
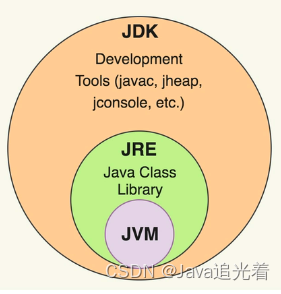
java基础
JDK/JRE/JVM的区别和联系
https://blog.csdn.net/epitomizelu/article/details/138667865
==和equals的区别
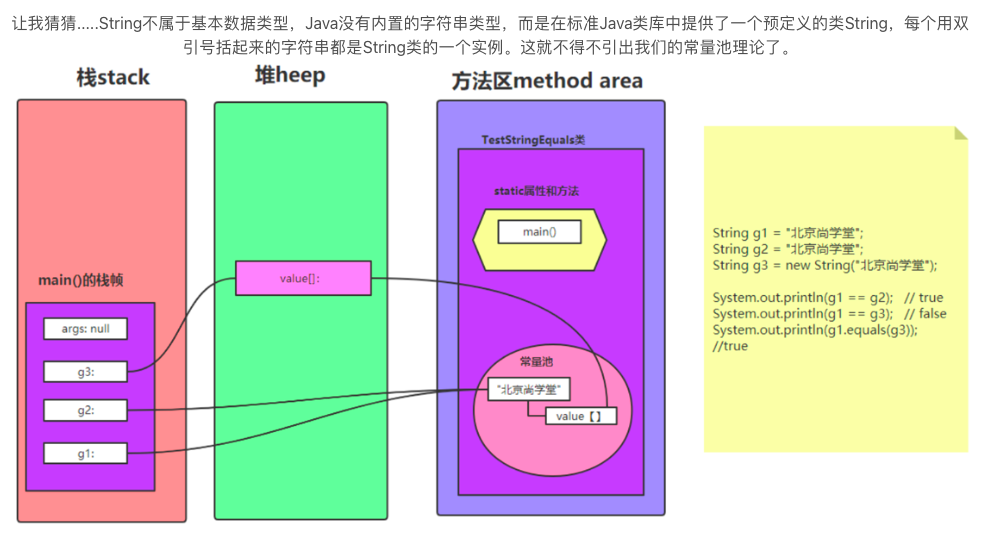
1、== 运算符:主要用于比较两个变量的值是否相等。但是,这个“值”的含义取决于变量的类型:
- 对于基本数据类型(如int, char, boolean等):== 比较的是两个变量的值是否相等。
- 对于引用类型(如对象、数组等):== 比较的是两个引用是否指向内存中的同一个对象(即地址是否相同)。
示例:
![image]()

2、equals()方法:Java Object 类的一个方法,用于比较两个对象的内容是否相等。
需要注意的是,默认的 equals() 方法 实现其实就是 == 操作符对于引用类型的比较,即比较的是两个引用是否指向同一个对象。
但是,很多Java类(如String, Integer等)都重写了 equals() 方法,以提供基于内容的比较。
示例:

3、总结
- ==运算符:
对于基本数据类型,比较的是值是否相等。
对于引用类型,比较的是两个引用是否指向同一个对象(即地址是否相同)。 - equals()方法:
默认实现是基于 == 操作符的,即比较两个引用是否指向同一个对象。
但很多类(如String, Integer等)都重写了 equals() 方法,以提供基于内容的比较。
4、重要提示:
- 当比较两个对象的内容是否相等时,应该优先使用 equals() 方法,而不是 == 操作符。
- 自定义类如果需要比较内容是否相等,也应该重写 equals() 方法。
- 需要注意的是,如果重写了 equals() 方法,通常也需要重写 hashCode() 方法,以保持两者的一致性。这是因为在Java中,很多集合类(如HashSet, HashMap等)在存储和查找元素时,都会同时用到 equals() 和 hashCode() 方法。
5、何时使用“==”和“equals”,下面是一些使用建议:
- 如果我们需要比较基本数据类型的值或对象的引用,那么我们应该使用"=="。例如,比较两个int类型的值或比较两个对象的引用。
- 如果我们需要比较对象的值是否相等,那么我们应该使用equals。例如,比较两个字符串对象或比较两个自定义对象。
- 如果我们需要比较对象的引用是否相等,而不是它们的值,那么我们应该使用"=="。例如,比较两个对象是否指向同一个内存地址。
- 如果我们需要将对象作为键值存储在Map中,那么我们应该重写对象的equals和hashCode方法。这是因为在使用Map时,需要使用equals方法来比较对象的值是否相等,并使用hashCode方法来计算对象的哈希值。
- 在使用== 和equals时,还需要注意一些特殊情况。例如,在比较两个null值时,"=="比较的结果为true,而equals比较的结果为false。这是因为在Java中,null表示一个空对象引用,它不指向任何对象,因此两个null值的引用是相等的。但是由于null不是一个对象,所以它没有任何值,因此两个null值的值是不相等的。
- 另外,在比较字符串时,我们应该使用equals方法而不是 == 运算符。虽然字符串是对象,但Java中的字符串常量池会自动缓存字符串对象。因此,如果我们使用 == 比较两个字符串常量,那么它们的引用可能相等,但是如果我们使用"=="比较一个字符串常量和一个字符串对象,那么它们的引用肯定不相等。
