数据采集实践作业五
-
作业①:
-
要求:
- 熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容。
- 使用Selenium框架爬取京东商城某类商品信息及图片。
-
候选网站:http://www.jd.com/
-
关键词:学生自由选择
-
输出信息:MYSQL的输出信息如下
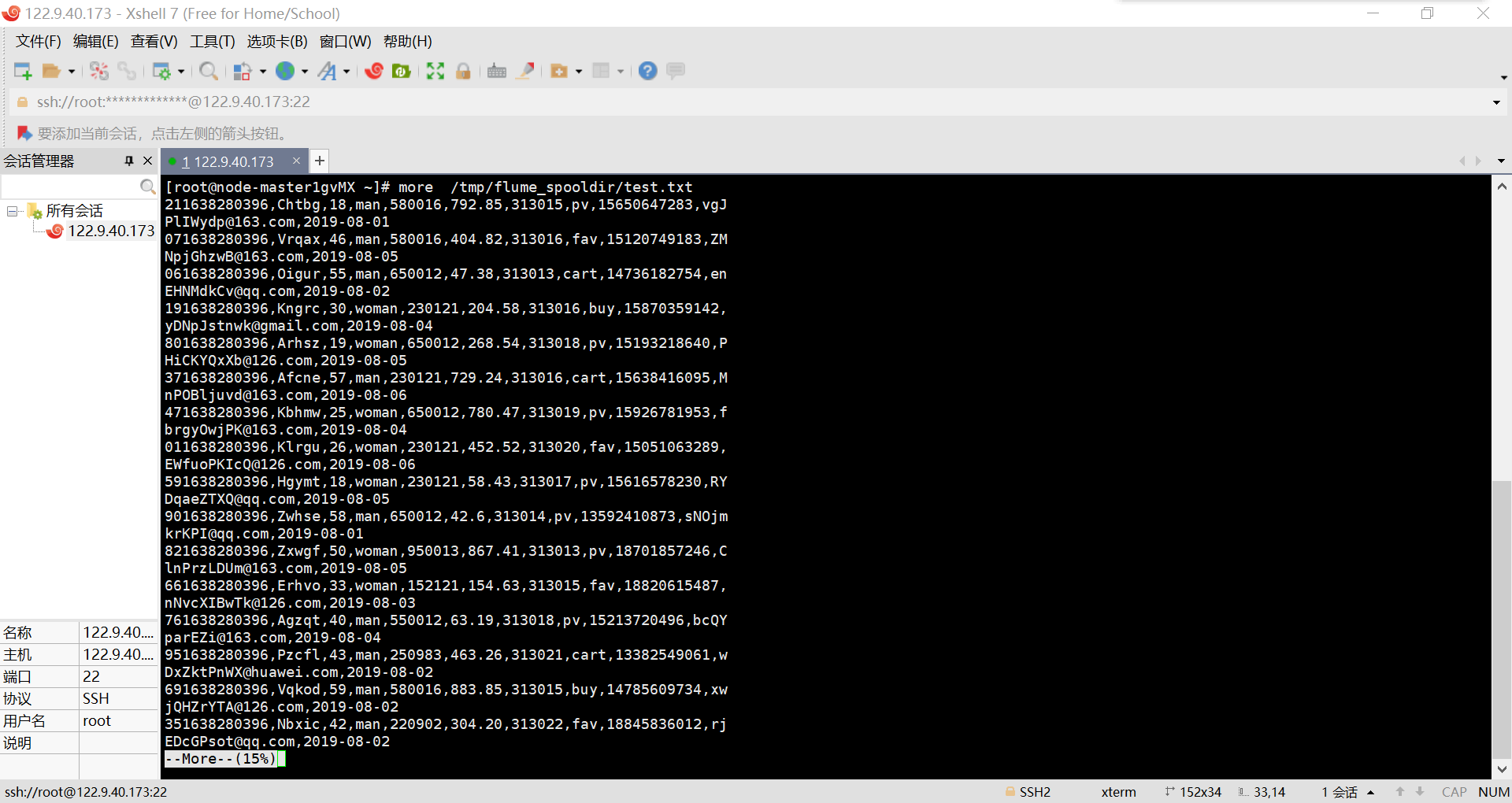
mNo mMark mPrice mNote mFile 000001 三星Galaxy 9199.00 三星Galaxy Note20 Ultra 5G... 000001.jpg 000002...... - 结果截图:
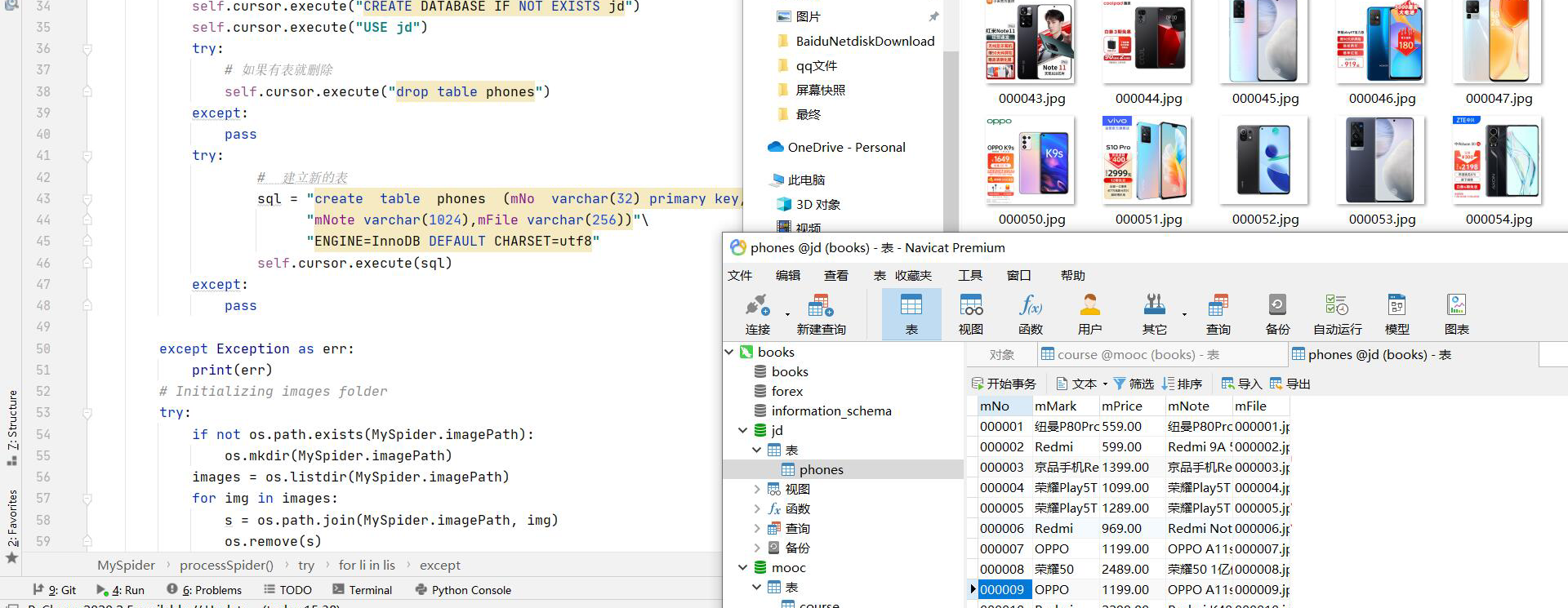
心得体会:这一题是复现,主要修改一下数据库的连接,通过这一题理解了selinum模拟键盘输入以及翻页等操作。
-
-
作业②:
-
要求:
- 熟练掌握 Selenium 查找HTML元素、实现用户模拟登录、爬取Ajax网页数据、等待HTML元素等内容。
- 使用Selenium框架+MySQL模拟登录慕课网,并获取学生自己账户中已学课程的信息保存到MySQL中(课程号、课程名称、授课单位、教学进度、课程状态,课程图片地址),同时存储图片到本地项目根目录下的imgs文件夹中,图片的名称用课程名来存储。
-
候选网站:中国mooc网:https://www.icourse163.org
-
输出信息:MYSQL数据库存储和输出格式
表头应是英文命名例如:课程号ID,课程名称:cCourse……,由同学们自行定义设计表头:
Id cCourse cCollege cSchedule cCourseStatus cImgUrl 1 Python网络爬虫与信息提取 北京理工大学 已学3/18课时 2021年5月18日已结束 http://edu-image.nosdn.127.net/C0AB6FA791150F0DFC0946B9A01C8CB2.jpg 2...... - 结果截图:


