Python机器学习设计——笑脸识别和口罩识别
一、选题背景
在学习了深度学习案例——猫狗图像识别,想试着实现对人脸面部表情的识别和佩戴口罩识别,进一步熟悉Keras的基本用法与网络框架。
二、机器学习案例设计方案
1.数据集来源
①笑脸数据集:
使用GENKI数据集其中的GENKI-4K,GENKI数据集是由加利福尼亚大学的机器概念实验室收集。该数据集包含GENKI-R2009a,GENKI-4K,GENKI-SZSL三个部分.GENKI-R2009a包含11159个图像,GENKI-4K包含4000个图像,分为“笑”和“不笑”两种,每个图片的人脸的尺度大小,姿势,光照变化,头的转动等都不一样,专门用于做笑脸识别.GENKI-SZSL包含3500个图像,这些图像包括广泛的背景,光照条件,地理位置,个人身份和种族等。
②口罩识别数据集:
武汉大学国家多媒体软件工程技术研究中心
2.采用的机器学习框架描述
卷积神经网络(Convolutional Neural Network, CNN):卷积神经网络是深度学习技术中极具代表的网络结构之一,在图像处理领域取得了很大的成功,在国际标准的 ImageNet 数据集上,许多成功的模型都是基于 CNN 的。
Keras:Keras是一个模型级( model-level)的库,为开发深度学习模型提供了高层次的构建模块。它不处理张量操作、求微积分等基础的运算,而是依赖--个专门的、高度优化的张量库来完成这些运算。这个张量库就是Keras的后端引擎(backend engine),如TensorFlow等。
TensorFlow :TensorFlow 是一个开源机器学习框架,具有快速、灵活并适合产品级大规模应用等特点,让每个开发者和研究者都能方便地使用人工智能来解决多样化的挑战。
3.涉及到的技术难点与解决思路
训练被强制中断 解决思路:使用数据集增强技术来扩大样本数量,以生产更多的训练数据
一些第三方库没有此模块的问题 解决思路:降版本或者使用功能相同的新模块
三、机器学习实现的实现步骤
一、笑脸识别
1.修改原数据集图片的名称,方便我们使用
1 import os 2 import sys 3 def rename(): 4 path=input("请输入路径:") 5 name=input("请输入开头名:") 6 startNumber=input("请输入开始数:") 7 fileType=input("请输入后缀名:") 8 print("正在生成以"+name+startNumber+fileType+"迭代的文件名") 9 count=0 10 filelist=os.listdir(path) 11 for files in filelist: 12 Olddir=os.path.join(path,files) 13 if os.path.isdir(Olddir): 14 continue 15 Newdir=os.path.join(path,name+str(count+int(startNumber))+fileType) 16 os.rename(Olddir,Newdir) 17 count+=1 18 print("一共修改了"+str(count)+"个文件") 19 rename()


2.复制文件形成我们所需要的数据集目录结构
1 import os, shutil 2 # 数据集目录所在的路径 3 original_dataset_dir1 = 'E:\\jupyter\\识别\\data\\train_folder\\1' #笑脸 4 original_dataset_dir0 = 'E:\\jupyter\\识别\\data\\train_folder\\0' #非笑脸 5 # 模仿猫狗大战识别 建立数据集目录结构 6 base_dir = 'E:\\jupyter\\识别\\data1' 7 os.mkdir(base_dir) 8 9 # # 训练、验证、测试数据集的目录 10 train_dir = os.path.join(base_dir, 'train') 11 os.mkdir(train_dir) 12 validation_dir = os.path.join(base_dir, 'validation') 13 os.mkdir(validation_dir) 14 test_dir = os.path.join(base_dir, 'test') 15 os.mkdir(test_dir) 16 17 # 笑训练图片所在目录 18 train_smile_dir = os.path.join(train_dir, 'smile') 19 os.mkdir(train_smile_dir) 20 21 # 不笑训练图片所在目录 22 train_unsmile_dir = os.path.join(train_dir, 'unsmile') 23 os.mkdir(train_unsmile_dir) 24 25 # 笑验证图片所在目录 26 validation_smile_dir = os.path.join(validation_dir, 'smile') 27 os.mkdir(validation_smile_dir) 28 29 # 不笑验证数据集所在目录 30 validation_unsmile_dir = os.path.join(validation_dir, 'unsmile') 31 os.mkdir(validation_unsmile_dir) 32 33 # 笑测试数据集所在目录 34 test_smile_dir = os.path.join(test_dir, 'smile') 35 os.mkdir(test_smile_dir) 36 37 # 不笑测试数据集所在目录 38 test_unsmile_dir = os.path.join(test_dir, 'unsmile') 39 os.mkdir(test_unsmile_dir) 40 41 # 将前1000张笑图像复制到train_smile_dir 42 fnames = ['smile{}.jpg'.format(i) for i in range(1000)] 43 for fname in fnames: 44 src = os.path.join(original_dataset_dir1, fname) 45 dst = os.path.join(train_smile_dir, fname) 46 shutil.copyfile(src, dst) 47 48 # 将下500张笑图像复制到validation_smile_dir 49 fnames = ['smile{}.jpg'.format(i) for i in range(1000, 1500)] 50 for fname in fnames: 51 src = os.path.join(original_dataset_dir1, fname) 52 dst = os.path.join(validation_smile_dir, fname) 53 shutil.copyfile(src, dst) 54 55 # 将下500张笑图像复制到test_smile_dir 56 fnames = ['smile{}.jpg'.format(i) for i in range(1000, 1500)] 57 for fname in fnames: 58 src = os.path.join(original_dataset_dir1, fname) 59 dst = os.path.join(test_smile_dir, fname) 60 shutil.copyfile(src, dst) 61 62 # 将前1000张不笑图像复制到train_unsmile_dir 63 fnames = ['unsmile{}.jpg'.format(i) for i in range(1000)] 64 for fname in fnames: 65 src = os.path.join(original_dataset_dir0, fname) 66 dst = os.path.join(train_unsmile_dir, fname) 67 shutil.copyfile(src, dst) 68 69 # 将500张不笑图像复制到validation_unsmile_dir 70 fnames = ['unsmile{}.jpg'.format(i) for i in range(700, 1200)] 71 for fname in fnames: 72 src = os.path.join(original_dataset_dir0, fname) 73 dst = os.path.join(validation_unsmile_dir, fname) 74 shutil.copyfile(src, dst) 75 76 # 将500张不笑图像复制到test_unsmile_dir 77 fnames = ['unsmile{}.jpg'.format(i) for i in range(700, 1200)] 78 for fname in fnames: 79 src = os.path.join(original_dataset_dir0, fname) 80 dst = os.path.join(test_unsmile_dir, fname) 81 shutil.copyfile(src, dst)
3.经过处理后的数据集的目录结构

4.设置路径
1 train_smile_dir="data1/train/smile/" 2 train_umsmile_dir="data1/train/unsmile/" 3 test_smile_dir="data1/test/smile/" 4 test_umsmile_dir="data1/test/unsmile/" 5 validation_smile_dir="data1/validation/smile/" 6 validation_unsmile_dir="data1/validation/unsmile/" 7 train_dir="data1/train/" 8 test_dir="data1/test/" 9 validation_dir="data1/validation/"
5.检查一下每个分组(训练 / 测试 / 验证)中分别包含多少张图像
1 import os 2 print('笑脸数据训练图片数量:', len(os.listdir(train_smile_dir))) 3 print('非笑脸数训练据图片数量:', len(os.listdir(train_umsmile_dir))) 4 print('笑脸数据测试图片数量:', len(os.listdir(test_smile_dir))) 5 print('非笑脸数据训练图片数量:', len(os.listdir(test_umsmile_dir))) 6 print('笑脸验证图片数量:', len(os.listdir(validation_smile_dir))) 7 print('非笑脸验证图片数量:', len(os.listdir(validation_unsmile_dir)))

6.搭建卷积神经网络
1 #创建模型 2 from keras import layers 3 from keras import models 4 model = models.Sequential() 5 """ 6 Output shape计算公式:(输入尺寸-卷积核尺寸/步长+1 7 对CNN模型,Param的计算方法如下: 8 卷积核长度*卷积核宽度*通道数+1)*卷积核个数 9 输出图片尺寸:150-3+1=148*148 10 参数数量:32*3*3*3+32=896 11 """ 12 model.add(layers.Conv2D(32, (3, 3), activation='relu',input_shape=(150, 150, 3))) 13 model.add(layers.MaxPooling2D((2, 2))) # 输出图片尺寸:148/2=74*74 14 15 # 输出图片尺寸:74-3+1=72*72,参数数量:64*3*3*32+64=18496 16 #32是第1个卷积层的输出的通道数 17 model.add(layers.Conv2D(64, (3, 3), activation='relu')) 18 model.add(layers.MaxPooling2D((2, 2)))# 输出图片尺寸:72/2=36*36 19 20 #Output Shape的输出为36 21 # 输出图片尺寸:36-3+1=34*34,参数数量:128*3*3*64+128=73856 22 model.add(layers.Conv2D(128, (3, 3), activation='relu')) 23 model.add(layers.MaxPooling2D((2, 2)))# 输出图片尺寸:34/2=17*17 24 25 # 输出图片尺寸:17-3+1=15*15,参数数量:128*3*3*128+128=147584 26 model.add(layers.Conv2D(128, (3, 3), activation='relu'))# 输出图片尺寸:15/2=7*7 27 model.add(layers.MaxPooling2D((2, 2))) 28 29 model.add(layers.Flatten())# 多维转为一维:7*7*128=6272 30 model.add(layers.Dense(512, activation='relu'))# 参数数量:6272*512+512=3211776 31 model.add(layers.Dense(1, activation='sigmoid'))# 参数数量:512*1+1=513
从输出可以看出神经网络在dense_3 (Dense)层的参数总数达到300多万
1 model.summary()

