InnoDB的行溢出数据,Char的行结构存储
行溢出数据
InnoDB存储引擎可以将一条记录中的某些数据存储在真正的数据页面之外,即作为行溢出数据。一般认为BLOB、LOB这类的大对象列类型的存储会把数据存放在数据页面之外。但是,这个理解有点偏差,BLOB可以不将数据放在溢出页面,而即使是varchar列数据类型,依然有可能存放为行溢出数据。
varchar(n) 65535的详解
我们先来对varchar类型进行研究。很多DBA喜欢MySQL的VARCHAR类型,因为相对于Oracle VARCHAR2最大存放4000个字节,SQL Server最大存放的8000个字节,MySQL的VARCHAR数据类型可以存放65 535个字节。但是,这是真的吗?真的可以存放65 535个字节吗?
如果创建varchar长度为65 535的表,我们会得到下面所示的出错信息:
create table test (a varchar(65535)) charset=latin1 engine=innodb;
ERROR 1118(42000):Row size too large.The maximum row size for the used table
type,not counting BLOBs,is 65535.You have to change some columns to TEXT or BLOBs
从出错消息可以看到,InnoDB存储引擎并不支持65 535长度的varchar。这是因为还有别的开销,因此实际能存放的长度为65 532。
下面的表创建就不会报错了:
create table test (a varchar(65532)) charset=latin1 engine=innodb;
Query OK,0 rows affected(0.15 sec)
需要注意的是,如果在做上述例子的时候并没有将sql_mode设为严格模式,则可能会出现可以建立表,但是会有一条警告信息:
create table test (a varchar(65535)) charset=latin1 engine=innodb;
Query OK,0 rows affected,1 warning(0.14 sec)
show warnings\G
***************************1.row***************************
Level:Note
Code:1246
Message:Converting column'a'from VARCHAR to TEXT
1 row in set(0.00 sec)
警告信息提示了,之所以这次可以创建,是因为MySQL自动将VARCHAR转换成了TEXT类型。如果我们看test的表结构,会发现MySQL自动将VARCHAR类型转换为了MEDIUMTEX类型:
show create table test\G
***************************1.row***************************
Table:test
Create Table:CREATE TABLE 'test' (
'a'mediumtext
)ENGINE=InnoDB DEFAULT CHARSET=utf8
1 row in set(0.00 sec)
还需要注意的是,上述创建VARCHAR长度为65 532的表其字符类型是latin1的。
如果换成GBK或者UTF-8,又会产生怎样的结果呢?
create table test (a varchar(65532)) charset=gbk engine=innodb;
ERROR 1074(42000):Column length too big for column 'a'(max=32767);use BLOB
or TEXT instead
create table test (a varchar(65532)) charset=utf8 engine=innodb;
ERROR 1074(42000):Column length too big for column'a'(max=21845);use BLOB
or TEXT instead
这次即使创建列的VARCHAR长度为65 532也会报错,但是两次报错中对于max值的提示是不同的。因此我们应该理解VARCHAR(N)中,N指的是字符的长度,VARCHAR类型最大支持65 535指的是65 535个字节。
此外,MySQL官方手册中定义的65 535长度是指所有VARCHAR列的长度总和,如果列的长度总和超出这个长度,依然无法创建,如下所示:
create table test2 (a varchar(22000),b varchar (22000),c varchar (22000)) charset=latin1 engine=innodb;
ERROR 1118(42000):Row size too large.The maximum row size for the used table
type,not counting BLOBs,is 65535.You have to change some columns to TEXT or BLOBs
3个列长度总和是66 000,因此InnoDB存储引擎再次报了同样的错误。
溢出数据的存储
即使我们能存放65 532个字节了,但是有没有想过,InnoDB存储引擎的页为16KB,即16 384个字节,怎么能存放65 532个字节呢?一般情况下,数据都是存放在B-tree Node的页类型中,但是当发生行溢处时,则这个存放行溢处的页类型为Uncompress BLOB Page。
我们来看个例子:
create table t (a varchar (65532));
insert into t select repeat ('a',65532);
这里创建了拥有一个长度为65 532的varchar类型表,
接着用py_innodb_page_info工具看下面的表空间文件,看看页的类型有哪些。可以看到一个B-tree Node页类型,另外有4个为Uncompressed BLOB Page,这些页中才是真正存放了65 532个字节的数据。既然实际存放的数据都放到BLOB页中,那数据页中又存放了些什么东西呢?同样,通过之前的hexdump来读取表空间文件,可以看到,从0x0000c093到0x0000c392数据页面其实只保存了varchar(65 532)的前768个字节的前缀(prefix)数据(这里都是a),之后跟的是偏移量,指向行溢出页,也就是前面我们看到的Uncompressed BLOB Page。因此,对于行溢出数据,其存放方式下图4所示:
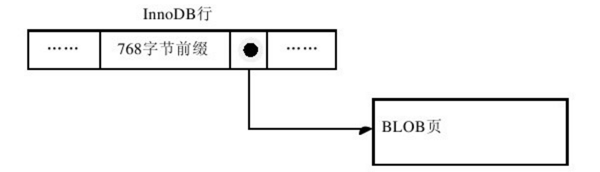
那多少长度VARCHAR是保存在数据页里的,多少长度开始又保存在BLOB页呢?我们来思考一下,InnoDB存储引擎表是索引组织的,即B+树的结构。因此每个页中至少应该有两个行记录(否则失去了B+树的意义,变成链表了)。因此如果当页中只能存放下一条记录,那么InnoDB存储引擎会自动将行数据存放到溢出页中。考虑下面表的一种情况:
create table t (a varchar (9000));
insert into t select repeat ('a',9000);
