JAVA---Set集合底层源码分析
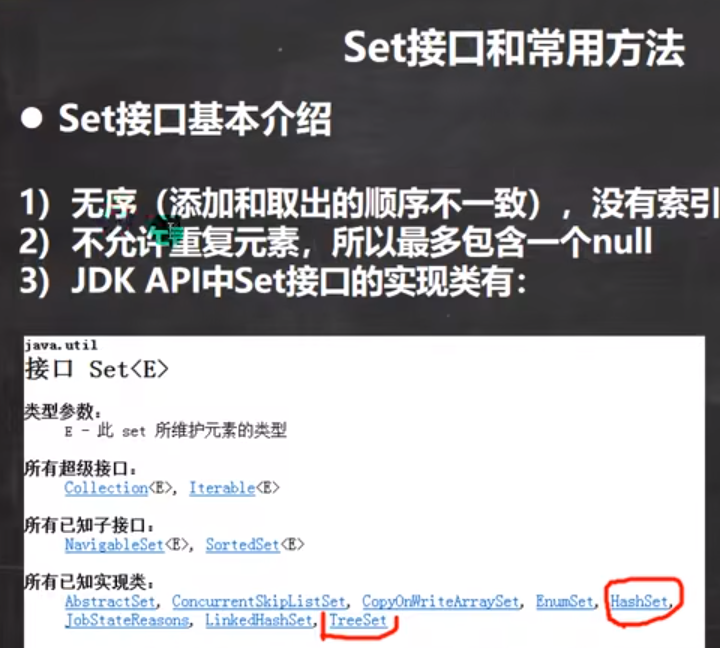
1.Set集合介绍


常用方法,添加,删除和遍历
Set接口对象不能使用索引获取,他是无序的,没有索引。
set集合无序,所以没有修改和查看某个元素,因为某个位置上是什么元素是不确定,但是可以通过迭代器或增强for遍历所有元素。
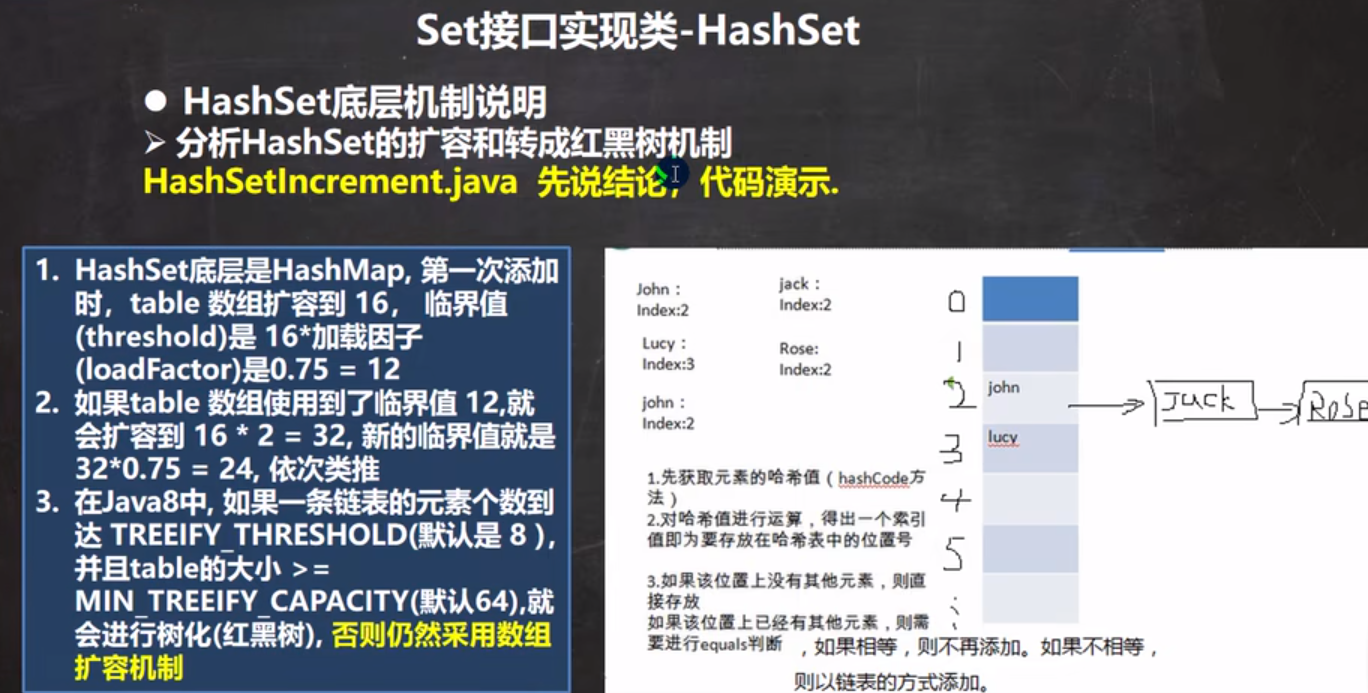
1.1HashSet

