MAN: Moment Alignment Network for Natural Language Moment Retrieval via Iterative Graph Adjustment
Paper Reading @ 22/50
-- original : https://arxiv.org/abs/1812.00087
Two crucial challenge:
- semantic misalignment: a video contains multiple moments of interests
- structural misalignment: language query usually describes complex temporal dependencies.
MAN: unifies the candidate moment encoding and temporal structural reasoning in a single-shot feed-forward network where language description is naturally integrated as a dynamic filters
The first to exploit graph-structured moment relations for temporal reasoning in videos
Related Work
- Temporal Activity Detection: mainly used temporal sliding window as candidates and most have focused on detecting a fixed set of activity classes without language queries,
- Natural Language Moment Retrieval
- Visual Relations and Graph Network
Model
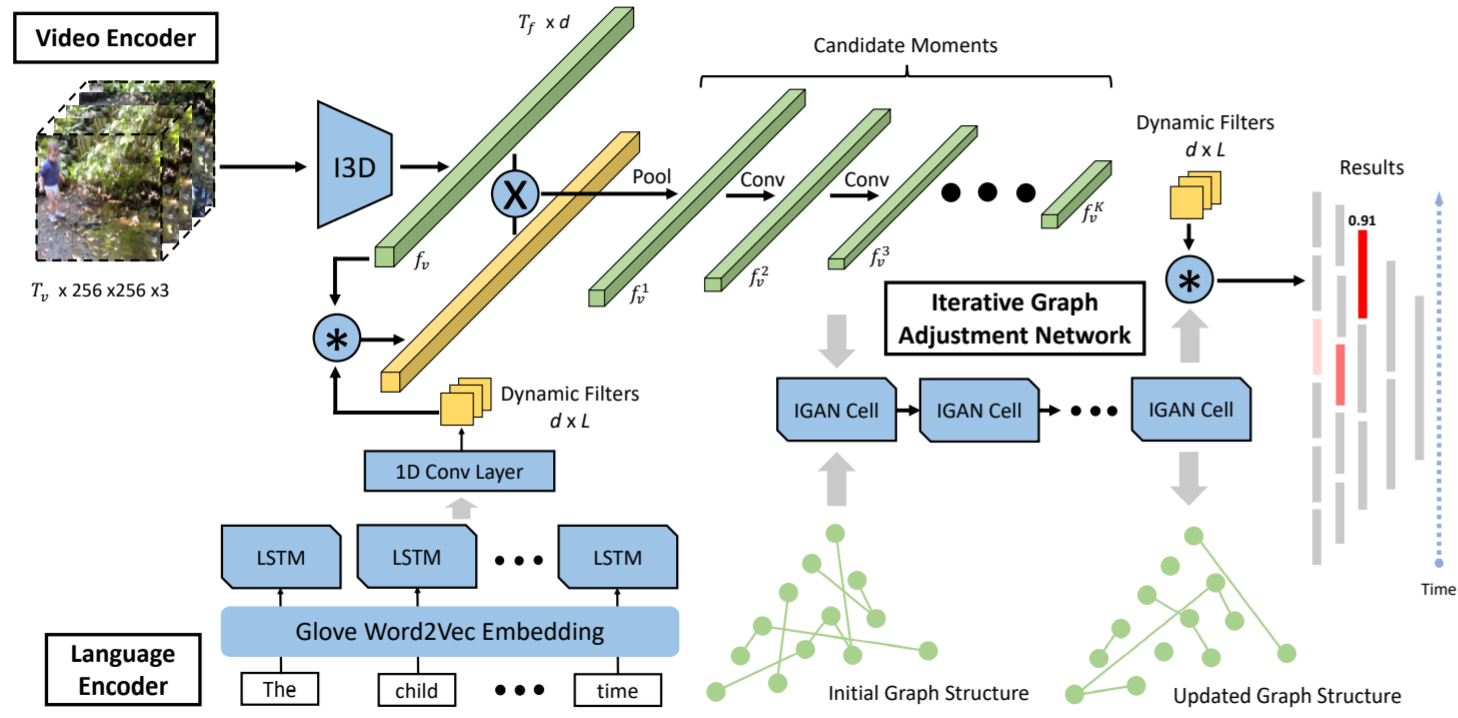
Three main components: a language encoder, a video encoder and an iterative graph adjustment network.
Language Encoding as Dynamic Filters
Learn word embedding from a large collection of text documents. Specifically, use the Glove word2vec model pre-trained on Wikipedia.
