MySQL架构篇
一、逻辑架构
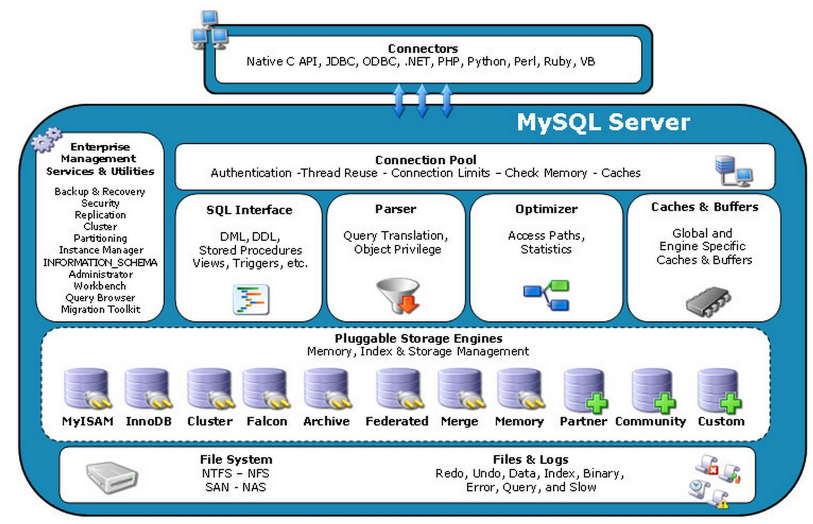
- Connectors:Mysql的客户端,
- Management Serveices & Utilities:系统管理和控制工具
- Connection Pool:连接池
- SQL Interface:DDL、DML语句对应的处理接口
- Parser:解析器,对SQL语句进行词法和语法分析,解析成语法树
- Optimizer:查询优化器,对SQL语句进行优化,explain语句查看的SQL语句执行计划,就是由查询优化器生成的
- Cache和Buffer:查询缓存。将查询结果缓存到内存中,当查询的表发生数据变化,与之相关的缓存均失效。由查询语句本身,查询的数据库,客户端协议等确定一个哈希值,通过哈希值引用查询结果
- Pluggable Storage Engines:存储引擎。InnoDB、MyISAM等等
- MyISAM:支持全文索引
- InnoDB:支持事务和行级锁定
- MyISAM压缩表:适用于创建并导入数据后,不再进行修改
- Memory:内存存储引擎,不需要磁盘I/O。适用于保存中间数据,临时表
- CSV:将普通的CSV文件作为Mysql表处理
二、环境说明
mysql版本:5.7.29
1. mysql文件结构
mysql通过文件系统对数据和索引进行存储,mysql文件分为日志文件和数据索引文件。mysql在linux系统中的索引文件和日志文件存放在/var/lib/mysql目录下,mysql默认配置文件位置在/etc/my.cnf
2.数据文件
- InnoDB数据文件
- .frm文件:表结构的定义
- .ibd:使用独享表空间存储表数据和索引信息,一张表对应一个ibd文件
- .ibdata文件:使用共享表空间存储表数据和索引信息,所有表使用一个或多个.ibdata文件
- MyIsam数据文件
- .frm文件:表结构的定义
- .myd文件:表数据信息
- .myi文件:表数据文件中的任何索引的数据树
- InnoDB数据文件
三、MySqlServer层对象
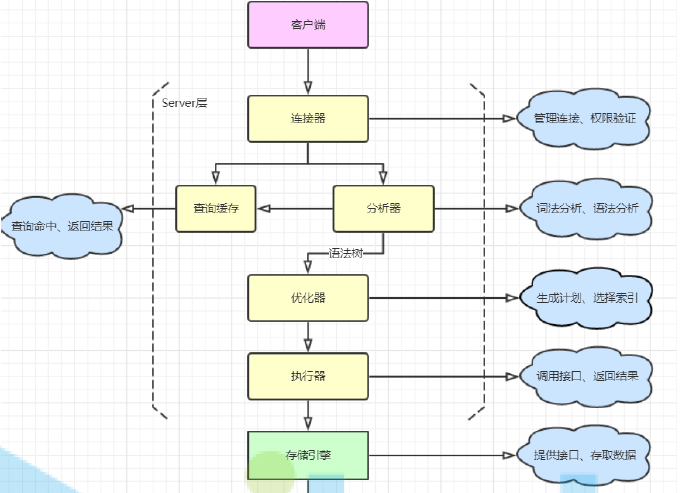
1. 连接器
连接器负责跟客户端建立和管理连接,验证权限。
2.分析器(做什么)
Parser解析器和Preprocessor预处理模块负责。对客户端的请求进行解析,提取查询条件、查询的表和字段等等,涉及词法、语法、语义分析
1. 词法分析:将SQL语句分隔成一个个字符串,识别出字符串代表的请求类型,表,列
2. 语法分析:
- 根据语法规则做检查,比如命令是否拼写错误,检查失败返回 You have an error in your SQL syntax to use near 第一个错误位置
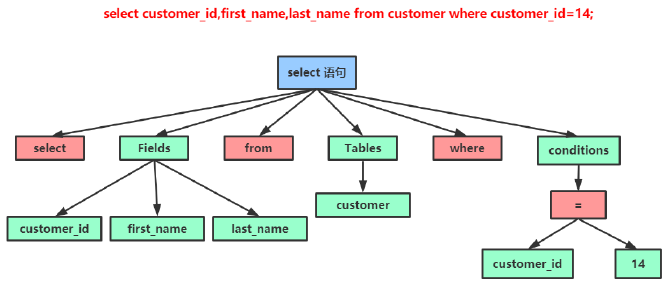
