 33010602011771号