表t的变长字段长度为9000,能放在一个页中,但是不能保证2条记录都能存放在一个页中,所以此时如果用py_innodb_page_info工具查看,可知是存放在BLOB页中。
如果可以在一个页中至少放入两行的数据,那varchar就不会存放到BLOB页中。经过试验我发现,这个阈值的长度为8098。如我们建立列为varchar(8098)的表,然后插入两条记录:
create table t (a varchar (8098));
insert into t select repeat ('a',8098);
insert into t select repeat ('a',8098);
接着用py_innodb_page_info工具对表空间t.ibd进行查看,可以发现此时的行记录都是存放在数据页中,而不是BLOB页了。如果熟悉Microsoft SQL Server数据库的DBA,可能会感觉InnoDB存储引擎对于varchar的管理和SQL Server中的VARCHAR(MAX)类似。
对于溢出行的管理,同样是采用段的方式,即InnoDB存储引擎同Oracle一样有BLOB行溢出段。另一个问题是,对于TEXT或者BLOB的数据类型,我们总是以为它们是放在Uncompressed BLOB Page中的,其实这也是不准确的,放在数据页还是BLOB页同样和前面讨论的VARCHAR一样,至少保证一个页能存放两条记录,如:
create table t (a blob);
insert into t select repeat ('a',8000);
insert into t select repeat ('a',8000);
insert into t select repeat ('a',8000);
insert into t select repeat ('a',8000);
我们建立一个BLOB列的表,插入4行数据长度为8000的记录,如果用py_innodb_page_info工具对表空间t.ibd进行查看,会发现这些记录其实并没有保存在BLOB页中。当然,既然我们使用了BLOB列类型,一般情况下我们不可能存放长度这么小的数据,因此对于大多数的情况,BLOB的行数据还是会发生行溢出,实际数据保存在BLOB页中,数据页只保存数据的前768个字节。
Char的行结构存储
通常的理解VARCHAR是存储变长长度的字符类型,CHAR是存储定长长度的字符类型。从MySQL 4.1开始,CHR(N)中的N指的是字符的长度,而不是之前版本的字节长度。那也就是说,在不同的字符集下,CHAR的内部存储的不是定长的数据。
我们来看下面的这个情况:
create table j (a char(2)) charset=gbk;
insert into j select 'ab';
set names gbk;
insert into j select '我们';
insert into j select 'a';
j表的字符集是GBK的,我们分别插入了两个字符的数据'ab'和'我们',查看所占字节可得如下结果:
select a, char_length(a),length(a) from j\G;
***************************1.row***************************
a:ab
char_length(a):2
length(a):2
***************************2.row***************************
a:我们
char_length(a):2
length(a):4
通过不同的字符串长度函数可以看到,前两个记录'ab'和'我们'字符串的长度都是2,但是内部存储上'ab'占用两个字节,而'我们'占用4个字节。
如果看内部十六进制的存储,可以看到:select a,hex(a) from j\G;
***************************1.row***************************
a:ab
hex(a):6162
***************************2.row***************************
a:我们
hex(a):CED2C3C7
对于字符串'ab'的存储内部为0x6162,而'我们'是0xCED2C3C7,这就可以很明显地看出区别了。因此对于多字节的字符编码CHAR类型,不再代表是固定长度的字符串了,比如UTF-8下CHAR(10)最小可以存储10个字节的字符,而最大可以存储30个字节的字符。所以,对于多字节字符编码的CHAR数据类型的存储,InnoDB存储引擎在内部将其视为是变长的字符,这就表示了,在每行变长长度列表中会记录CHAR数据类型的长度。通过hexdump工具我们来看j.ibd文件的内部:
0000c070 73 75 70 72 65 6d 75 6d 02 00 00 00 10 00 1c 00|supremum…… 0000c080 00 00 b6 2b 2b 00 00 00 51 52 da 80 00 00 00 2d|……++……QR……- 0000c090 01 10 61 62 04 00 00 00 18 ff d5 00 00 00 b6 2b|..ab……+ 0000c0a0 2c 00 00 00 51 52 db 80 00 00 00 2d 01 10 ce d2|,……QR……-…… 0000c0b0 c3 c7 00 00 00 00 00 00 00 00 00 00 00 00 00 00|…… 整理后可以得到如下结果: #第一行记录 02/*变长字段长度2,char视作变长类型*/ 00/*NULL标志位*/ 00 00 10 00 1c/*记录头信息*/ 00 00 00 b6 2b 2b/*RowID*/ 00 00 00 51 52 da/*TransactionID*/ 80 00 00 00 2d 01 10/*Roll Point*/ 61 62/*字符'ab'*/ #第二行记录 04/*变长字段长度4,char视作变长类型*/ 00/*NULL标志位*/ 00 00 18 ff d5/*记录头信息*/ 00 00 00 b6 2b 2c/*RowID*/ 00 00 00 51 52 db/*TransactionID*/ 80 00 00 00 2d 01 10/*Roll Point*/ c3 d2 c3 c7/*字符'我们'*/ #第三行记录 02/*变长字段长度2,char视作变长类型*/ 00/*NULL标志位*/ 00 00 20 ff b7/*记录头信息*/ 00 00 00 b6 2b 2d/*RowID*/ 00 00 00 51 53 17/*TransactionID*/ 80 00 00 00 2d 01 10/*Roll Point*/ 61 20/*字符'a'*/
在InnoDB存储引擎内部对于CHAR类型在多字节字符集类型的存储了,CHAR很明确地被视为了变长类型,对于未能占满长度的字符还是填充0x20。内部对于字符的存储和我们用hex函数看到的也是一致的。我们可以说,在多字节字符集的情况下,CHAR和VARCHAR的行存储基本是没有区别的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号