程序的表示(一)
程序的表示(一)
本次我们使用x86-64指令集架构(ISA)来对程序的机器级表示做描述,ISA定义了指令的格式,处理器的状态,以及指令对处理器的影响。与机器代码相比,ISA具有更好的可读性。
查看机器代码
查看机器代码的方式有许多中,以代码文件swap.c为例
void swap(int *a, int *b) {
int tmp = *a;
*a = *b;
*b = tmp;
}
编译时查看
gcc -Og -S swap.c
其中-O选项表示要选择的优化级别,-Og会告诉编译器不做优化,-S表示生成汇编代码,由此得到的汇编代码如下所示:
.file "hello.c"
.text
.globl _swap
.def _swap; .scl 2; .type 32; .endef
_swap:
LFB0:
.cfi_startproc
pushl %ebx
.cfi_def_cfa_offset 8
.cfi_offset 3, -8
movl 8(%esp), %edx
movl 12(%esp), %eax
movl (%edx), %ecx
movl (%eax), %ebx
movl %ebx, (%edx)
movl %ecx, (%eax)
popl %ebx
.cfi_restore 3
.cfi_def_cfa_offset 4
ret
.cfi_endproc
LFE0:
.ident "GCC: (MinGW.org GCC-6.3.0-1) 6.3.0"
所有以 . 开头的行都是指导汇编器和链接器工作的伪指令,我们可以忽略,由此得到核心汇编代码为:
_swap:
LFB0:
pushl %ebx
movl 8(%esp), %edx
movl 12(%esp), %eax
movl (%edx), %ecx
movl (%eax), %ebx
movl %ebx, (%edx)
movl %ecx, (%eax)
popl %ebx
ret
gdb查看字节表示
(gdb) x/20xb swap
0x0 <swap>: 0x53 0x8b 0x54 0x24 0x08 0x8b 0x44 0x24
0x8 <swap+8>: 0x0c 0x8b 0x0a 0x8b 0x18 0x89 0x1a 0x89
0x10 <swap+16>: 0x08 0x5b 0xc3 0x90
这条命令告诉gdb显示(x)从swap开始的20个十六进制(x)的字节(b)
编译后反汇编器查看汇编代码
命令如下:
objdump -d swap.o
生成的结果如下:
00000000 <_swap>:
0: 53 push %ebx
1: 8b 54 24 08 mov 0x8(%esp),%edx
5: 8b 44 24 0c mov 0xc(%esp),%eax
9: 8b 0a mov (%edx),%ecx
b: 8b 18 mov (%eax),%ebx
d: 89 1a mov %ebx,(%edx)
f: 89 08 mov %ecx,(%eax)
11: 5b pop %ebx
12: c3 ret
13: 90 nop
很容易发现gdb查看到的字节表示也就正对应反汇编器左边的字节表示,右边是相应的汇编代码。
其中有许多的特性值得说明:
- x86-64的指令长度在1-15字节不等,越常用的指令越短
- 反汇编器得到的汇编代码与编译时看到的汇编代码不同,反编译后省略了大小后缀
数据格式