7.编译模型
1 # 编译模型 2 # RMSprop 优化器。因为网络最后一层是单一sigmoid单元, 3 # 所以使用二元交叉熵作为损失函数 4 5 from keras import optimizers 6 model.compile(loss='binary_crossentropy', 7 optimizer=optimizers.RMSprop(lr=1e-4), 8 metrics=['acc'])
8.使用 ImageDataGenerator 从目录中读取样本数据
1 #图像在输入神经网络之前进行数据处理,建立训练和验证数据 2 from keras.preprocessing.image import ImageDataGenerator 3 4 #归一化 5 train_datagen = ImageDataGenerator(rescale=1./255) 6 validation_datagen=ImageDataGenerator(rescale=1./255) 7 test_datagen = ImageDataGenerator(rescale=1./255) 8 9 train_generator = train_datagen.flow_from_directory( 10 # 目标文件目录 11 train_dir, 12 #输入训练图像尺寸,所有图片的size必须是150x150 13 target_size=(150, 150), 14 batch_size=20, 15 # 因为我们使用二元交叉熵损失,我们需要二元标签 16 class_mode='binary') 17 18 validation_generator = test_datagen.flow_from_directory( 19 validation_dir, 20 target_size=(150, 150), 21 batch_size=20, 22 class_mode='binary') 23 test_generator = test_datagen.flow_from_directory( 24 test_dir, 25 target_size=(150, 150), 26 batch_size=20, 27 class_mode='binary')

1 for data_batch, labels_batch in train_generator: 2 print('data batch shape:', data_batch.shape) 3 print('labels batch shape:', labels_batch.shape) 4 break #生成器不会停止,会循环生成这些批量,所以我们就循环生成一次批量,打印大小出来看一下就可以了

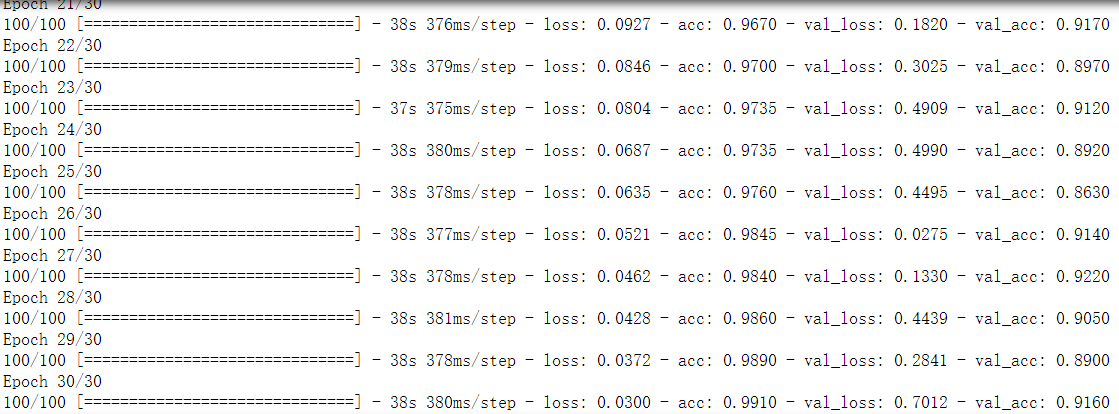
9.训练模型(30次)
可以看出训练集精度(acc):0.9910 验证集精度(val_acc):0.9160
造成的差距只要是由于过拟合造成的,接下来将通过数据增强来降低过拟合的程度。
1 #训练模型30轮次,可以修改epochs的值 2 history = model.fit_generator( 3 train_generator, 4 steps_per_epoch=100, 5 epochs=30, 6 validation_data=validation_generator, 7 validation_steps=50)
1 #将训练过程产生的数据保存为h5文件 2 model.save('smile_and_unsmile_30epoch.h5')
1 train_generator.class_indices 2 #0笑 1不笑

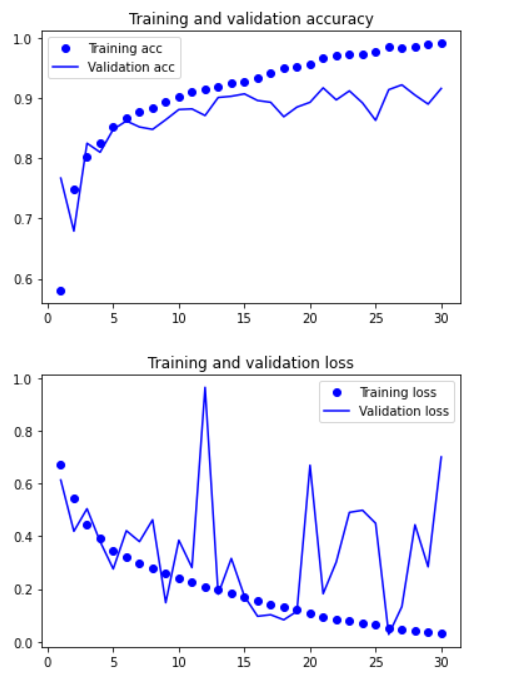
10.绘制训练过程中的损失曲线和精度曲线
1 import matplotlib.pyplot as plt 2 3 acc = history.history['acc'] 4 val_acc = history.history['val_acc'] 5 loss = history.history['loss'] 6 val_loss = history.history['val_loss'] 7 8 epochs = range(1, len(acc) + 1) 9 10 plt.plot(epochs, acc, 'bo', label='Training acc') 11 plt.plot(epochs, val_acc, 'b', label='Validation acc') 12 plt.title('Training and validation accuracy') 13 plt.legend() 14 15 plt.figure() 16 17 plt.plot(epochs, loss, 'bo', label='Training loss') 18 plt.plot(epochs, val_loss, 'b', label='Validation loss') 19 plt.title('Training and validation loss') 20 plt.legend() 21 22 plt.show() 23 24 #训练精度随着时间线性增加,直到接近100%
11.尝试修改图片大小看是否成功
1 import matplotlib.pyplot as plt 2 from PIL import Image 3 import os.path 4 5 def convertjpg(jpgfile,outdir,width=150,height=150):#将图片缩小到(150,150)的大小 6 img=Image.open(jpgfile) 7 try: 8 new_img=img.resize((width,height),Image.BILINEAR) 9 new_img.save(os.path.join(outdir,os.path.basename(jpgfile))) 10 except Exception as e: 11 print(e) 12 13 jpgfile = 'E:\\jupyter\\识别\\smile5.jpg'#读取原图像 14 15 #图像大小改变到(150,150),输出路径只需要指出目录名,文件名保持原来名称 16 convertjpg(jpgfile,"E:\\jupyter\\识别\\data1") 17 18 img_scale = plt.imread('E:\\jupyter\\识别\\data1\\smile5.jpg') 19 plt.imshow(img_scale) #显示改变图像大小后的图片确实变到了(150,150)大小

12.单张图片进行判断图片是笑还是不笑
1 # 单张图片进行判断 是笑脸还是非笑脸 2 import cv2 3 from keras.preprocessing import image 4 from keras.models import load_model 5 import numpy as np 6 import matplotlib.pyplot as plt 7 #加载模型 8 model = load_model('smile_and_unsmile_30epoch.h5') 9 #本地图片路径 10 # img_path = ('E:\\jupyter\\识别\\data1\\test\\smile\\smile1061.jpg') 11 img_path = ('E:\\jupyter\\识别\\data1\\test\\unsmile\\unsmile717.jpg') 12 #读取图像并调整其大小为(150,150,3) 13 img = image.load_img(img_path,target_size=(150,150)) 14 # 将其转换为具有形状的Numpy数组(150、150、3) 15 img_tensor = image.img_to_array(img)/255 16 # 将其形态变为(150,150,150,3)的形状 17 img_tensor = np.expand_dims(img_tensor, axis=0) 18 #取图片信息 19 prediction =model.predict(img_tensor) 20 #输出识别率 21 print(prediction) 22 if prediction>0.5: 23 print('不笑') 24 else: 25 print('笑') 26 #显示图片 27 plt.imshow(img)

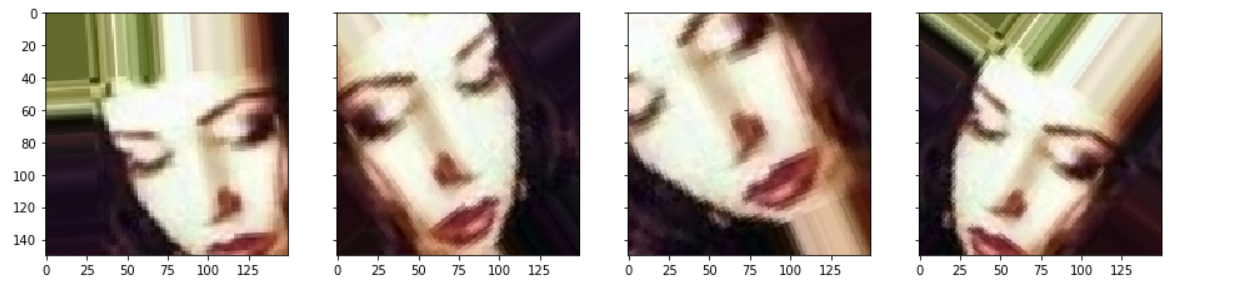
13.数据增强训练,利用ImageDataGenerator实现数据增强
1 import os 2 import matplotlib.pyplot as plt 3 #这是带有图像预处理实用程序的模块 4 from keras.preprocessing import image 5 figure,ax = plt.subplots(nrows=1, ncols=4, sharex=True, sharey=True,figsize=(16,10)) 6 datagen = ImageDataGenerator( 7 rotation_range=40, #图像随机旋转角度范围 8 width_shift_range=0.2, #图片在水平方向上平移的比例 9 height_shift_range=0.2, #图片在垂直方向上平移的比例 10 shear_range=0.2, #随机错切变换的角度 11 zoom_range=0.2, #图像随机缩放的范围 12 horizontal_flip=True, #随机将一半图像水平翻转 13 fill_mode='nearest') #填充创建像素的一种方法 14 #获取所有样本文件名称 15 fnames = [os.path.join(train_smile_dir, fname) for fname in os.listdir(train_smile_dir)] 16 #选择任意一张图片进行图像增强 17 img_path = fnames[9] #fnames下标可以选择不同的图片文件 18 #读取图像并调整其大小为(150,150,3) 19 img = image.load_img(img_path, target_size=(150, 150)) 20 # 将其转换为具有形状的Numpy数组(150、150、3) 21 x = image.img_to_array(img) 22 # 将其形态变为(150,150,150,3)的形状 23 x = x.reshape((1,) + x.shape) 24 # 下面的.flow()命令生成一批随机转换的图像。 25 # 它将无限循环,所以我们需要在某个时刻“打破”循环! 26 i = 0 27 for batch in datagen.flow(x, batch_size=1): 28 ax = ax.flatten() # 将子图从多维变成一维 29 plt.figure(i) 30 imgplot = ax[i-1].imshow(image.array_to_img(batch[0]), cmap='Greys', interpolation='nearest') 31 i += 1 32 if i % 4 == 0: 33 break 34 plt.show() #绘制增强后的图像

