常见损失函数用法及其比较
1. 损失函数
损失函数(loss function)或代价函数(cost function)是将随机事件或其有关随机变量的取值映射为非负实数以表示该随机事件的“风险”或“损失”的函数。在应用中,损失函数通常作为学习准则与优化问题相联系,即通过最小化损失函数求解和评估模型。例如在统计学和机器学习中被用于模型的参数估计。
机器学习中,给定独立同分布的学习样本(X,y)和模型f,损失函数是模型输出和观测结果间概率分布差异的量化。
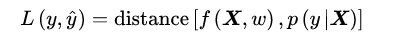
式中W表示模型参数,上式右侧具体的量化方法视问题和模型而定,但要求满足损失函数的一般定义,即样本空间的非负可测函数。
更通俗的说,损失函数是用来描述模型的预测值与数据真实值的吻合程度。有时候把单个样本的预测与实际值的误差称为损失函数,对所有样本平均损失称为代价函数。除了以上,还有目标函数,我们通常说的目标函数是代价函数+正则化项。有时候并不严格区分损失函数、代价函数、目标函数。
2. 常见的损失函数
均方误差(MSE)
均方误差是指所有样本预测值与真实值的平方差的平均值。常用于回归问题。当模型为线性时,基于均方误差最小化来进行模型求解的方法称为“最小二乘法”。可以得到模型在样本数据上的预测与真实值的最小误差所对应的参数(关于最小二乘法公式本文没有给出,可以自己查阅)。以下为均方误差(MSE)公式,n为样本数量,括号内为真实值与预测值之差。

平均绝对误差(MAE)
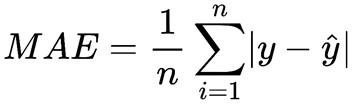
平均绝对误差的值越小,说明模型能有更好的精确度。通过MAE,可以了解预测的错误程度。使用MAE能较均方误差更好地发现异常值。
Hinge损失函数
之前的用于二分类的SVM中就是使用的Hinge损失函数,其具有凸函数且连续可导的性质。式子如下:f(x)为预测值(范围为|f(x)|大于等于1),y为实际值(取值-1或1,代表两类)。很显然,当预测正确时,损失值为0。例如:y=-1,预测f(x)=-1.2表明该样本为-1所属的类.此时L=max(0,-0.2)=0。Hinge损失函数健壮性相对较高,对异常点、噪声不敏感。
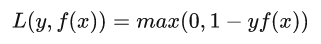
对数似然损失函数
在前面逻辑回归中对似然函数,对数似然函数,对数似然损失函数进行了说明。对于0,1二分类而言,对数似然损失函数的公式简化为:
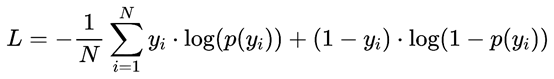
对于上式,可能每个人的写法不同,重要的是理解,yi为标签的实际值0或者1,而P(yi)表示模型预测样本第i个样本为yi的概率(范围为0到1)。举个例子:
如yi=1时,预测概率接近或等于1,此时通过上式计算得到损失L越接近0或等于0。yi=0,预测概率接近或等于1时,损失L也接近或等于0.当yi=1,预测概率为0或接近0时,上式中的L会很大;yi=0的情况也一样。预测越正确损失值越小,预测越不准确,损失值越大。
交叉熵与二元交叉熵损失函数
交叉熵是信息论中的概念,这里不过多讲解。以下为交叉熵,p为真实分布,q为非真实分布,若p=q,则式子变成了信息熵,可以理解为对X中的样本进行编码所需要的编码长度的期望值。以下为交叉熵计算公式,若为二分类,则二元交叉熵损失函数和对数似然损失函数一致。
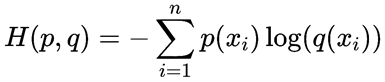
指数损失函数
AdaBoost迭代算法使用的是指数损失函数,目前还没学Adaboost,这里先给出标准公式:
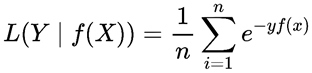
其他损失函数
除了上面介绍的损失函数外,还包括0-1 损失,对数损失、Huber、Focal等。
若存在不足之处,欢迎指正与评论!
参考资料:
https://baike.baidu.com/item/%E6%8D%9F%E5%A4%B1%E5%87%BD%E6%95%B0/1783236?fr=aladdin
https://zhuanlan.zhihu.com/p/182983435

 浙公网安备 33010602011771号
浙公网安备 33010602011771号