x86指令集最初为16位,之后扩张成32位,再到后来的64位。历史原因,称16位数为“字”,32位数为“双字”,64位数为“四字”。下面是C语言各种数据类型在x86-64ISA中的大小,很容易理解在64位机上指针的大小为8字节。对于浮点数使用的是不同组的寄存器和指令,故汇编代码会有所差别。
| C声明 | Intel数据类型 | 汇编代码后缀 | 大小(字节) |
|---|---|---|---|
| char | 字节 | b | 1 |
| short | 字 | w | 2 |
| int | 双字 | l | 4 |
| long | 四字 | q | 8 |
| char* | 四字 | q | 8 |
| float | 单精度 | s | 4 |
| double | 双精度 | l | 8 |
寄存器
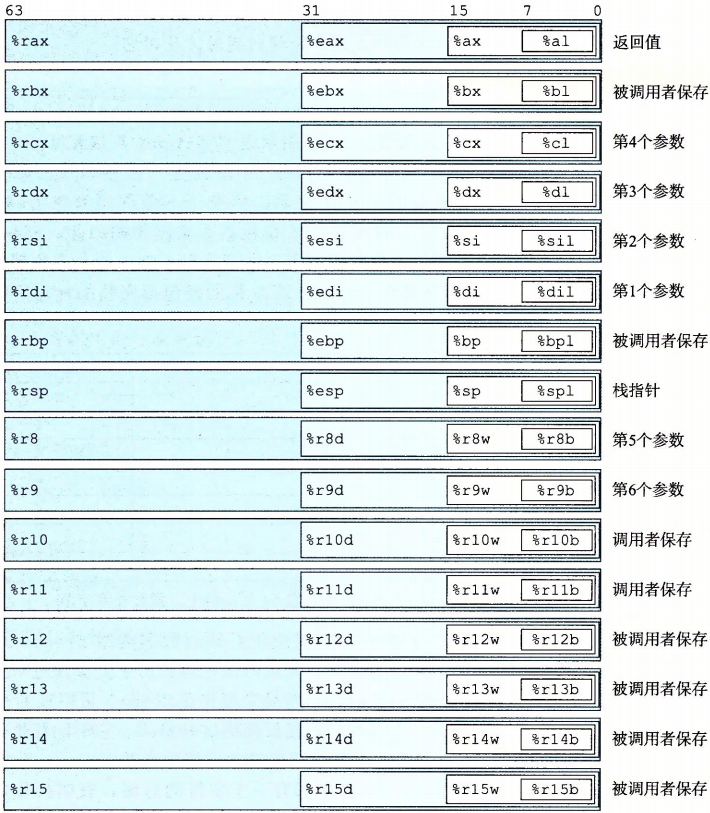
一个单核cpu中包含16个存储64位值的整数寄存器,用来存储整数数据和指针。所有的16个寄存器的低位部分都可以作为字节、字、双字、四字数字来访问。由于最初的intel机8086中有8个16位寄存器,即%ax到%sp。历史原因每个名字有不同的用途,到后来扩展到IA32架构时,这些寄存器也就扩展成了32位,一直到现在扩展成了64位。而且在后来还添加了8个64位寄存器,标号是按照新的命名方式制定的,也就是%r8到%r15。总体表示如下
操作数指示符
一条指令可以有一个或者多个操作数。操作数用于指示出一个指令操作的源数据以及存放结果的位置。操作数有以下三种:
-
立即数
用来表示常数,格式是\$后面加上C语言表示法的整数,例如\$0xFF。在不同的指令中允许的立即数范围不同,这与我们上面提到的数据格式有关。
-
寄存器
即表示寄存器中的内容,16个寄存器中的低1字节、2字节、4字节、8字节中的一个均可作为操作数。例如使用 \(r_a\) 来表示一个寄存器,则\(R[r_a]\)就表示寄存器中保存的值。
-
内存引用
内存引用会根据内存地址在内存中取出来值。用\(M[address]\)表示从地址address开始的值,至于取多少字节与指令有关。
操作数的所有格式如下所示:
| 类型 | 格式 | 操作数值 | 名称 |
|---|---|---|---|
| 立即数 | \(Imm\) | \(Imm\) | 立即数寻址 |
| 寄存器 | \(r_a\) | \(R[r_a]\) | 寄存器寻址 |
| 存储器 | \(Imm\) | \(M[Imm]\) | 绝对寻址 |
| 存储器 | \((r_a)\) | \(M[R[r_a]]\) | 间接寻址 |
| 存储器 | \(Imm(r_a)\) | \(M[R[r_a]+Imm]\) | (基址+偏移量)寻址 |
| 存储器 | \((r_a, r_b)\) | \(M[R[r_a] + R[r_b]]\) | 变址寻址 |
| 存储器 | \(Imm(r_a, r_b)\) | \(M[R[r_a] + R[r_b] + Imm]\) | 变址寻址 |
| 存储器 | \((, r_a, s)\) | \(M[R[r_a]*s]\) | 比例变址寻址 |
| 存储器 | \(Imm(, r_a, s)\) | \(M[R[r_a]*s + Imm]\) | 比例变址寻址 |
| 存储器 | \((r_a, r_b, s)\) | \(M[R[r_a] + R[r_b]*s]\) | 比例变址寻址 |
| 存储器 | \(Imm(r_a, r_b, s)\) | \(M[R[r_a] + R[r_b]*s] + Imm\) | 比例变址寻址 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号