1 figure,ax = plt.subplots(nrows=1, ncols=4, sharex=True, sharey=True,figsize=(16,10)) 2 #获取所有样本文件名称 3 fnames = [os.path.join(train_umsmile_dir, fname) for fname in os.listdir(train_umsmile_dir)] 4 #选择任意一张图片进行图像增强 5 img_path = fnames[9] #fnames下标可以选择不同的图片文件 6 #读取图像并调整其大小为(150,150,3) 7 img = image.load_img(img_path, target_size=(150, 150)) 8 # 将其转换为具有形状的Numpy数组(150、150、3) 9 x = image.img_to_array(img) 10 # 将其形态变为(150,150,150,3)的形状 11 x = x.reshape((1,) + x.shape) 12 # 下面的.flow()命令生成一批随机转换的图像。 13 # 它将无限循环,所以我们需要在某个时刻“打破”循环! 14 i = 0 15 for batch in datagen.flow(x, batch_size=1): 16 ax = ax.flatten() # 将子图从多维变成一维 17 plt.figure(i) 18 imgplot = ax[i-1].imshow(image.array_to_img(batch[0]), cmap='Greys', interpolation='nearest') 19 i += 1 20 if i % 4 == 0: 21 break 22 plt.show() #绘制增强后的图像 23 24 """ 25 虽然使用了数据增强技术,但是从输出的图像来看,图片之间还是有较大相似度的, 26 因为它们均来自同一张原始图片,并没有提供新的信息。 27 为了尽可能地消除过拟合,可以在模型中增加一个Dropout层,添加到密集连接分类 28 器前 29 """
1 #在紧密连接的分类器之前为模型添加一个Dropout层 2 model = models.Sequential() 3 model.add(layers.Conv2D(32, (3, 3), activation='relu', 4 input_shape=(150, 150, 3))) 5 model.add(layers.MaxPooling2D((2, 2))) 6 model.add(layers.Conv2D(64, (3, 3), activation='relu')) 7 model.add(layers.MaxPooling2D((2, 2))) 8 model.add(layers.Conv2D(128, (3, 3), activation='relu')) 9 model.add(layers.MaxPooling2D((2, 2))) 10 model.add(layers.Conv2D(128, (3, 3), activation='relu')) 11 model.add(layers.MaxPooling2D((2, 2))) 12 model.add(layers.Flatten()) 13 model.add(layers.Dropout(0.5)) 14 model.add(layers.Dense(512, activation='relu')) 15 model.add(layers.Dense(1, activation='sigmoid'))
1 # 编译模型 2 # RMSprop 优化器。因为网络最后一层是单一sigmoid单元, 3 # 所以使用二元交叉熵作为损失函数 4 model.compile(loss='binary_crossentropy', 5 optimizer=optimizers.RMSprop(lr=1e-4), 6 metrics=['acc'])
1 #使用数据增强和dropout来训练我们的网络 2 #归一化处理 3 train_datagen = ImageDataGenerator( 4 rescale=1./255, 5 rotation_range=40, 6 width_shift_range=0.2, 7 height_shift_range=0.2, 8 shear_range=0.2, 9 zoom_range=0.2, 10 horizontal_flip=True,) 11 # 请注意,不应增加验证数据! 12 test_datagen = ImageDataGenerator(rescale=1./255) 13 train_generator = train_datagen.flow_from_directory( 14 train_dir, 15 #输入训练图像尺寸,所有图片的size必须是150x150 16 target_size=(150, 150), 17 batch_size=32, 18 #因为我们使用二元交叉熵损失,我们需要二元标签 19 class_mode='binary') 20 validation_generator = test_datagen.flow_from_directory( 21 validation_dir, 22 target_size=(150, 150), 23 batch_size=32, 24 class_mode='binary')
14.训练模型(100次)
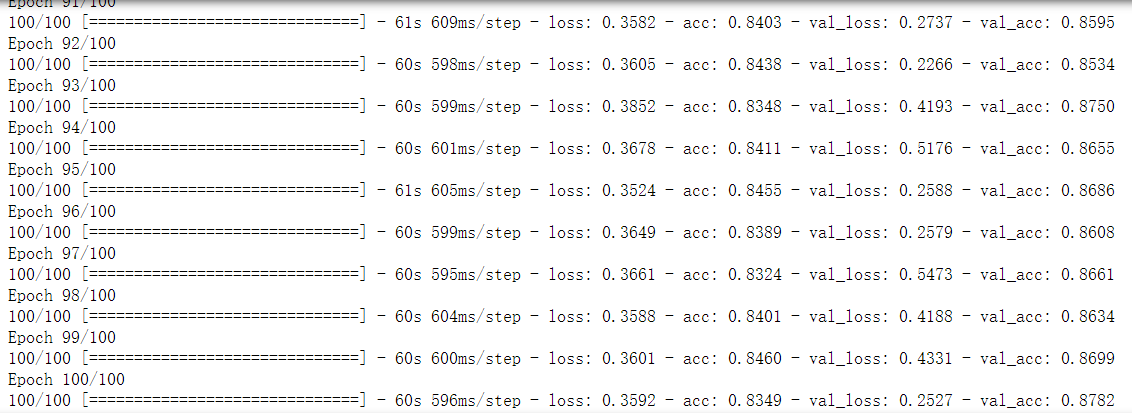
可以看出训练集精度(acc):0.8349 验证集精度(val_acc):0.8782
验证集的精度比训练集高了,说明我们成功降低的过拟合程度,数据增强成功。
1 history = model.fit_generator( 2 train_generator, 3 steps_per_epoch=100, 4 epochs=100, 5 validation_data=validation_generator, 6 validation_steps=50)
1 #将训练过程产生的数据保存为h5文件 2 model.save('smile_and_unsmile_100epoch.h5')
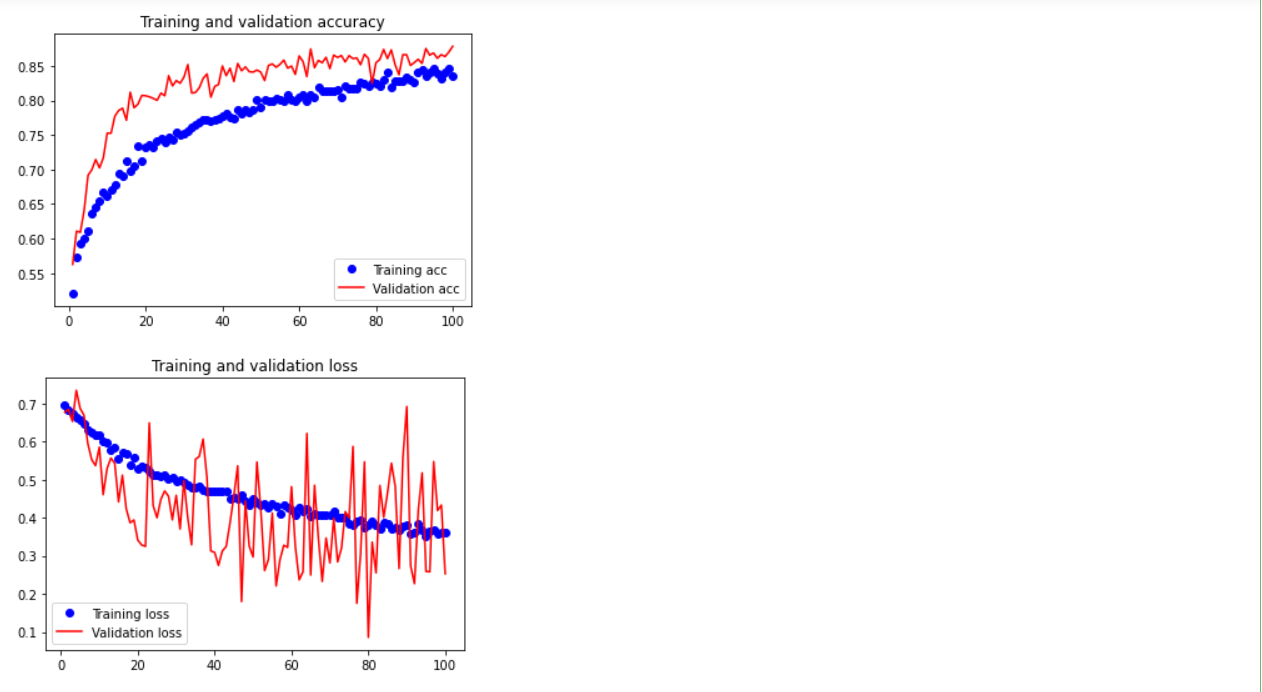
15.绘制训练过程中的损失曲线和精度曲线
1 import matplotlib.pyplot as plt 2 3 acc = history.history['acc'] 4 val_acc = history.history['val_acc'] 5 loss = history.history['loss'] 6 val_loss = history.history['val_loss'] 7 8 epochs = range(1, len(acc) + 1) 9 10 plt.plot(epochs, acc, 'bo', label='Training acc') 11 plt.plot(epochs, val_acc, 'r', label='Validation acc') 12 plt.title('Training and validation accuracy') 13 plt.legend() 14 15 plt.figure() 16 17 plt.plot(epochs, loss, 'bo', label='Training loss') 18 plt.plot(epochs, val_loss, 'r', label='Validation loss') 19 plt.title('Training and validation loss') 20 plt.legend() 21 22 plt.show()
16.使用新的训练模型再进进行识别
1 # 单张图片进行判断 是笑脸还是非笑脸 2 import cv2 3 from keras.preprocessing import image 4 from keras.models import load_model 5 import numpy as np 6 import matplotlib.pyplot as plt 7 #加载模型 8 model = load_model('smile_and_unsmile_100epoch.h5') 9 #本地图片路径 10 #img_path = ('E:\\jupyter\\识别\\data1\\test\\smile\\smile1061.jpg') 11 img_path = ('E:\\jupyter\\识别\\data1\\test\\unsmile\\unsmile717.jpg') 12 #读取图像并调整其大小为(150,150,3) 13 img = image.load_img(img_path,target_size=(150,150)) 14 # 将其转换为具有形状的Numpy数组(150、150、3) 15 img_tensor = image.img_to_array(img)/255 16 # 将其形态变为(150,150,150,3)的形状 17 img_tensor = np.expand_dims(img_tensor, axis=0) 18 #取图片信息 19 prediction =model.predict(img_tensor) 20 #输出识别率 21 print(prediction) 22 if prediction>0.5: 23 print('不笑') 24 else: 25 print('笑') 26 plt.imshow(img)#显示图片