Use a single-layer LSTM network to encode input sentence.
Rely on dynamic convolution filters to transfer textual information to the visual domain.
- Dynamic convolution filters rely generated depending on the input.
- where \(f^i_l \in R^d\) is the word-level representation at index, \(\Gamma_i\) is dynamic filter which has the same number of input channels as \(f^i_l\).
Convolve the dynamic filters with the input video features to produce a semantically aligned visual representation, and also with the final moment-level features to compute the matching scores.
Single-Shot Video Encoder
A hierarchical convolution network is used to directly produce multi-scale candidate moments from the input video stream.
-
Adopt the TAN model to obtain a visual representation \(f_v \in R^{T_f \times d}\) from video \(V = \{v_t\}_{t=1}^{T_v}\). \(T_f\) is the total number of clips and d is the feature dimension which is the same as language feature
-
A novel feature alignment module that is convolutional dynamic filters mentioned above is devised to filter out unrelated visual features at early stage
\[M = \Gamma * f_v \in R^{T_v \times L}\\ M_{norm} = softmax(sum(M)) \in R^{T_v}\\ f'_v = M_{norm} \odot f_v \in R^{T_v \times d} \] -
To generate variable-length candidate moments, a temporal pooling layer is firstly devised on top of \(f'_v\) to reduce the temporal dimension of feature map and increase temporal receptive field, and the size of ouput feature map is \(T_v /p \times d\). Then stack K more
1Dconvolutional layers with appropriate pooling to generate a sequence of feature maps that progressively decrease in temporal dimension, denoted as \(\{f^k_v\}^K_{k=1}, f^k_v \in R^{T_k \times d}\). \(T_k\) is the temporal dimension of each layer.
Iterative Graph Adjustment Network
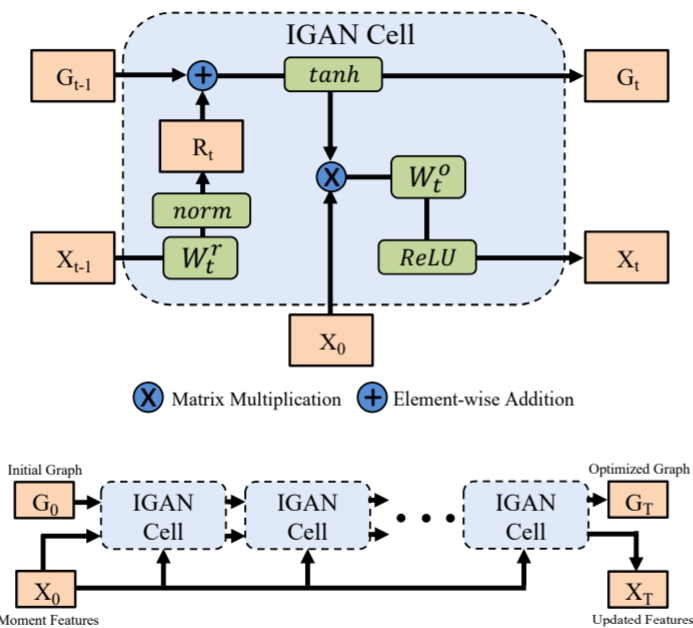
Model moment-wise temporal relations in a graph to explicitly utilize the rich relational information among moments. Specifically, candidate moments are represented by nodes and their relations are defined as edges.
One layer of traditional graph convolution is defined as:
\(G \in R^{N \times N}\) is the adjacency matrix, \(X \in R^{N \times d}\) is the input feature of all nodes, \(W \in R^{d \times d}\) is the weight matrix and \(H \in R^{N \times d}\) is the updated node representation.
Introduce the Iterative Graph Adjustment Network (IGAN) based on GCN but with a learn-able adjacency matrix. The certain major modifications to the original GCN block:
- decompose the adjacency matrix into a preserving component and a residual component.
- residual component is produced from the node representation
- iteratively accumulate residual signals to update the adjacency matrix
\(X_0 = f_m\) is the input candidate moment features, \(R_t\) is the residual component, the initial adjacency matrix \(G_0\) is set as a diagonal matrix to emphasize self-relations.
Stack multiple IGAN cells to update the candidate moment representations as well as the moment-wise graph structure.
Convolve the dynamic filter \(\Gamma\) with the final output \(X_T\) to compute the matching score.

