启动集群
先在几台虚拟机输入cd /opt/module/hadoop-3.1.3/
(1)如果集群是第一次启动,需要在 hadoop102 节点格式化 NameNode(注意:格式 化 NameNode,会产生新的集群 id,导致 NameNode 和 DataNode 的集群 id 不一致,集群找 不到已往数据。如果集群在运行过程中报错,需要重新格式化 NameNode 的话,一定要先停 止 namenode 和 datanode 进程,并且要删除所有机器的 data 和 logs 目录,然后再进行格式 化。)
[atguigu@hadoop102 hadoop-3.1.3]$ hdfs namenode -format
(2)启动 HDFS
[atguigu@hadoop102 hadoop-3.1.3]$ sbin/start-dfs.sh
在102上 jps
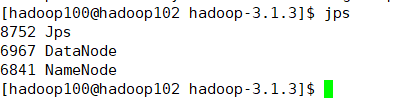
(3)在配置了 ResourceManager 的节点(hadoop103)启动 YARN
先su一下,
[atguigu@hadoop103 hadoop-3.1.3]$ sbin/start-yarn.sh
在102,103,104上jps

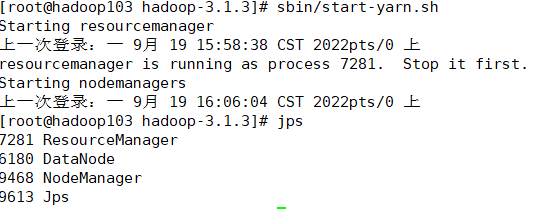
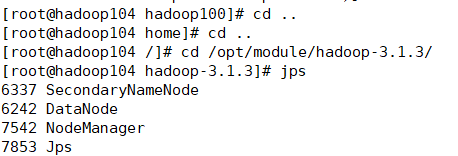
(4)Web 端查看 HDFS 的 NameNode
(a)浏览器中输入:http://hadoop102:9870
(b)查看 HDFS 上存储的数据信息
(5)Web 端查看 YARN 的 ResourceManager
(a)浏览器中输入:http://hadoop103:8088
(b)查看 YARN 上运行的 Job 信息

 浙公网安备 33010602011771号
浙公网安备 33010602011771号