- 检查完毕,根据MySQL定义的语法规则,根据SQL生成一个解析树
![]()
- 预处理器进一步检查解析树是否合法,比如表名、列是否存在,用户是否有操作当前表的权限。检查完毕会生成新的解析树
3.查询缓存
如果开启了查询缓存,那么查询语句和结果将会一个key-value的形式存储,key是查询语句,查询的数据库和客户端协议hash之后的值,value是查询结果。如果在缓存中查询到结果,则直接返回。
查询的表一但被修改,则所有关于该表的查询缓存全部失效,失效缓存的操作会锁住缓存,阻塞其他查询命令。如果想使用查询缓存,要么是配置表(很少修改),要么是读写表分离。
在Mysql8中删除了查询缓存功能
4.查询优化器(怎么做)
根据解析树生成不同的计划,选择执行成本最小的计划。
- 当有多个索引可使用时,确定使用哪个索引
- 多表关联查询时,决定表的连接顺序,以哪个表为基表(小表驱动大表,关联查询可以看成嵌套遍历,当条件不满足时,内层遍历结束,开始外层下一轮遍历。当外层是小表时,期望遍历次数少)
5.执行器(开始做)
- 检查用户对表的执行权限 (关于执行器是否会检查权限,https://blog.csdn.net/weixin_44337261/article/details/89702446)
- 根据表定义的引擎,使用引擎提供的API操作数据库
四、InnoDB存储引擎
1.InnoDB架构图
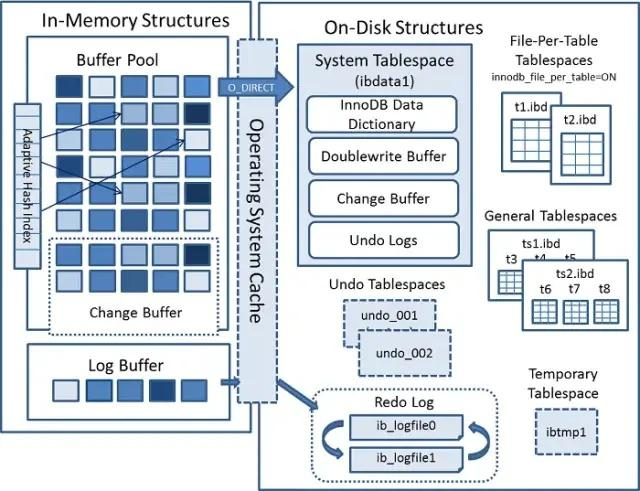
内存区域:
1. Buffer Pool:缓冲池。保存了从磁盘中读取的数据和索引。
2. Change Buffer:修改缓冲区。属于Buffer Pool的一部分,客户端对数据库的增删改操作结果的缓冲,等待写入磁盘。
3. Log Buffer:重做日志缓冲区。redo log缓冲区,保障数据写入磁盘。
磁盘区域:
1. System Tablespace:系统表空间。mysql安装目录下的ibdata1文件,包含了InnoDB数据字典(元数据和相关对象)、double write buffer、change buffer、undo logs的存储区域,也包含了用户在系统表空间创建的表数据和索引数据
2. File-Per-Table Tablespaces:用户表空间。开启了innodb_file_per_table=ON,为每个innoDB用户表创建独立的表空间,表名.ibd文件。用户表空间存放该表的叶子节点,非叶子节点和插入缓冲BITMAP等信息,其余信息仍存放于系统表空间。
3. Undo Tablespaces:回滚表空间。
4. Redo Log:重做日志。mysql安装目录下的ib_logfile0和ib_logfile1文件。Log Buffer中的数据即循环覆盖写入到两个文件,文件默认大小50M。
5. Temporary Tablespace:临时表空间。
2. InnoDB磁盘文件