17.多张图片进行识别判断
1 from keras.models import load_model 2 import matplotlib.pyplot as plt 3 from PIL import Image 4 from keras.preprocessing import image 5 # 设置中文 6 plt.rcParams['font.family'] = ['SimHei'] 7 # 设置子图 8 figure,ax = plt.subplots(nrows=4, ncols=4, sharex=True, sharey=True,figsize=(24,24)) 9 # 导入训练模型 10 model = load_model('smile_and_unsmile_100epoch.h5') 11 12 # 图片处理,图片的大小改为150*150 13 def convertjpg(jpgfile): 14 img=Image.open(jpgfile) 15 try: 16 new_img=img.resize((150,150),Image.BILINEAR) 17 return new_img 18 except Exception as e: 19 print(e) 20 21 # 用循环取出test中的图片进行预测 22 for i in range(1,17): # 选择要测试图片的数量 23 img = str(i)+'.jpg' 24 img_show = convertjpg(test_dir + img) 25 img_scale = image.img_to_array(img_show) # 将图片转为数组(150,150,3) 26 img_scale = img_scale.reshape(1,150,150,3) # 将形状转化为(1,150,150,3) 27 img_scale = img_scale.astype('float32')/255 # 归一化 28 29 result = model.predict(img_scale)# 预测函数 30 31 # 判断笑和不笑 32 if result>0.5: 33 title = '人物不笑' 34 label = '正确识别率为:'+str(result) 35 else: 36 title = '人物笑' 37 label = '正确识别率为:'+str(1-result) 38 39 ax = ax.flatten() # 将子图从多维变成一维 40 ax[i-1].imshow(img_show, cmap='Greys', interpolation='nearest') 41 # 子图标题 42 ax[i-1].set_title(title,fontsize=24) 43 # 子图X轴标签 44 ax[i-1].set_xlabel(label,fontsize=24) 45 # 去掉刻度 46 ax[0].set_xticks([]) 47 ax[0].set_yticks([]) 48 plt.show()