String、 StringBuilder、 StringBuffer的区别
结论:
- String是不可变的,如果尝试去修改,会新生成一个字符串对象,StringBuffer和StringBuilder是可变的
- StringBuffer是线程安全的,StringBuilder是线程不安全的,所以在单线程环境下StringBuilder效率会更高
解释:
- String:字符串是不可变的,每次使用 + 或其他操作修改字符串时,实际上都是创建了一个新的字符串。这意味着如果你在循环中连接字符串,会产生性能问题。
String s = "Hello";
s += " World"; // 创建了一个新的字符串
- StringBuilder:当你需要在单线程环境中构造可变字符串时,应该使用 StringBuilder。它是可变的,并且进行字符串操作时不会创建新的对象。
StringBuilder sb = new StringBuilder("Hello");
sb.append(" World"); // 直接在原有StringBuilder对象上修改
- StringBuffer:StringBuffer 是 StringBuilder 的线程安全版本,它在多线程环境下使用。与 StringBuilder 相比,StringBuffer 的大多数操作都是线程安全的,但是性能稍微慢一些。
StringBuffer sb = new StringBuffer("Hello");
sb.append(" World"); // 直接在原有StringBuffer对象上修改
在选择使用哪个类时,需要考虑以下因素:
如果不涉及多线程,请使用 StringBuilder。
如果涉及多线程,请使用 StringBuffer。
如果你需要创建一个字符串并进行少量修改,使用 String。
重写和重载的区别
- 重载: 发生在同一个类中,方法名必须相同,参数类型不同、个数不同、顺序不同,方法返回值和访问修饰符可以不同。发生在编译时
- 重写:发生在父子类中,方法名、参数列表必须相同,返回值范围小于等于父类,抛出的异常范围小于等于父类,访问修饰符范围大于等于父类;如果父类方法访问修饰符为私有,则子类就不能重写该方法。发生在运行时
解释:
- 重载(Overloading):定义:在同一个类中,方法名相同但参数列表不同。实现:通过不同的参数类型和数量实现编译时多态性。应用:适用于处理相似功能但不同输入的情况。
- 重写(Overriding):定义:子类中重新定义父类方法,方法名、参数列表和返回类型相同。实现:通过继承实现运行时多态性。应用:用于子类扩展或修改父类行为,常见于框架和库设计。
List和Set的区别

ArrayList和LinkedList的区别
- ArrayList 是基于动态数组的数据结构,LinkedList 基于双向链表的数据结构。
- 对于随机访问 get 和 set,ArrayList 优于 LinkedList,因为 LinkedList 要移动指针。
- 对于新增和删除操作 add 和 remove,LinkedList 比较占优势,因为 ArrayList 要移动数据。
- ArrayList底层是动态数组,存在扩容说法,默认的数组大小是10,在检测是否需要扩容后,如果扩容,会扩容为原来的1.5倍大小。原理就是把老数组的元素存储到新数组里面;LinkedList不存在扩容 的说法,因为是链表结构。
HashMap和HashTable有什么区别?其底层实现是什么?