Loss
For each candidate moment, the temporal IoU between candidate moment and ground truth moment is higher than 0.5, the candidate will be regraded as positive, otherwise negative.
\(N_b\) is the total training candidate moments in a batch, \(s_i\) is the temporal IoU, \(a_i\) is the predicted score.
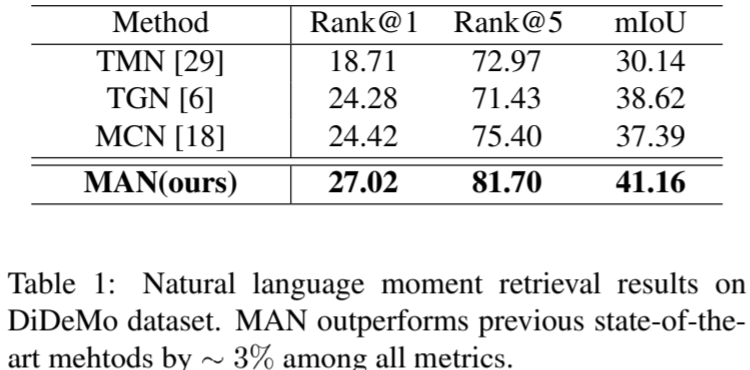
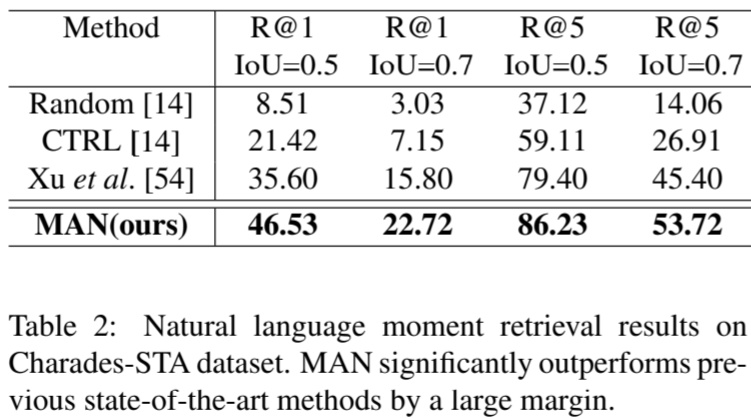
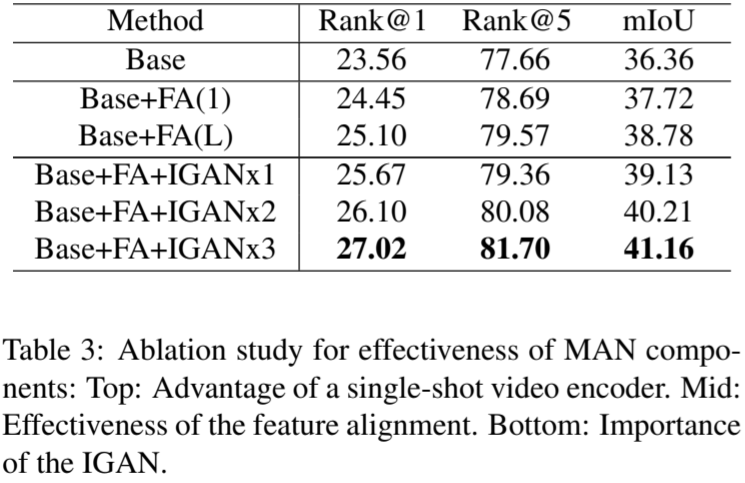
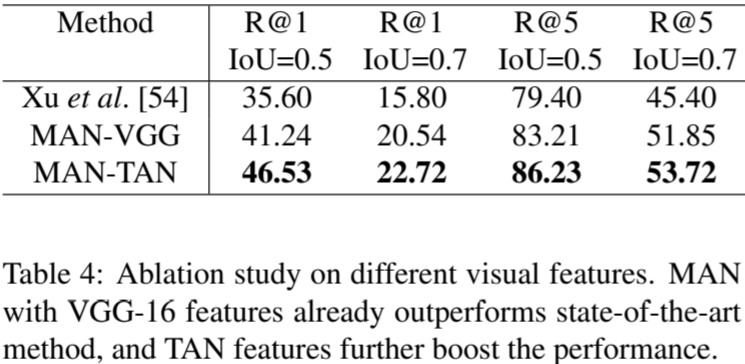
Experiment

 浙公网安备 33010602011771号
浙公网安备 33010602011771号