18.使用(smile_and_unsmile_100epoch.h5)卷积神经网络来进行笑脸识别
1 #使用笔记本摄像头中来进行笑脸识别判断 2 import cv2 3 from keras.preprocessing import image 4 from keras.models import load_model 5 import numpy as np 6 import dlib 7 from PIL import Image 8 model = load_model('smile_and_unsmile_100epoch.h5') 9 detector = dlib.get_frontal_face_detector() 10 video=cv2.VideoCapture(0) 11 font = cv2.FONT_HERSHEY_SIMPLEX 12 def rec(img): 13 gray=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY) 14 dets=detector(gray,1) 15 if dets is not None: 16 for face in dets: 17 left=face.left() 18 top=face.top() 19 right=face.right() 20 bottom=face.bottom() 21 cv2.rectangle(img,(left,top),(right,bottom),(0,255,0),2) 22 img1=cv2.resize(img[top:bottom,left:right],dsize=(150,150)) 23 img1=cv2.cvtColor(img1,cv2.COLOR_BGR2RGB) 24 img1 = np.array(img1)/255. 25 img_tensor = img1.reshape(-1,150,150,3) 26 prediction =model.predict(img_tensor) 27 if prediction>0.5: 28 result='unsmile' 29 else: 30 result='smile' 31 cv2.putText(img, result, (left,top), font, 2, (0, 255, 0), 2, cv2.LINE_AA) 32 cv2.imshow('Video', img) 33 while video.isOpened(): 34 res, img_rd = video.read() 35 if not res: 36 break 37 rec(img_rd) 38 #按q退出 39 if cv2.waitKey(5) & 0xFF == ord('q'): 40 break 41 video.release() 42 cv2.destroyAllWindows()
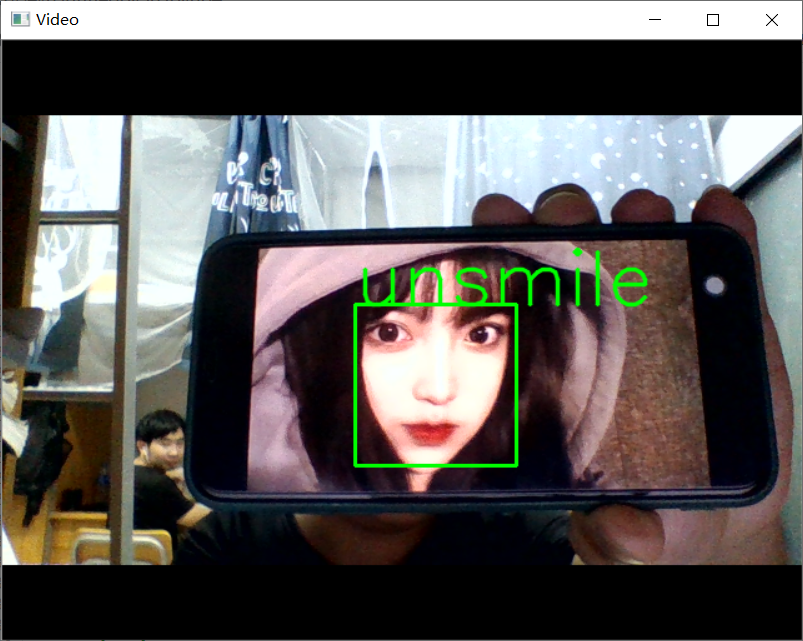
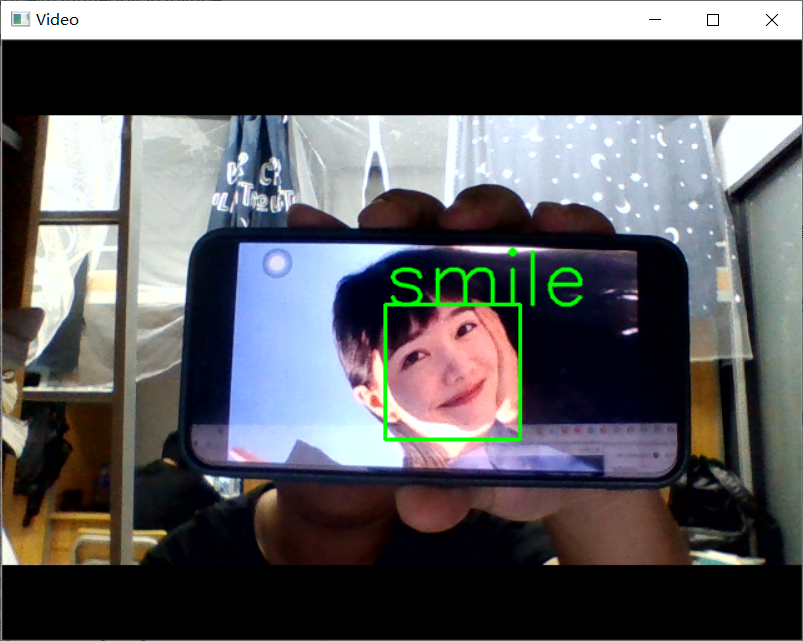
19.使用opencv自带的微笑识别
1 import cv2 2 # 人脸检测器 3 face_cascade = cv2.CascadeClassifier('D:\\Anaconda3\\Library\\etc\\lbpcascades\\lbpcascade_frontalface.xml') 4 # 检测睁开的眼睛 5 eye_cascade = cv2.CascadeClassifier('D:\\Anaconda3\\Library\\etc\\haarcascades\\haarcascade_eye.xml') 6 # 笑脸检测器 7 smile_cascade = cv2.CascadeClassifier('D:\\Anaconda3\\Library\\etc\\haarcascades\\haarcascade_smile.xml') 8 # 调用摄像头摄像头 9 cap = cv2.VideoCapture(0) 10 11 while(True): 12 # 获取摄像头拍摄到的画面 13 ret, frame = cap.read() 14 faces = face_cascade.detectMultiScale(frame, 1.3, 2) 15 img = frame 16 for (x,y,w,h) in faces: 17 # 画出人脸框,颜色自己定义,画笔宽度微 18 img = cv2.rectangle(img,(x,y),(x+w,y+h),(255,225,0),2) 19 # 框选出人脸区域,在人脸区域而不是全图中进行人眼检测,节省计算资源 20 face_area = img[y:y+h, x:x+w] 21 22 ## 人眼检测 23 # 用人眼级联分类器引擎在人脸区域进行人眼识别,返回的eyes为眼睛坐标列表 24 eyes = eye_cascade.detectMultiScale(face_area,1.3,10) 25 for (ex,ey,ew,eh) in eyes: 26 #画出人眼框,绿色,画笔宽度为1 27 cv2.rectangle(face_area,(ex,ey),(ex+ew,ey+eh),(0,255,0),1) 28 29 ## 微笑检测 30 # 用微笑级联分类器引擎在人脸区域进行人眼识别,返回的eyes为眼睛坐标列表 31 smiles = smile_cascade.detectMultiScale(face_area,scaleFactor= 1.16,minNeighbors=65,minSize=(25, 25),flags=cv2.CASCADE_SCALE_IMAGE) 32 for (ex,ey,ew,eh) in smiles: 33 #画出微笑框,(BGR色彩体系),画笔宽度为1 34 cv2.rectangle(face_area,(ex,ey),(ex+ew,ey+eh),(0,0,255),1) 35 cv2.putText(img,'Smile',(x,y-7), 3, 1.2, (222, 0, 255), 2, cv2.LINE_AA) 36 37 # 实时展示效果画面 38 cv2.imshow('frame2',img) 39 # 每5毫秒监听一次键盘动作 40 if cv2.waitKey(5) & 0xFF == ord('q'): 41 break 42 43 # 最后,关闭所有窗口 44 cap.release() 45 cv2.destroyAllWindows()
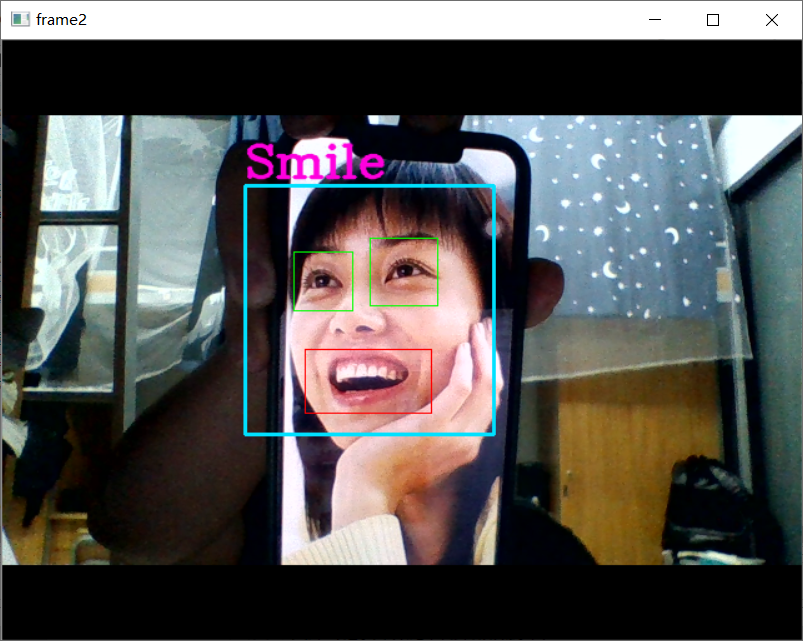
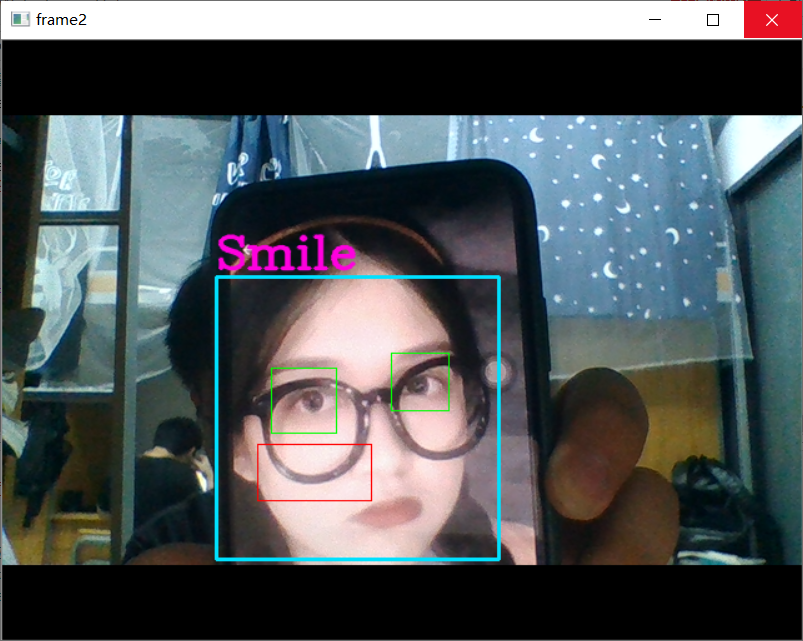
20.基于Dlib的笑脸识别 从视频中识别人脸,并实时标出面部特征点
1 import dlib # 人脸识别的库dlib 2 import numpy as np # 数据处理的库numpy 3 import cv2 # 图像处理的库OpenCv 4 5 6 class face_emotion(): 7 def __init__(self): 8 # 使用特征提取器get_frontal_face_detector 9 self.detector = dlib.get_frontal_face_detector() 10 # dlib的68点模型,使用作者训练好的特征预测器 下载地址 http://dlib.net/files/ 11 self.predictor = dlib.shape_predictor("shape_predictor_68_face_landmarks.dat") 12 13 # 建cv2摄像头对象,这里使用电脑自带摄像头,如果接了外部摄像头,则自动切换到外部摄像头 14 self.cap = cv2.VideoCapture(0) 15 # 设置视频参数,propId设置的视频参数,value设置的参数值 16 self.cap.set(3, 480) 17 # 截图screenshoot的计数器 18 self.cnt = 0 19 20 def learning_face(self): 21 22 # 眉毛直线拟合数据缓冲 23 line_brow_x = [] 24 line_brow_y = [] 25 26 # cap.isOpened() 返回true/false 检查初始化是否成功 27 while (self.cap.isOpened()): 28 29 # cap.read() 30 # 返回两个值: 31 # 一个布尔值true/false,用来判断读取视频是否成功/是否到视频末尾 32 # 图像对象,图像的三维矩阵 33 flag, im_rd = self.cap.read() 34 35 # 每帧数据延时1ms,延时为0读取的是静态帧 36 k = cv2.waitKey(1) 37 38 # 取灰度 39 img_gray = cv2.cvtColor(im_rd, cv2.COLOR_RGB2GRAY) 40 41 # 使用人脸检测器检测每一帧图像中的人脸。并返回人脸数rects 42 faces = self.detector(img_gray, 0) 43 44 # 待会要显示在屏幕上的字体 45 font = cv2.FONT_HERSHEY_SIMPLEX 46 47 # 如果检测到人脸 48 if (len(faces) != 0): 49 50 # 对每个人脸都标出68个特征点 51 for i in range(len(faces)): 52 # enumerate方法同时返回数据对象的索引和数据,k为索引,d为faces中的对象 53 for k, d in enumerate(faces): 54 # 用红色矩形框出人脸 55 cv2.rectangle(im_rd, (d.left(), d.top()), (d.right(), d.bottom()), (0, 0, 255)) 56 # 计算人脸热别框边长 57 self.face_width = d.right() - d.left() 58 59 # 使用预测器得到68点数据的坐标 60 shape = self.predictor(im_rd, d) 61 # 圆圈显示每个特征点 62 for i in range(68): 63 cv2.circle(im_rd, (shape.part(i).x, shape.part(i).y), 2, (0, 255, 0), -1, 8) 64 # cv2.putText(im_rd, str(i), (shape.part(i).x, shape.part(i).y), cv2.FONT_HERSHEY_SIMPLEX, 0.5, 65 # (255, 255, 255)) 66 67 # 分析任意n点的位置关系来作为表情识别的依据 68 mouth_width = (shape.part(54).x - shape.part(48).x) / self.face_width # 嘴巴咧开程度 69 mouth_higth = (shape.part(66).y - shape.part(62).y) / self.face_width # 嘴巴张开程度 70 # print("嘴巴宽度与识别框宽度之比:",mouth_width_arv) 71 # print("嘴巴高度与识别框高度之比:",mouth_higth_arv) 72 73 # 通过两个眉毛上的10个特征点,分析挑眉程度和皱眉程度 74 brow_sum = 0 # 高度之和 75 frown_sum = 0 # 两边眉毛距离之和 76 for j in range(17, 21): 77 brow_sum += (shape.part(j).y - d.top()) + (shape.part(j + 5).y - d.top()) 78 frown_sum += shape.part(j + 5).x - shape.part(j).x 79 line_brow_x.append(shape.part(j).x) 80 line_brow_y.append(shape.part(j).y) 81 82 # self.brow_k, self.brow_d = self.fit_slr(line_brow_x, line_brow_y) # 计算眉毛的倾斜程度 83 tempx = np.array(line_brow_x) 84 tempy = np.array(line_brow_y) 85 z1 = np.polyfit(tempx, tempy, 1) # 拟合成一次直线 86 self.brow_k = -round(z1[0], 3) # 拟合出曲线的斜率和实际眉毛的倾斜方向是相反的 87 88 brow_hight = (brow_sum / 10) / self.face_width # 眉毛高度占比 89 brow_width = (frown_sum / 5) / self.face_width # 眉毛距离占比 90 # print("眉毛高度与识别框高度之比:",round(brow_arv/self.face_width,3)) 91 # print("眉毛间距与识别框高度之比:",round(frown_arv/self.face_width,3)) 92 93 # 眼睛睁开程度 94 eye_sum = (shape.part(41).y - shape.part(37).y + shape.part(40).y - shape.part(38).y + 95 shape.part(47).y - shape.part(43).y + shape.part(46).y - shape.part(44).y) 96 eye_hight = (eye_sum / 4) / self.face_width 97 # print("眼睛睁开距离与识别框高度之比:",round(eye_open/self.face_width,3)) 98 99 # 分情况讨论 100 # 张嘴,可能是开心或者惊讶 101 if round(mouth_higth >= 0.03): 102 if eye_hight >= 0.056: 103 cv2.putText(im_rd, "amazing", (d.left(), d.bottom() + 20), cv2.FONT_HERSHEY_SIMPLEX, 104 0.8, 105 (0, 0, 255), 2, 4) 106 else: 107 cv2.putText(im_rd, "happy", (d.left(), d.bottom() + 20), cv2.FONT_HERSHEY_SIMPLEX, 0.8, 108 (0, 0, 255), 2, 4) 109 110 # 没有张嘴,可能是正常和生气 111 else: 112 if self.brow_k <= -0.3: 113 cv2.putText(im_rd, "angry", (d.left(), d.bottom() + 20), cv2.FONT_HERSHEY_SIMPLEX, 0.8, 114 (0, 0, 255), 2, 4) 115 else: 116 cv2.putText(im_rd, "nature", (d.left(), d.bottom() + 20), cv2.FONT_HERSHEY_SIMPLEX, 0.8, 117 (0, 0, 255), 2, 4) 118 119 # 标出人脸数 120 cv2.putText(im_rd, "Faces: " + str(len(faces)), (20, 50), font, 1, (0, 0, 255), 1, cv2.LINE_AA) 121 else: 122 # 没有检测到人脸 123 cv2.putText(im_rd, "No Face", (20, 50), font, 1, (0, 0, 255), 1, cv2.LINE_AA) 124 125 # 添加说明 126 im_rd = cv2.putText(im_rd, "S: screenshot", (20, 400), font, 0.8, (0, 0, 255), 1, cv2.LINE_AA) 127 im_rd = cv2.putText(im_rd, "Q: quit", (20, 450), font, 0.8, (0, 0, 255), 1, cv2.LINE_AA) 128 129 # 按下s键截图保存 130 if (k == ord('s')): 131 self.cnt += 1 132 cv2.imwrite("screenshoot" + str(self.cnt) + ".jpg", im_rd) 133 134 # 按下q键退出 135 if (k == ord('q')): 136 break 137 138 # 窗口显示 139 cv2.imshow("camera", im_rd) 140 141 # 释放摄像头 142 self.cap.release() 143 144 # 删除建立的窗口 145 cv2.destroyAllWindows() 146 147 148 if __name__ == "__main__": 149 my_face = face_emotion() 150 my_face.learning_face()
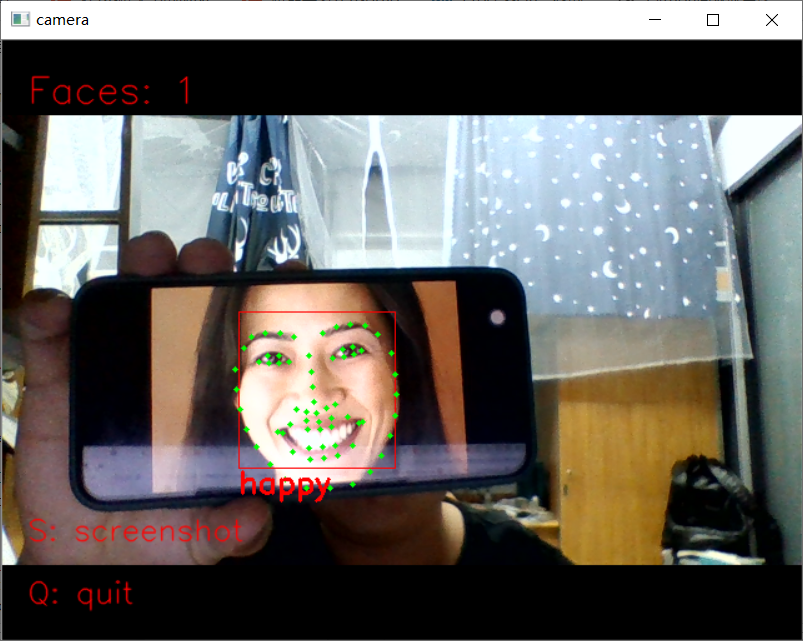
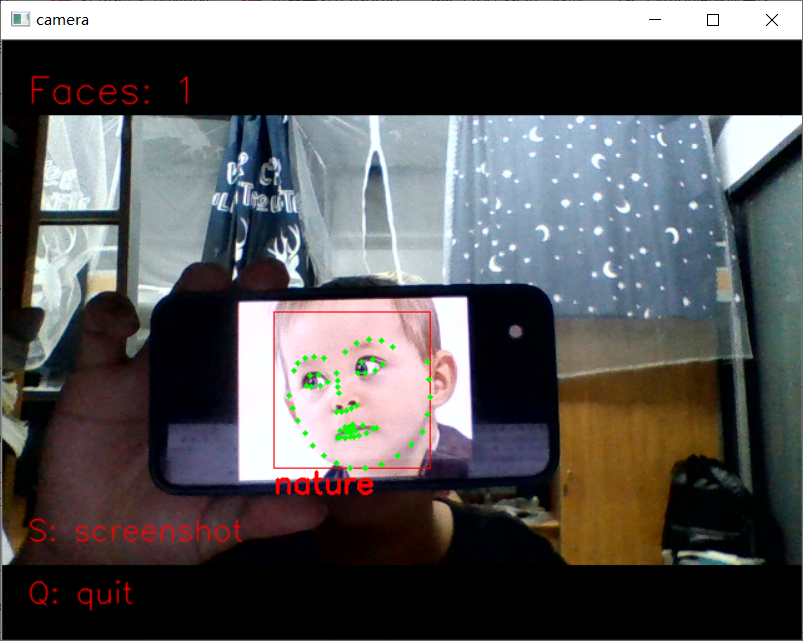
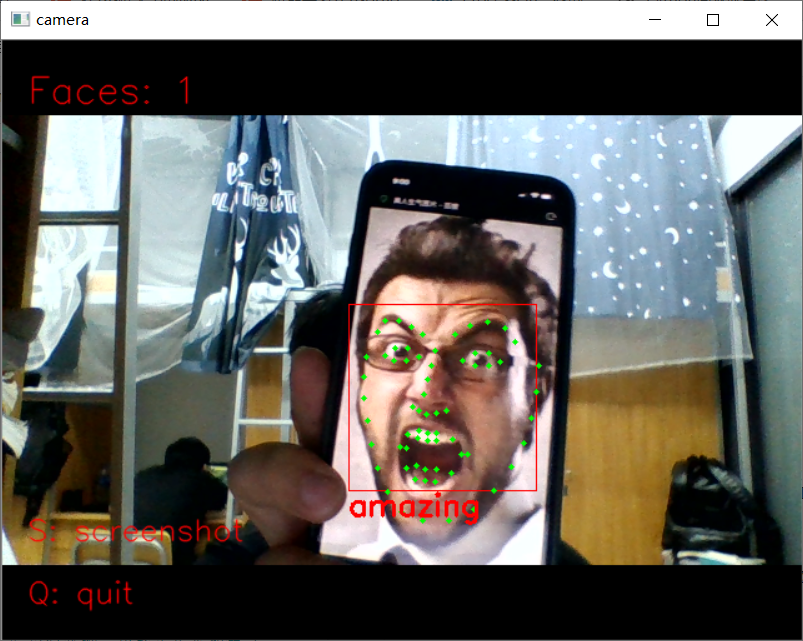
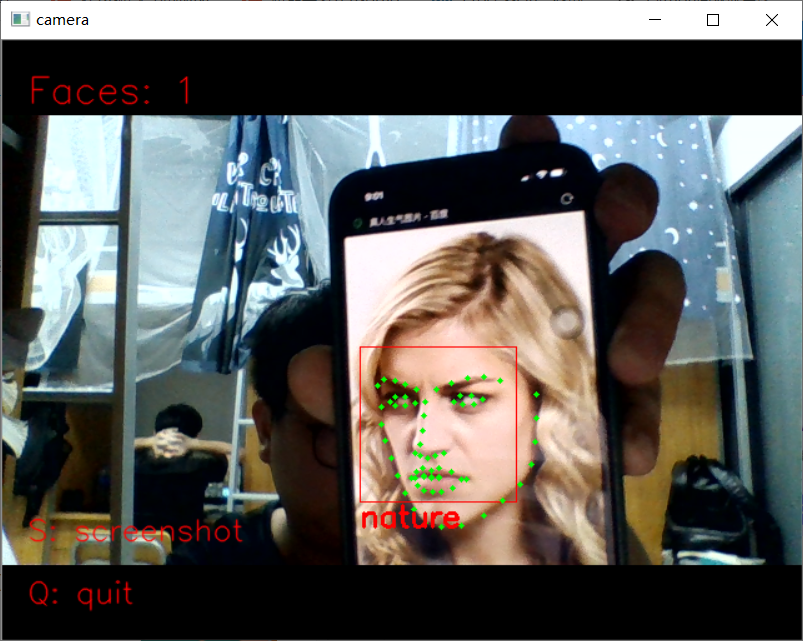
二、口罩识别
1.处理原数据集图片的名称,方便我们使用
1 #数据源集的文件夹太多,我将所有文件夹内的图片全部复制在同一个文件夹内 2 import os 3 import shutil 4 #目标文件夹 5 #determination = 'E:\\BaiduNetdiskDownload\\self-built-masked-face-recognition-dataset\\AFDB_face_dataset' 6 determination = "E:\\BaiduNetdiskDownload\\self-built-masked-face-recognition-dataset\\AFDB_masked_face_dataset" 7 if not os.path.exists(determination): 8 os.makedirs(determination) 9 10 #源文件夹路径 11 #path = 'E:\\BaiduNetdiskDownload\\self-built-masked-face-recognition-dataset\\AFDB_face_dataset' 12 path = "E:\\BaiduNetdiskDownload\\self-built-masked-face-recognition-dataset\\AFDB_masked_face_dataset" 13 folders = os.listdir(path) 14 for folder in folders: 15 dir = path + '/' + str(folder) 16 files = os.listdir(dir) 17 for file in files: 18 source = dir + '/' + str(file) 19 deter = determination + '/' + str(file) 20 shutil.copyfile(source, deter)
1 import os 2 import sys 3 def rename(): 4 path=input("请输入路径:") 5 name=input("请输入开头名:") 6 startNumber=input("请输入开始数:") 7 fileType=input("请输入后缀名:") 8 print("正在生成以"+name+startNumber+fileType+"迭代的文件名") 9 count=0 10 filelist=os.listdir(path) 11 for files in filelist: 12 Olddir=os.path.join(path,files) 13 if os.path.isdir(Olddir): 14 continue 15 Newdir=os.path.join(path,name+str(count+int(startNumber))+fileType) 16 os.rename(Olddir,Newdir) 17 count+=1 18 print("一共修改了"+str(count)+"个文件") 19 rename()