当他的链表到达一定量的时候,而且满足数组的大小,在某一个范围的时候,他就会把这个链表进行一个树化,变成一棵红黑树

4.执行 putVal()


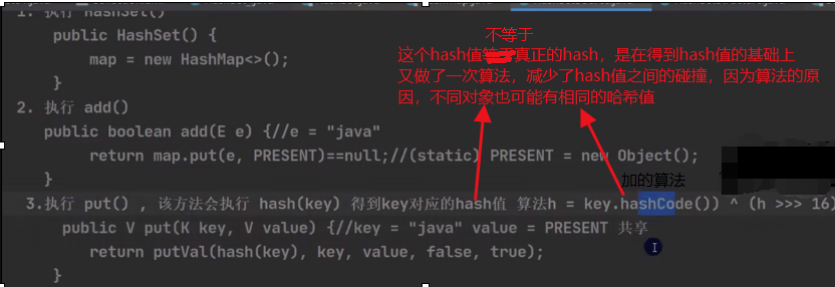
1.1.1 为什么要将hashCode值右移16位并且与原来的hashCode值进行^(按位异或)操作?


1.1.2 为什么要将数组的最大索引(n-1)和hash进行&运算?为什么不用hash%n
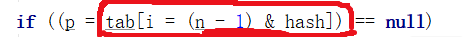
问题一:(n-1)数组的最大索引和hash进行&运算,结果一定<=他俩中的最小值;即 (n-1) & hash的值i,一定是在长度内的,不会越界,且坑位受hash的散列能力影响
n数组的长度一定是2的次幂,才能保证横向散列的能力,让key能够松散的填入tab数组坑中。所以hashmap第一次扩容为16,之后每次扩容为原来的2倍
问题二:按位与&运算性能比%(取模)高
------------------------------------------
链表树化(treeifyBin)发生在,链表长度大于8
并且treeifyBin方法内会判断,只有在数组长度大于等于64才会真去树化,否则会先扩容
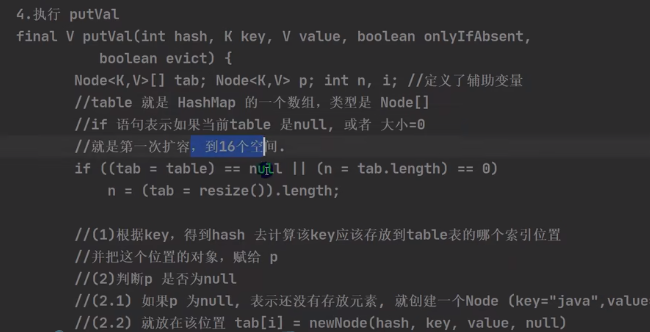
源码分析(忽略无关代码)
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
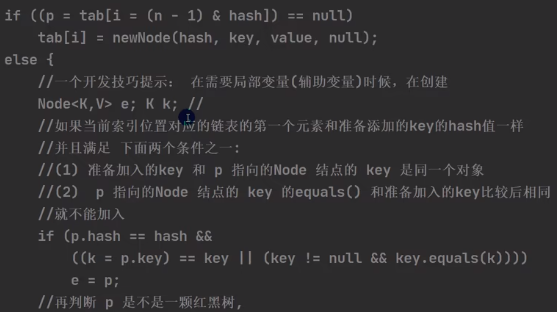
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {
Node<K,V>[] tab ; int n, i;
Node<K,V> p(指向链表头节点);
// table未初始化或者长度为0,进行扩容
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// 确定元素存放在哪个桶中,桶为空,新生成结点放入桶中
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
// 桶中已经存在元素 : p(指向链表头节点)
else {
Node<K,V> e; K k;
// 比较桶中第一个元素p与要插入元素的key是否相等,key相等则此次put为覆盖操作
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
// 将第一个元素赋值给e,用e来记录
e = p;
// key不相等;头节点p为红黑树结点,则此次put为向红黑树中插入节点
else if (p instanceof TreeNode)
// 放入树中
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
// key不相等;头节点p为链表结点,则此次put为向链表中插入节点(树化发生在此处)
else {
// 遍历链表,只在两种情况下才会跳出循环
for (int binCount = 0; ; ++binCount) {
//第一种:已经遍历到尾部,在最后插入新节点跳出,因节点数量+1 判断是否需要树化
if ((e = p.next) == null) {
// 在尾部插入新结点
p.next = newNode(hash, key, value, null);
// 判断是否需要树化
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
// 跳出循环
break;
}
// 第二种:e指向的节点与要插入节点的key相同,此次put为覆盖操作
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
// 相等,跳出循环
break;
// 用于遍历桶中的链表,与前面的e = p.next组合,可以遍历链表
p = e;