
大数据--sqoop
由于公司的部分用户观看数据:直播、点播、回看都储存再hive数据仓库。众所周知,hive的查询速度是个很大的问题。在做用户画像,一些月常,周常,日常的 数据分析报告的,以及一些用户观看查询等操作的时候,十分的不方便,而且也不便于放在metabase等bi上做数据展示。所以,需要定期将hive的数据导入0racle中。
之前是以月为维度人工导出数据(insert成文件+scp的oracle服务器+ctl写入oracle),十分的费人力,而且效率极低。重要的是,不能实现每天导入,太浪费时间。所以考虑以脚本的形式导数据,然后crontab定时任务。但是,用python脚本操作的话,首先数据量太大,需要分批操作,然后再分析写入oracle的时候经常出现连接自动断开的问题,百度得到的解释是oracle连接池满了。额,不懂,放弃。
再和群里同仁交流过后,得到了两个看似不错的方法,kettle,sqoop。两个都应该算是大数据的工具吧,前者是专业是ETL工具,操作类似simulink(matlbe的工具包),后者是专门从事hadoop集群和关系型数据库之间数据传输的工具,由于后者适合的数据量级更大。所以优先尝试了后者。
sqoop安装
sqoop安装还算简单,再服务器上解压安装文件。sqoop安装目录如下:
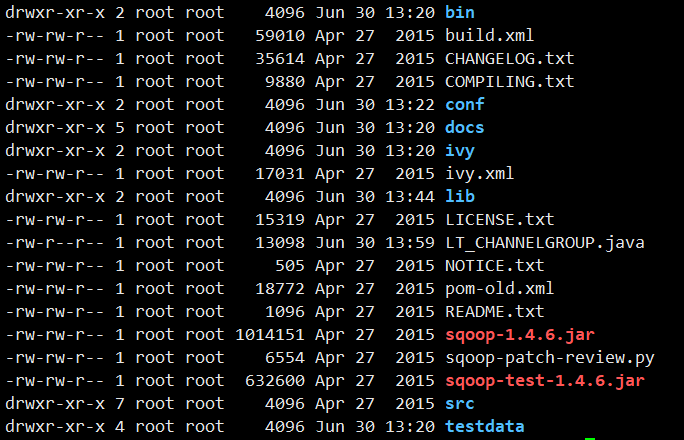
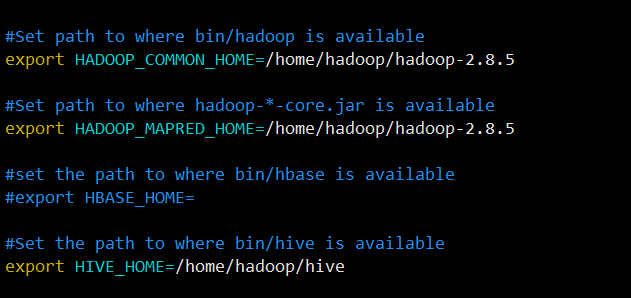
修改配置文件conf/sqoop-env.sh(我自己改过名),指定hadoop和hive。
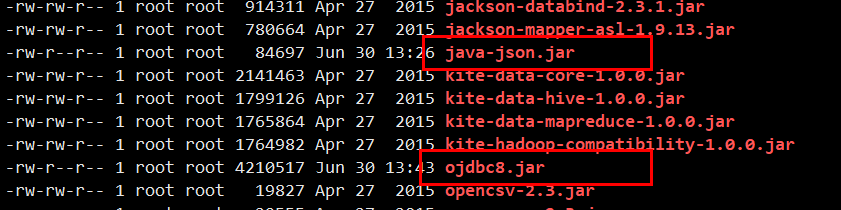
lib目录添加ojdbc和java_json的驱动包。
sqoop使用
sqoop的使用网上有很大教程和文档。我主要的b站上看了尚硅谷的sqoop课程,参考尚硅谷的文档。
oracle导入hdfs
bin/sqoop import \ --connect jdbc:mysql://hadoop102:3306/company \ --username root \ --password 000000 \ --table staff \ --target-dir /user/company \ --num-mappers 1 \ --fields-terminated-by "\t" # 以下选加 --query 'select name,sex from staff where id <=1 and $CONDITIONS --columns id,sex \ --where "id=1"
oracle导入hive
bin/sqoop import \ --connect jdbc:mysql://hadoop102:3306/company \ --username root \ --password 000000 \ --table staff \ --num-mappers 1 \ --hive-import \ --fields-terminated-by "\t" \ --hive-overwrite \ --hive-table staff_hive
hive导出oracle
bin/sqoop export \ --connect jdbc:mysql://hadoop102:3306/company \ --username root \ --password 000000 \ --table staff \ --num-mappers 1 \ --export-dir /user/hive/warehouse/staff_hive \ --input-fields-terminated-by "\t"
注意事项:
基本的语法就这些,下面有几条注意事项,都是自己踩的坑。
1) 导出数据时,oracle上的表要建好。
2) 连接oracle的话,oracle的表明要大写。
3)sqoop导出数据时,只支持全量导出或增量导出。无法选定列,如需制定列,可以再hive端处理分析合适后再用sqoop导出。
4) 尚硅谷文档中的sqoop脚本执行的方法不是很好用,建议直接写在shell脚本中执行。
性能比较
简单和之前手动操作做了下比较。大概1.5亿条数据,之前在手动操作时,从上午9点多跑到下午3点左右,用sqoop的一个多小时。效率提升了将近5倍,而且可以定时执行,省去了人力。
目前的操作时,以日为维度每天早上执行。在shell脚本中,先是create table as 创建临时表选择好列,然后sqoop 传输,最后 drop table 临时表。
其他
补充一点在尝试过程中遇到的hive的问题。之前我们自己生成的hive数据(内部表)的底层文件全都是deflate压缩文件,sqoop是直接拿底层文件做解析传输,所以压缩文件无法操作。查询了一些资料,需要更改hive的配置文件,有一个reduce输出自动压缩的选择需要设置为false。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号