InnoDB逻辑存储结构分为五级:表空间、段、区、页、行。
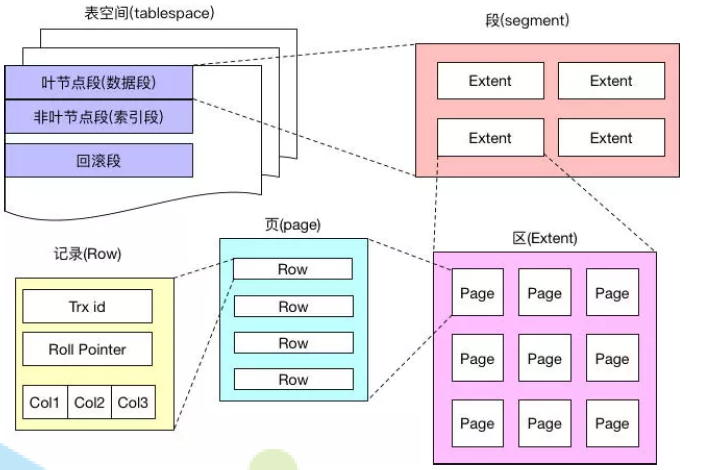
区:由64个页组成,每个页大小16K,一个区大小为1M。为了保证区中页的连续性,扩展时会一次性申请4~5个区
页:磁盘和内存交互的最小单位。一页代表索引树上的一个节点。MySQL规定一个页最少存储2个数据项。当一个页已满时,向节点尾部插入数据,新的数据会分配到区中的新页中。向节点的中间插入数据,会导致页分裂成两个新页。
操作系统读写磁盘的最小单位也是页,在Linux中,一个页大小为4K,当InnoDB读取一个数据页(一个节点)时,操作系统会分4次从磁盘中读取数据到内存,写入一个数据页也需要分4次从内存写入到硬盘。
行:每行代表一条数据。在MySQL5.7种,行的存储格式由4种,默认为Dynamic
3. InnoDB内存结构
3.1 Buffer pool缓冲池
-
- 数据页:读取查找结果所在页和相邻页,添加到缓冲区
- 索引页:将可能使用的索引页加载到缓冲区。
- 修改缓冲区:存入用户修改(插入/更新/删除)的数据,等待写入磁盘
- 自适应哈希索引:InnoDB自动对热点页建立哈希索引,哈希码根据每行数据的所有索引列计算得出。要求必须是精确查询,并且此语句执行了很多次。
- 锁信息:
- 数据字典:表的元信息的缓存,当InnoDB打开一个表即增加一个对应的对象到数据字典。包括表结构、数据库名、表名、字段的数据类型、视图、索引、表字段信息、存储过程、触发器等等。
3.2 额外内存池
用于存放数据字典和一些内部数据结构。在5.7.4中移除
3.3 重做日志缓冲(保障更新数据不丢失)
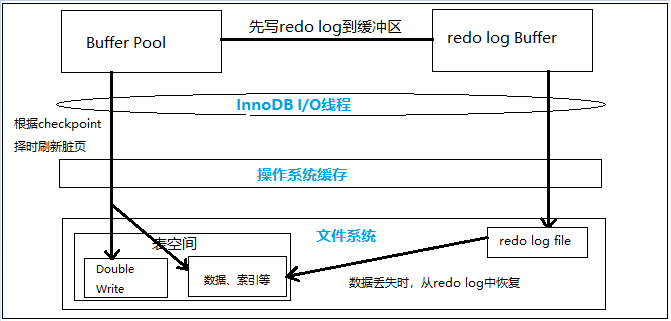
对修改缓冲区的修改会同步到redo log buffer中,在事务提交前
1. 会将redo log buffer中的这部分数据写入到操作系统缓存(跟innodb_flush_log_at_trx_commit配置项有关)。
2. 将修改缓冲区中的内容同步到缓冲池中的数据页,这些数据页变成 “脏页” 。后续checkpoint会将这部分内容刷新到磁盘。
同样是写入磁盘,写入redo log file文件是顺序写,新的记录追加在旧记录之后。而写入表空间的数据页和索引页是随机写,磁头移动,有寻道时间,耗时更高。
3.3 CheckPoint检查点机制(脏页落盘)
择时将脏页落盘。
3.3.1 sharp checkpoint
在数据库关闭时,将缓冲池中的脏页全部写入磁盘。
3.3.2 fuzzy checkpoint
在运行期间,将部分脏页落盘
1. Master Thread checkpoint:Master Thread执行。 每秒/每10秒一次将部分脏页落盘
2. FLUSH_LRU_LIST checkpoint:page cleaner Thread执行。 将被LRU淘汰的脏页落盘