1 import os, shutil #复制文件 2 # 原始目录所在的路径 3 # 数据集未压缩 4 original_dataset_dir1 = 'E:\\BaiduNetdiskDownload\\self-built-masked-face-recognition-dataset\\AFDB_masked_face_dataset' #有口罩 5 original_dataset_dir0 = 'E:\\BaiduNetdiskDownload\\self-built-masked-face-recognition-dataset\\AFDB_face_dataset' #无口罩 6 # 模仿猫狗大战识别 建立 7 base_dir = 'E:\\jupyter\\识别\\data6' 8 os.mkdir(base_dir) 9 10 # 训练、验证、测试数据集的目录 11 train_dir = os.path.join(base_dir, 'train') 12 os.mkdir(train_dir) 13 validation_dir = os.path.join(base_dir, 'validation') 14 os.mkdir(validation_dir) 15 test_dir = os.path.join(base_dir, 'test') 16 os.mkdir(test_dir) 17 18 # 有口罩训练图片所在目录 19 train_smile_dir = os.path.join(train_dir, 'mask') 20 os.mkdir(train_smile_dir) 21 22 # 无口罩训练图片所在目录 23 train_unsmile_dir = os.path.join(train_dir, 'unmask') 24 os.mkdir(train_unsmile_dir) 25 26 # 有口罩验证图片所在目录 27 validation_smile_dir = os.path.join(validation_dir, 'mask') 28 os.mkdir(validation_smile_dir) 29 30 # 无口罩验证数据集所在目录 31 validation_unsmile_dir = os.path.join(validation_dir, 'unmask') 32 os.mkdir(validation_unsmile_dir) 33 34 # 有口罩测试数据集所在目录 35 test_smile_dir = os.path.join(test_dir, 'mask') 36 os.mkdir(test_smile_dir) 37 38 # 无口罩测试数据集所在目录 39 test_unsmile_dir = os.path.join(test_dir, 'unmask') 40 os.mkdir(test_unsmile_dir) 41 42 # 将有口罩图像复制到train_smile_dir 43 fnames = ['mask{}.jpg'.format(i) for i in range(500)] 44 for fname in fnames: 45 src = os.path.join(original_dataset_dir1, fname) 46 dst = os.path.join(train_smile_dir, fname) 47 shutil.copyfile(src, dst) 48 49 # 将有口罩图像复制到validation_smile_dir 50 fnames = ['mask{}.jpg'.format(i) for i in range(500)] 51 for fname in fnames: 52 src = os.path.join(original_dataset_dir1, fname) 53 dst = os.path.join(validation_smile_dir, fname) 54 shutil.copyfile(src, dst) 55 56 # 将有口罩图像复制到test_smile_dir 57 fnames = ['mask{}.jpg'.format(i) for i in range(500,1000)] 58 for fname in fnames: 59 src = os.path.join(original_dataset_dir1, fname) 60 dst = os.path.join(test_smile_dir, fname) 61 shutil.copyfile(src, dst) 62 63 # 将无口罩图像复制到train_unsmile_dir 64 fnames = ['unmask{}.jpg'.format(i) for i in range(1000)] 65 for fname in fnames: 66 src = os.path.join(original_dataset_dir0, fname) 67 dst = os.path.join(train_unsmile_dir, fname) 68 shutil.copyfile(src, dst) 69 70 # 将无口罩图像复制到validation_unsmile_dir 71 fnames = ['unmask{}.jpg'.format(i) for i in range(1000)] 72 for fname in fnames: 73 src = os.path.join(original_dataset_dir0, fname) 74 dst = os.path.join(validation_unsmile_dir, fname) 75 shutil.copyfile(src, dst) 76 77 # 将无口罩图像复制到test_unsmile_dir 78 fnames = ['unmask{}.jpg'.format(i) for i in range(1000, 1500)] 79 for fname in fnames: 80 src = os.path.join(original_dataset_dir0, fname) 81 dst = os.path.join(test_unsmile_dir, fname) 82 shutil.copyfile(src, dst)
2.经过处理后的数据集的目录结构