-
 View Code
View Code1 from selenium import webdriver 2 from selenium.webdriver.chrome.options import Options 3 import urllib.request 4 from selenium.webdriver.common.keys import Keys 5 import time 6 import pymysql 7 8 9 10 chrome_options = Options() 11 chrome_options.add_argument('--headless') 12 chrome_options.add_argument('--disable-gpu') 13 driver = webdriver.Chrome(options=chrome_options) 14 15 def login(): 16 driver.find_element_by_xpath('//*[@class="f-f0 navLoginBtn"]').click() 17 time.sleep(1) 18 driver.find_element_by_xpath('//*[@class="ux-login-set-scan-code_ft_back"]').click() 19 time.sleep(1) 20 driver.find_element_by_xpath('//*[@class="ux-tabs-underline_hd"]/li[2]').click() 21 time.sleep(1) 22 text = driver.find_element_by_xpath('//*[@class="ux-tabs-underline_hd"]/li[2]').text 23 print(text) 24 tel = 25 pwd = 26 time.sleep(1) 27 iframe = driver.find_element_by_xpath('/html/body/div[13]/div[2]/div/div/div/div/div/div/div/div/div[2]/div[2]/div/iframe') 28 driver.switch_to.frame(iframe) 29 time.sleep(5) 30 # WebDriverWait(driver, 200, 0.5).until(EC.presence_of_element_located(input_text)) 31 driver.find_element_by_xpath('//*[@id="phoneipt"]').send_keys(tel) 32 driver.find_element_by_xpath('//*[@autocomplete="new-password"]').send_keys(pwd) 33 driver.find_element_by_xpath('//*[@autocomplete="new-password"]').send_keys(Keys.ENTER) 34 time.sleep(5) 35 36 class courseDB: 37 def openDB(self): 38 print("opened") 39 try: 40 self.con=pymysql.connect(host="localhost", port=3306, user="root", password="123456", 41 db="mydb", charset="utf8") 42 self.cursor = self.con.cursor(pymysql.cursors.DictCursor) 43 self.cursor.execute("delete from Course") 44 self.opened = True 45 self.count = 0 46 except Exception as err: 47 print(err) 48 self.opened = False 49 50 def insert(self, courseList): 51 try: 52 self.cursor.executemany( 53 "insert into Course(cCourse,cCollege,cSchedule,cCourseStatus,cImgUrl) values (%s,%s,%s,%s,%s)", 54 courseList) 55 except Exception as err: 56 print(err) 57 58 def closeDB(self): 59 if self.opened: 60 self.con.commit() 61 self.con.close() 62 self.opened = False 63 print("closed") 64 65 class spider: 66 def getCourseData(self): 67 # self.db = courseDB() 68 # self.db.openDB() 69 print(driver.current_url) 70 test = driver.find_element_by_xpath('//*[@id="app"]/div/div/div[1]/div[3]/div[2]').text 71 print(test) 72 driver.find_element_by_xpath('/html/body/div[4]/div[3]/div[3]/button[1]').click() 73 driver.find_element_by_xpath('/html/body/div[4]/div[2]/div/div/div/div/div[3]/div[4]/div').click() 74 print(driver.current_url) 75 courses = driver.find_elements_by_xpath('//*[@id="j-coursewrap"]/div/div[1]/div') 76 courseInfo = [] 77 count = 0 78 for course in courses: 79 cCourse = course.find_element_by_xpath('./div/a/div[2]/div[1]/div[1]/div/span[2]').text 80 cCollege = course.find_element_by_xpath('./div/a/div[2]/div[1]/div[2]/a').text 81 cSchedule = course.find_element_by_xpath('./div/a/div[2]/div[2]/div[1]/div[1]/div[1]/a/span').text 82 cCourseStatus = course.find_element_by_xpath('./div/a/div[2]/div[2]/div[2]').text 83 cImgUrl = course.find_element_by_xpath('./div/a/div[1]/img').get_attribute('src') 84 # print(cCourse) 85 # print(cCollege) 86 # print(cSchedule) 87 # print(cCourseStatus) 88 # print(cImgUrl) 89 path = './Img/' + str(cCourse) + '.jpg' 90 urllib.request.urlretrieve(cImgUrl, path) 91 time.sleep(0.05) 92 courseInfo.append((cCourse,cCollege,cSchedule,cCourseStatus,cImgUrl)) 