解释:
在 ArrayList 的中间插入或删除一个元素这个列表中剩余的元素都会被移动,而在 LinkedList 的中间插入或删除一个元素的花费是固定的。
ArrayList 和 LinkedList 的使用:
- 当操作是在一列数据的后面添加数据而不是在前面或中间 , 并且需要随机地访问其中的元素时,使用 ArrayList 会提供比较好的性能;
- 当需要在一列数据的前面或中间添加或删除数据 , 并且按照顺序访问其中的元素时,就应该使用 LinkedList 了。
HashMap和HashTable有什么区别?其底层实现是什么?
区别:
- HashMap方法没有synchronized修饰,线程非安全,HashTable线程安全;
- HashMap允许key和value为null,而HashTable不允许
底层实现:
在JDK 1.8以后,
- HashMap的底层数据结构改成了数组+链表+红黑树的实现。当链表的节点大于TREEIFY_THRESHOLD=8时,链表转为红黑树;在树节点小于UNTREEIFY_THRESHOLD=6时,红黑树转变为链表。
- Hashtable的底层实现是数组+链表,没有红黑树,因此各种操作都要简单很多
深拷贝和浅拷贝
深拷贝和浅拷贝就是指对象的拷贝,一个对象中存在两种类型的属性,一种是基本数据类型,一种是实例对象的引用。
- 浅拷贝是指,只会拷贝基本数据类型的值,以及实例对象的引用地址,并不会复制一份引用地址所指向的对象,也就是浅拷贝出来的对象,内部的类属性指向的是同一个对象
- 深拷贝是指,既会拷贝基本数据类型的值,也会针对实例对象的引用地址所指向的对象进行复制,深拷贝出来的对象,内部的类属性指向的不是同一个对象
解释
在讨论深浅拷贝之前,我们先说说数据类型,因为深浅拷贝与数据类型有关。
数据类型分为基本数据类型(String、Number、Boolean、Null、Undefined、Symbol (es6引入的一种类型) )和引用数据类型(Object、Array、Function)。
基本数据类型特点:直接存储在栈中;
引用数据类型:它真实的数据是存储在堆内存中,栈中存储的只是指针,指向在堆中的实体地址。
加深理解:https://blog.csdn.net/weixin_57959921/article/details/129439092
Java中的异常体系是怎样的
- Java中的所有异常都来自顶级父类Throwable。
- Throwable下有两个子类Exception和Error。
- Error是程序无法处理的错误,一旦出现这个错误,则程序将被迫停止运行。
- Exception不会导致程序停止,又分为两个部分RunTimeException运行时异常和CheckedException检查异常。
- RunTimeException常常发生在程序运行过程中,会导致程序当前线程执行失败。
- CheckedException常常发生在程序编译过程中,会导致程序编译不通过。
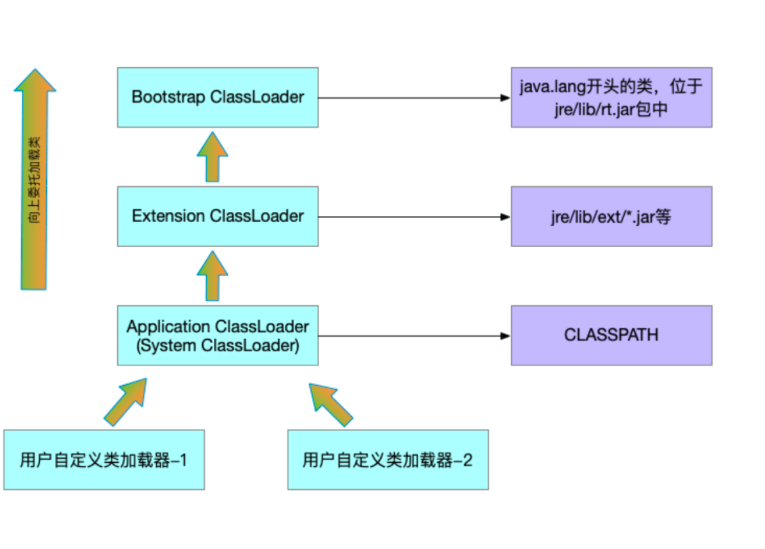