3.设置路径
1 train_mask_dir="data6/train/mask/" 2 train_unmask_dir="data6/train/unmask/" 3 test_mask_dir="data6/test/mask/" 4 test_unmask_dir="data6/test/unmask/" 5 validation_mask_dir="data6/validation/mask/" 6 validation_unmask_dir="data6/validation/unmask/" 7 train_dir="data6/train/" 8 test_dir="data6/test/" 9 validation_dir="data6/validation/"
4.检查一下每个分组(训练 / 测试 / 验证)中分别包含多少张图像
1 import os 2 3 print('有口罩数据训练图片数量:', len(os.listdir(train_mask_dir))) 4 print('无口罩数训练据图片数量:', len(os.listdir(train_unmask_dir))) 5 print('有口罩数据测试图片数量:', len(os.listdir(test_mask_dir))) 6 print('无口罩数据训练图片数量:', len(os.listdir(test_unmask_dir))) 7 print('有口罩验证图片数量:', len(os.listdir(validation_mask_dir))) 8 print('无口罩验证图片数量:', len(os.listdir(validation_unmask_dir)))

5.搭建卷积神经网络
1 from keras import layers 2 from keras import models 3 4 model = models.Sequential() 5 model.add(layers.Conv2D(32, (3, 3), activation='relu', 6 input_shape=(150, 150, 3))) 7 model.add(layers.MaxPooling2D((2, 2))) 8 model.add(layers.Conv2D(64, (3, 3), activation='relu')) 9 model.add(layers.MaxPooling2D((2, 2))) 10 model.add(layers.Conv2D(128, (3, 3), activation='relu')) 11 model.add(layers.MaxPooling2D((2, 2))) 12 model.add(layers.Conv2D(128, (3, 3), activation='relu')) 13 model.add(layers.MaxPooling2D((2, 2))) 14 model.add(layers.Flatten()) 15 model.add(layers.Dense(512, activation='relu')) 16 model.add(layers.Dense(1, activation='sigmoid'))
1 model.summary()

6.编译模型
1 from keras import optimizers 2 # 编译模型 3 # RMSprop 优化器。因为网络最后一层是单一sigmoid单元, 4 # 所以使用二元交叉熵作为损失函数 5 model.compile(loss='binary_crossentropy', 6 optimizer=optimizers.RMSprop(lr=1e-4), 7 metrics=['acc'])
1 from keras.preprocessing.image import ImageDataGenerator 2 3 # 所有图像将按1/255重新缩放 4 train_datagen = ImageDataGenerator(rescale=1./255) 5 test_datagen = ImageDataGenerator(rescale=1./255) 6 validation_datagen=ImageDataGenerator(rescale=1./255) 7 8 train_generator = train_datagen.flow_from_directory( 9 # 这是目标目录 10 train_dir, 11 # 所有图像将调整为150x150 12 target_size=(150, 150), 13 batch_size=20, 14 # 因为我们使用二元交叉熵损失,我们需要二元标签 15 class_mode='binary') 16 test_generator = test_datagen.flow_from_directory( 17 test_dir, 18 target_size=(150, 150), 19 batch_size=20, 20 class_mode='binary') 21 validation_generator = test_datagen.flow_from_directory( 22 validation_dir, 23 target_size=(150, 150), 24 batch_size=20, 25 class_mode='binary')

1 train_generator.class_indices 2 #0有口罩 1无口罩

1 for data_batch, labels_batch in train_generator: 2 print('data batch shape:', data_batch.shape) 3 print('labels batch shape:', labels_batch.shape) 4 break
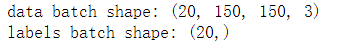
7.进行数据增强
1 datagen = ImageDataGenerator( 2 rotation_range=40, #图像随机旋转角度范围 3 width_shift_range=0.2, #图片在水平方向上平移的比例 4 height_shift_range=0.2, #图片在垂直方向上平移的比例 5 shear_range=0.2, #随机错切变换的角度 6 zoom_range=0.2, #图像随机缩放的范围 7 horizontal_flip=True, #随机将一半图像水平翻转 8 fill_mode='nearest') #填充创建像素的一种方法
1 #搭建网络 2 model = models.Sequential() 3 model.add(layers.Conv2D(32, (3, 3), activation='relu', 4 input_shape=(150, 150, 3))) 5 model.add(layers.MaxPooling2D((2, 2))) 6 model.add(layers.Conv2D(64, (3, 3), activation='relu')) 7 model.add(layers.MaxPooling2D((2, 2))) 8 model.add(layers.Conv2D(128, (3, 3), activation='relu')) 9 model.add(layers.MaxPooling2D((2, 2))) 10 model.add(layers.Conv2D(128, (3, 3), activation='relu')) 11 model.add(layers.MaxPooling2D((2, 2))) 12 model.add(layers.Flatten()) 13 model.add(layers.Dropout(0.5)) 14 model.add(layers.Dense(512, activation='relu')) 15 model.add(layers.Dense(1, activation='sigmoid')) 16 # 编译模型 17 model.compile(loss='binary_crossentropy', 18 optimizer=optimizers.RMSprop(lr=1e-4), 19 metrics=['acc'])
1 train_datagen = ImageDataGenerator( 2 rescale=1./255, 3 rotation_range=40, 4 width_shift_range=0.2, 5 height_shift_range=0.2, 6 shear_range=0.2, 7 zoom_range=0.2, 8 horizontal_flip=True,) 9 #请注意,不应增加验证数据! 10 test_datagen = ImageDataGenerator(rescale=1./255) 11 train_generator = train_datagen.flow_from_directory( 12 train_dir, 13 #输入训练图像尺寸,所有图片的size必须是150x150 14 target_size=(150, 150), 15 batch_size=32, 16 #因为我们使用二元交叉熵损失,我们需要二元标签 17 class_mode='binary') 18 validation_generator = test_datagen.flow_from_directory( 19 validation_dir, 20 target_size=(150, 150), 21 batch_size=32, 22 class_mode='binary')

