
支持向量机(下)
回顾上节主要引出了最优间隔分类器的模型,并简述了支持向量的含义,接下来这节将围绕支持向量机模型及其优化方法SMO来展开。
最优间隔分类器模型的原始最优问题:

为了求解模型,得到它的对偶最优问题:
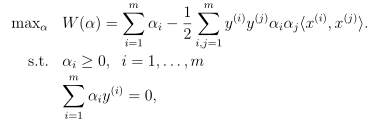
假设函数h(w,b)=g(wTx+b)为:

从而引出了核函数的重要概念,对于支持向量机的优化方法必不可少。
同时,在求解模型的过程中会遇到有离群值的干扰,需要对模型做出修正,提出软间隔的概念。
本节大纲:
- 核函数
- 软间隔
- SMO算法
一、核函数
1. 特征映射
问题的原始属性为x,x1,x2,在输入学习算法之前需要对它们进行一些处理,从而得到输入特征,假设Φ为原始属性到输入特征的特征映射(feature mapping):

2. 核函数
(1)基本定义
与之前的问题相关,当我们将原始属性<x,z>的内积换成输入特征<Φ(x),Φ(z)>的内积,就得到了核函数(kernel)的定义:

只要得到Φ(x),Φ(z),再计算它们的内积就可以很容易地得到核函数K(x,z),即使Φ(x)是一个高维向量,需要花费很大的计算代价,但是核函数的有效计算可以让支持向量机学习高维空间的特征。接下来举个例子具体体会一下。

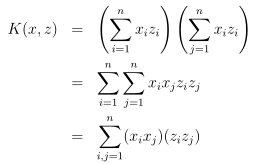
最终的结果就是核函数的定义。
特征映射Φ(x)为:

计算Φ(x)需要O(n2),而计算K(x,z)只需要O(n)。
(2)一般形式
考虑另外一个核函数的形式:

特征映射Φ(x)为:

参数c控制了xi与xiyi之间的相对权重。
更一般的核函数式子:
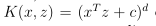
特征映射Φ(x)为 维,计算Φ(x)需要O(nd),计算K(x,z)仍只需要O(n),因此不需要明确地表示出在非常高维的特征空间中的特征向量。
维,计算Φ(x)需要O(nd),计算K(x,z)仍只需要O(n),因此不需要明确地表示出在非常高维的特征空间中的特征向量。
(3)高斯核
那么到底如何构造核函数呢?
下面考虑一个更为复杂的核函数,由于Φ(x)与Φ(z)是两个向量,如果当它们十分接近时,我们期望K(x,z)十分得大;当它们相距甚远时,我们期望K(x,z)很小。换句话说,就是来通过K(x,z)来衡量Φ(x)与Φ(z)之间的相似度或x与z之间的相似度。核函数可以采用以下的形式:
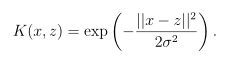
当x与z十分接近时,K(x,z)的值为1;当x与z相距甚远时,K(x,z)的值为0。这个核函数叫做高斯核(Gaussian kernel),它就是支持向量机所采用的核函数。
(4)核的合法性
接着,问题又来了,我们如何判断存在特征映射Φ,核函数对于所有的x与z都成立,即核函数的合法性?
假设K是核函数,同时K也是一个mXm的方阵,Kij=(K(i),K(j)),称为核矩阵(Kernel matrix)。如果核是有效的,K必须是对称矩阵,因为两个输入x,z的内积与两者的前后顺序无关。用Φ(x)表示Φ(x)的第k个值,于是有:

因此,K是半正定矩阵。也就是说,如果K是一个合法的核,那么它所对应的核矩阵是对称的半正定矩阵。事实上,这是一个充分必要条件,符合Mercer定理。

线性分类器对原始空间中并非线性可分离的数据进行分类,SVM输出非线性决策边界的整个过程,是一个求解凸优化问题的过程。许多其他算法可以写成内积的形式,就可以将内积换成核,将特征空间映射到无限维空间,以解决低维空间无法实现可分的情况。
二、L1 norm软边界SVM
支持向量机的算法有个前提条件是假设数据集是线性可分的,但是有时并不能保证所有情况下都线性可分或是得到满意的分离超平面。如下图所示,当存在一个较远的离群值(outliers)时,超平面出现了巨大的摆动,使得间隔(margin)较小。

为了满足非线性分类并减小离群值的影响,需要对最优间隔分类器算法进行修正(调整正则化的L1值):

通过将函数间隔值修正为1-ξi,增加目标函数的惩罚项Cξi,其中C控制目标函数||w||2最小和约束条件中的函数间隔最小值为1这两者之间的相对权重。
拉格朗日函数为:

它的对偶形式为:

注意到这里改变的约束条件仅是αi的取值范围,同时满足KKT互补条件。

L1 norm软边界SVM可以处理非线性分隔情形,包含异常数据的情况时,选择不进行完全正确的分隔来解决这个问题。现在还没解决的问题只剩下这个对偶问题的求解,下面引入几种解决思路。
三、序列最小优化算法(SMO)
1. 坐标上升法(Coordinate ascent)
考虑解决无约束最优问题:

联想到之前已经学习过的优化解法,如梯度上升法和牛顿法,现在来介绍一种新的方法——坐标上升法。

固定αi以外的所有参数,求解W(αi)函数的最优值,然后再依次分别固定其他参数,循环优化W(α),使得它的增长最大,α选择的一般顺序是α1,α2,...,αm,α1,α2,...。以下是一个含有两个参数的W(α)坐标上升法的优化过程,依次沿着坐标平行的方向取最大值。

当固定其他参数而求解某个参数的最优值时,坐标上升法收敛速度要好于牛顿法。
2. SMO(sequential minimal optimization)
回归L1 norm软边界SVM模型的求解问题,实际上是求出满足两个约束条件,同时使目标函数W(α)最大时的αi值,如果采用上升坐标法来解决这个问题,固定α2,...,αm的值,来求W(α)最大时α1的值,这是行不通的。
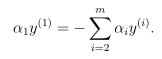

因为KKT条件约束的存在,当其他值确定时,α1的值也就固定了,它们之间是固定的相关关系,此时就无法来优化W(α)的值。改进的方法当然存在,只需要同时改变两个αi即可解决。基本步骤为:
- 使用试探法(heuristic)选择两个变量αi和αj用于更新值;
- 固定其他的α值,反复地利用αi和αj两个值来优化W(α);
- 重复以上步骤直到算法收敛,找到W(α)的全局最大值;
- 通过检验收敛容忍参数( convergence tolerance parameter)tol(0.01~0.001)是否满足KKT条件来判断是否收敛。
SMO算法之所以是个有效的算法,重点在于更新计算αi和αj的值十分快捷。
下面来推到出αi和αj的更新式子。由约束条件知:

可以转化为以下式子和示意图:


一定存在下限L和上限H使得α2满足[0,C],同理存在ξ(直线)使得α1满足[0,C],使它落在直线上或L上。通过α1与α2之间的关系可以减少参数的个数:

更新参数后,W(α)可以表达为α2的二次函数:

= 
通过选择合适的α2值优化二次函数就可以得到W(α)的最大值。

如果想了解更多关于试探法(heuristic)选择变量αi和αj的值和SMO算法运行时如何更新参数b,可以参阅John Platt的论文。
参考文献:
Sequential Minimal Optimization: A Fast Algorithm for Training Support Vector Machines

 浙公网安备 33010602011771号
浙公网安备 33010602011771号