Java中有哪些类加载器
Java类加载器(Class Loader)是Java运行时环境的一部分,负责动态加载Java类到Java虚拟机(JVM)中。Java类加载器主要有以下几种类型:
- 启动类加载器(Bootstrap Classloader)
这个类加载器负责加载java核心类库,JRE/lib/rt.jar中的类。由于Java中的核心API是由JRE自带的,所以我们可以在任何时候使用这个类加载器。 - 扩展类加载器(Extension Classloader)
这个类加载器负责加载JRE扩展目录(jre/lib/ext目录)中的JAR包。这个目录一般都是存放一些扩展API的类,如JDBC驱动程序等,它的加载优先级要高于系统类加载器,但低于引导类加载器。 - 系统类加载器(System Classloader)
也称为应用类加载器,负责加载应用程序的classpath中指定的类。一般来说,这个类加载器是我们最常用的,比较常见的一种类加载器。 - 自定义类加载器(Custom Classloader)
在Java中,我们可以通过继承ClassLoader类来自定义类加载器,这样我们就可以实现自己的类加载方式。
Java类加载器双亲委派模型
双亲委派机制(Parent-Delegate Model)是Java类加载器中采用的一种类加载策略。
该机制的核心思想是:如果一个类加载器收到了类加载请求,默认先将该请求委托给其父类加载器处理。只有当父级加载器无法加载该类时,才会尝试自行加载。
GC 如何判断对象可以被回收
在 Java 中,垃圾回收(Garbage Collection, GC)机制负责自动管理内存,回收不再使用的对象。判断对象是否可以被回收是垃圾回收器的任务。主要有两种算法用于判断对象是否可以被回收:引用计数法(Reference Counting)和可达性分析法(Reachability Analysis)。
- 引用计数法(Reference Counting)
引用计数法是一种简单的垃圾回收技术。每个对象都有一个引用计数,当有一个新的引用指向该对象时,引用计数加一;当一个引用被销毁或指向其它对象时,引用计数减一。当一个对象的引用计数为零时,表示该对象不再被引用,可以被回收。
局限性:
循环引用问题:引用计数法无法处理循环引用的对象(例如,两个对象相互引用对方,导致它们的引用计数永远不为零,即使它们没有被程序中的任何其他对象引用)。
- 可达性分析法(Reachability Analysis)
现代 JVM 使用的是可达性分析方法来判断对象是否可以被回收。可达性分析通过一组称为 GC Roots 的对象作为起点,沿着这些对象的引用路径进行搜索。如果某个对象不可从 GC Roots 达到,那么它被认为是不可达的,可以被回收。
GC Roots的对象有:
- 虚拟机栈(栈帧中的本地变量表)中引用的对象
- 方法区中类静态属性引用的对象
- 方法区中常量引用的对象
- 本地方法栈中JNI(即一般说的Native方法)引用的对象

 浙公网安备 33010602011771号
浙公网安备 33010602011771号