8.训练模型(100次) 从输出结果看验证集精度比训练集精度高
1 history = model.fit_generator( 2 train_generator, 3 steps_per_epoch=100, 4 epochs=100, 5 validation_data=validation_generator, 6 validation_steps=50)
1 #将训练过程产生的数据保存为h5文件 2 model.save('mask_and_unmask_100epoch.h5')
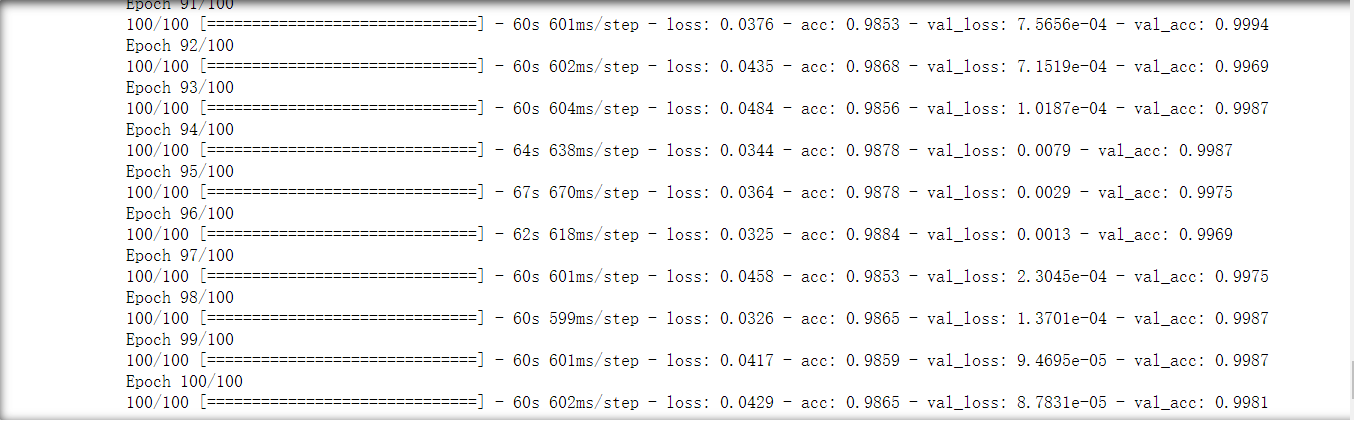
9.绘制训练(100次)过程中的损失曲线和精度曲线
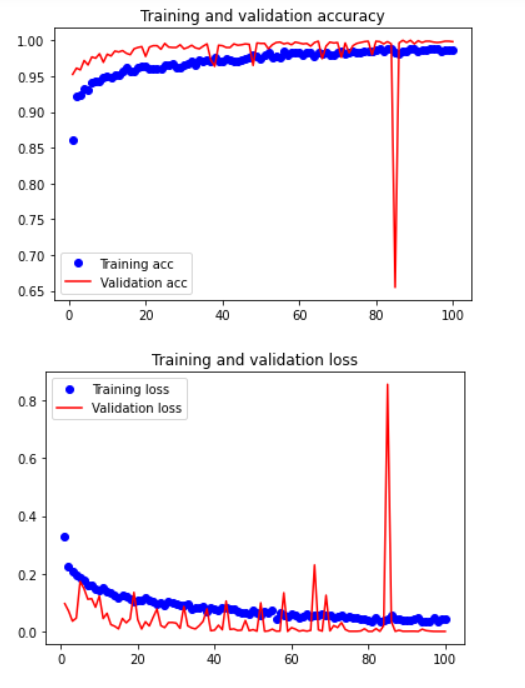
10.进行口罩识别判断
1 #进行口罩识别判断 2 from keras.models import load_model 3 import matplotlib.pyplot as plt 4 from PIL import Image 5 from keras.preprocessing import image 6 # 设置中文 7 plt.rcParams['font.family'] = ['SimHei'] 8 # 设置子图 9 figure,ax = plt.subplots(nrows=2, ncols=4, sharex=True, sharey=True,figsize=(24,14)) 10 # 导入训练模型 11 model = load_model('mask_and_unmask_100epoch.h5') 12 13 # 图片处理,图片的大小改为150*150 14 def convertjpg(jpgfile): 15 img=Image.open(jpgfile) 16 try: 17 new_img=img.resize((150,150),Image.BILINEAR) 18 return new_img 19 except Exception as e: 20 print(e) 21 22 # 用循环取出test中的图片进行预测 23 for i in range(1,9): # 选择要测试图片的数量 24 img = str(i)+'.jpg' 25 img_show = convertjpg(test_dir + img) 26 img_scale = image.img_to_array(img_show) # 将图片转为数组(150,150,3) 27 img_scale = img_scale.reshape(1,150,150,3) # 将形状转化为(1,150,150,3) 28 img_scale = img_scale.astype('float32')/255 # 归一化 29 30 result = model.predict(img_scale)# 预测函数 31 32 # 判断是猫还是狗 33 if result>0.5: 34 title = '没口罩' 35 label = '正确识别率为:'+str(result) 36 else: 37 title = '有口罩' 38 label = '正确识别率为:'+str(1-result) 39 40 ax = ax.flatten() # 将子图从多维变成一维 41 ax[i-1].imshow(img_show, cmap='Greys', interpolation='nearest') 42 # 子图标题 43 ax[i-1].set_title(title,fontsize=24) 44 # 子图X轴标签 45 ax[i-1].set_xlabel(label,fontsize=24) 46 # 去掉刻度 47 ax[0].set_xticks([]) 48 ax[0].set_yticks([]) 49 plt.show()

11.进行视频口罩识别
1 #使用笔记本自带摄像头进行口罩识别 2 import cv2 3 from keras.preprocessing import image 4 from keras.models import load_model 5 import numpy as np 6 import dlib 7 from PIL import Image 8 model = load_model('mask_and_unmask_100epoch.h5') 9 detector = dlib.get_frontal_face_detector() 10 video=cv2.VideoCapture(0) 11 font = cv2.FONT_HERSHEY_SIMPLEX 12 def rec(img): 13 gray=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY) 14 dets=detector(gray,1) 15 if dets is not None: 16 for face in dets: 17 left=face.left() 18 top=face.top() 19 right=face.right() 20 bottom=face.bottom() 21 cv2.rectangle(img,(left,top),(right,bottom),(0,255,0),2) 22 img1=cv2.resize(img[top:bottom,left:right],dsize=(150,150)) 23 img1=cv2.cvtColor(img1,cv2.COLOR_BGR2RGB) 24 img1 = np.array(img1)/255. 25 img_tensor = img1.reshape(-1,150,150,3) 26 prediction =model.predict(img_tensor) 27 if prediction>0.5: 28 result='unmask' 29 else: 30 result='mask' 31 cv2.putText(img, result, (left,top), font, 2, (0, 255, 0), 2, cv2.LINE_AA) 32 cv2.imshow('Video', img) 33 while video.isOpened(): 34 res, img_rd = video.read() 35 if not res: 36 break 37 rec(img_rd) 38 if cv2.waitKey(5) & 0xFF == ord('q'): 39 break 40 video.release() 41 cv2.destroyAllWindows()
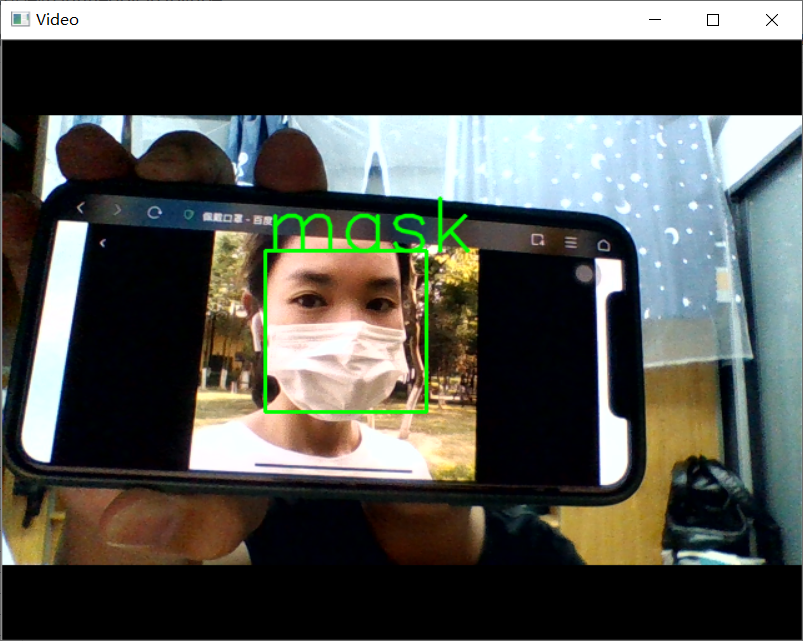
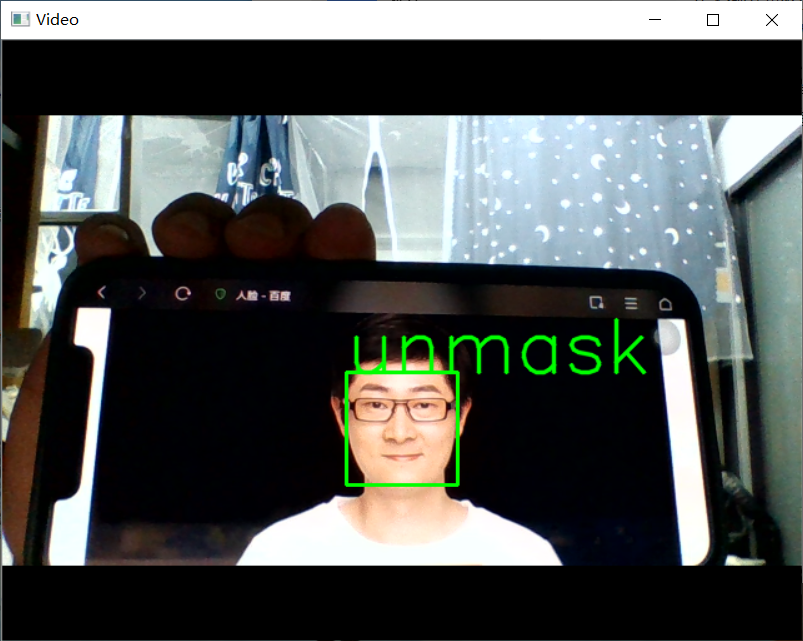
四、总结
此次机器学习过程中参考了猫狗图像识别案例,前期处理一般不会有太多问题,我在进行训练模型一直被中断训练,在网上搜索原因是:ImageDataGenerator的默认batch_size值为32。您要求每个时期执行30个步骤,这意味着每个时期执行30* 32张图像,但是我的图像太少,因此训练会崩溃。后面我增加了训练集的图片训练模型成功运行。
这次的机器学习中,模型训练基本上都达到了预期的效果,主要还是数据集样本图片不足,应当找一些比较大的数据集。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号