3. Async/Sync Flush checkpoint:page cleaner Thread执行(MySQL 5.6版本,不会阻塞用户线程)。
redo log file 文件循环写入的,当写入时发现即将覆盖的那部分内容对应的脏页尚未落盘,此时称为重做日志不可用。
这种情况,会将脏页列表中的部分脏页落盘,使重做日志可用。在5.6版本之前,Async Flush会阻塞发现重做日志不可用的用户线程,Sync Flush会阻塞所有用户线程。
4. Dirty Page too much Checkpoint:当缓冲池中的脏页占比达到阈值(innodb_max_dirty_pages_pct设定),会将部分脏页落盘
3.5 双写缓冲区(脏页落盘细节、保障数据页的一致性)
解决问题:将InnoDB内存的一个脏数据页写入磁盘,需要4次写入(Linux),当操作过程发生不可逆故障,会导致数据页发生断裂,导致数据不一致。为何不能从redo log file中恢复?当页面损坏时,已经找不到当前页最后的事务号,无法恢复。
解决思路:在将脏页刷新到磁盘时,会将该页写入到内存中的双写缓冲区(大小2M,即两个区,128个页)。然后,先写入到共享表空间的双写缓冲区(大小2M,每次写1M),再写入到对应的用户表空间。
如果在写入用户表空间发生故障,可以从共享表空间的双写缓冲区恢复损坏的数据页。
如果在写入共享表空间发生故障,也不会影响用户表空间数据的一致性。这部分没写入的数据可以从redo log file中恢复。
性能问题:写入共享表空间的双写缓冲区是顺序写,速度快。
3.6 重做日志缓冲区
事务提交前,将变更写入重做日志缓冲区,由innodb_flush_log_at_trx_commit配置决定重做日志缓冲区中的内容何时写入到操作系统的缓冲区,以及何时写入到磁盘。默认设置为1
-
- 设置为0,每秒一次,将缓冲区的内容写入操作系统缓存,并且同步到磁盘
- 设置为1,在事务提交前,将缓冲区内容写入操作系统缓存,并且同步到磁盘
- 设置为2,在事务提交前,将缓冲区内容写入操作系统缓存,何时同步磁盘由文件系统决定
附录
1. InnoDB的共享表空间和独立表空间
共享表空间:
优点:表可以拆成多个文件存放在不同磁盘上,不受单个文件大小限制,最大64T。
缺点:空间分配后不能回缩,临时表或临时索引占用的空间无法回缩。类似的删除数据的空间碎片也无法回收,所以不适合建立大量删除的表。
独立表空间:
优点:每个表有独立的文件,可以实现不同数据库移动。空间可回收,删除数据后使用 alter table TableName engine=innodb,整理空间碎片。
缺点:表用一个文件存放,存在大小限制
参考:https://blog.csdn.net/chenjiayi_yun/article/details/45716933

 浙公网安备 33010602011771号
浙公网安备 33010602011771号