93 print(courseInfo) 94 # self.db.closeDB() 95 return courseInfo 96 def process(self): 97 self.db = courseDB() 98 self.db.openDB() 99 courseInfo = self.getCourseData() 100 self.db.insert(courseInfo) 101 self.db.closeDB() 102 103 104 try: 105 driver.get("https://www.icourse163.org/") 106 login() 107 s = spider() 108 s.process() 109 except Exception as err: 110 print(err) 111 driver.close()
-
心得体会:实验二主要是模拟登录及点击操作,困难的地方在于登录后点击我的课程时,会被一个窗口覆盖,由于我的chrome没有显示这个窗口,在这卡半天,在参考学习其他同学的博客后才发现这个问题,爬取数据存入数据库就比较常规操作,嗯,就这样。
-
-
作业③:Flume日志采集实验
-
- 要求:掌握大数据相关服务,熟悉Xshell的使用
-
- 完成文档 华为云_大数据实时分析处理实验手册-Flume日志采集实验(部分)v2.docx 中的任务,即为下面5个任务,具体操作见文档。
- 环境搭建
- 任务一:开通MapReduce服务
- 实时分析开发实战:
- 任务一:Python脚本生成测试数据
- 任务二:配置Kafka
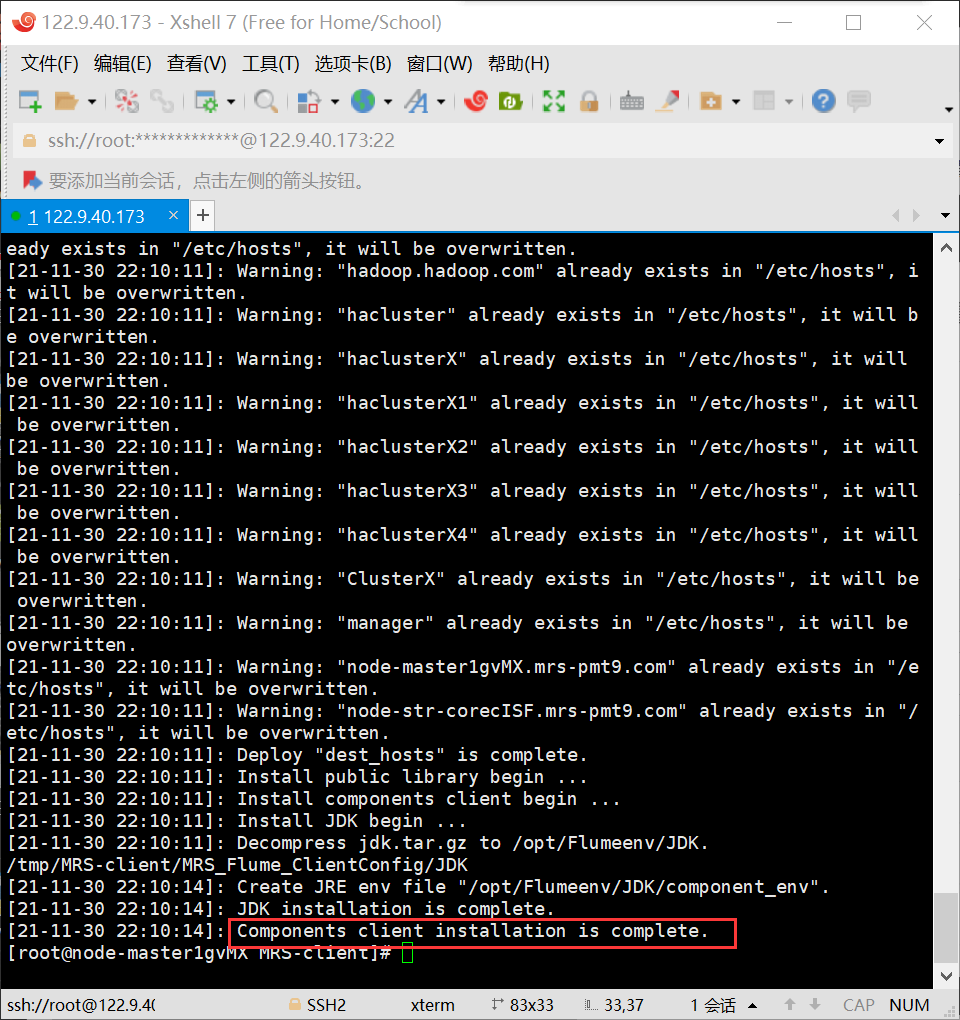
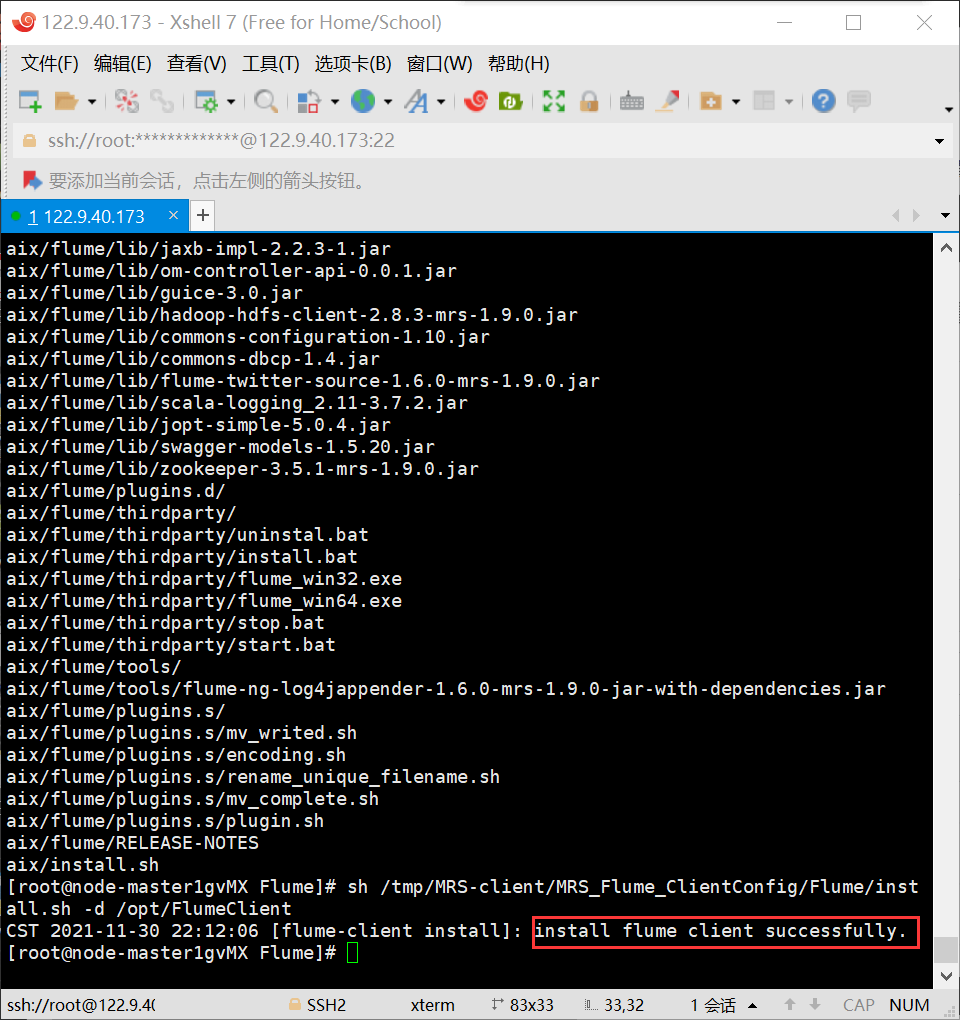
- 任务三:安装Flume客户端
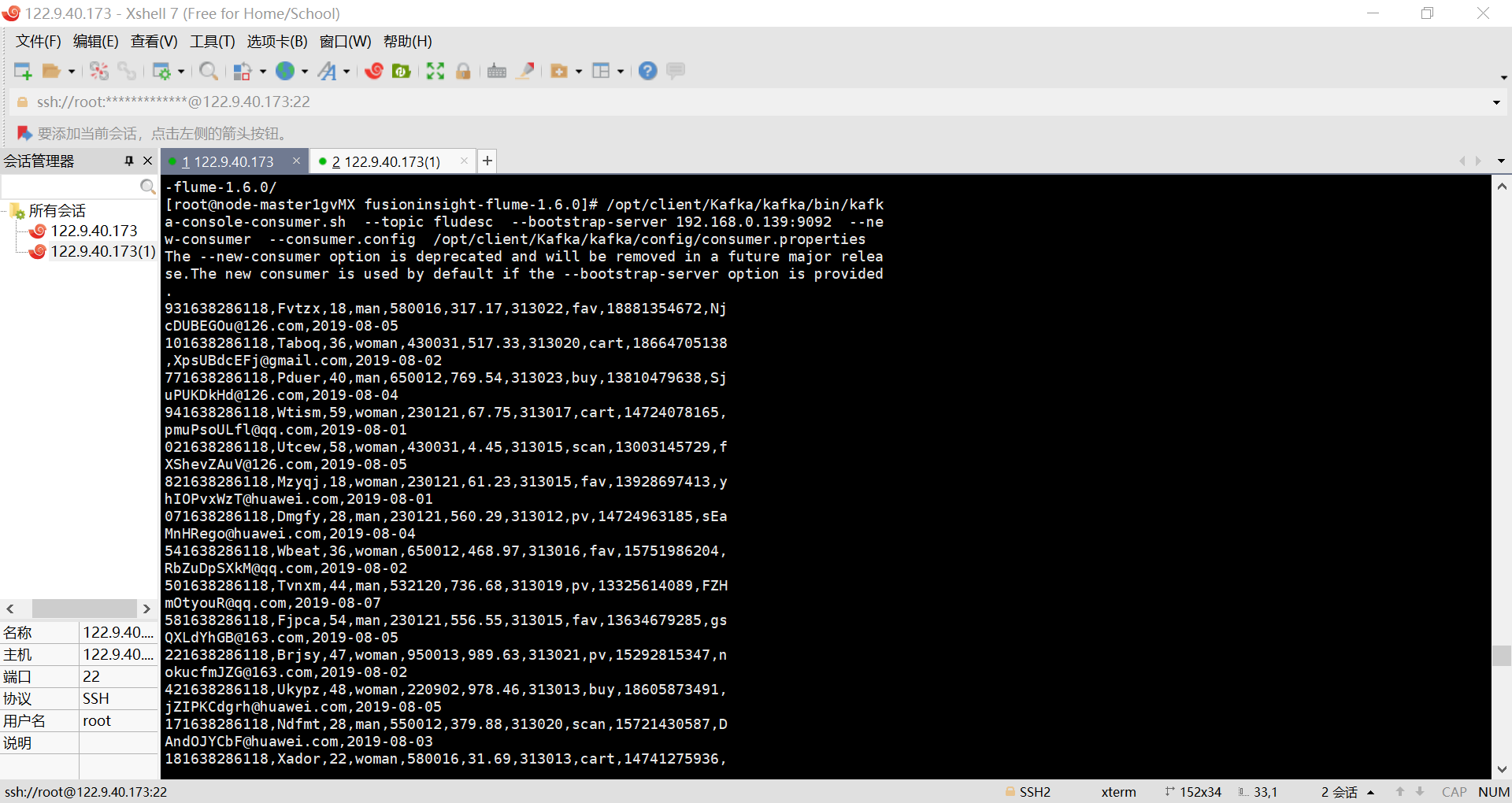
- 任务四:配置Flume采集数据
-

实验截图: